RedisModule剖析 - RedisTimeSeries
RedisTimeSeries 是一款基于 RedisModule 实现的时序数据库模块,提供了基础的时序操作功能,包括不限于聚合查询,范围查询,保留周期,降采样(数据压缩),插值变更,二级索引等。由于数据存储于内存中,因此提供了高性能读写访问能力,但同时也受限于内存存储,可能并不适合用在极大数据量的时序场景中。考虑到身靠着Redis生态这棵大树,也许能够和Redis生态的众多组件碰撞出有趣的火花。
一、简介
- 官网:https://redis.io/docs/stack/timeseries/
- GitHub 地址:https://github.com/RedisTimeSeries/RedisTimeSeries
- 命令文档地址:https://redis.io/commands/ts.add/
- 支持功能:
- 大容量插入,低延迟读取;
- 按开始时间和结束时间查询;
- 任何时间桶的聚合查询( Min 、 Max 、 Avg 、 Sum 、 Range 、 Count 、 First 、 Last 、 STD.P 、 STD.S 、 Var.P 、 Var.S 、 twa );
- 可配置的最长保留期;
- 压缩 - 自动更新的聚合时间序列;
- 二级索引 - 每个时间序列都有标签(名称-值对),允许按标签查询;
二、架构设计
2.1、基础概念
sample:样本数据,一个样本数据包含一个样本时间(int64)和一个样本值(double);chunk:每个chunk中会存储一批的样本数据(连续时间戳的样本数据),随着数据的写入,一个时序类型中会包含多个chunk;非压缩模式:chunk使用数组来存储样本(插值的时候会进行数组的移动);压缩模式:chunk使用Delta-Of-Delta和XOR压缩编码存储数据(插值的时候会进行chunk拆分);
label:标签,会依据标签创建二次索引,以便于快速查询到指定标签的key的信息;rule:数据聚集的规则,在插入样本的时候会按照指定的规则将数据聚合到特定的key中,用于支持数据的降采样;
2.2、相关命令
- ts.create : 创建一个新的时间序列;
- ts.createrule : 创建一个新的时间序列压缩规则;
- ts.add : 添加一个时间样本到对应的时间序列中;
- ts.madd : 添加一个或多个时间样本到对应的时间序列中;
- ts.get : 从时间序列中获取最新的一个时间样本数据;
- ts.mget : 从符合条件的多个时间序列中获取最新的一个时间样本数据;
- ts.alter : 更新现有时间序列的保留时间、块大小、时间样本重复策略以及标签信息;
- ts.incrby : 更新指定时间序列中最新的时间样本的值,如果不存在则新增对应时间样本;
- ts.decrby : 更新指定时间序列中最新的时间样本的值,如果不存在则新增对应时间样本;
- ts.del : 删除指定范围内的时间序列中的时间样本数据;
- ts.deleterule : 删除一个时间序列压缩规则;
- ts.range : 从一个时间序列中查询范围区间的时间样本数据,按照时间戳从老到新查询;
- ts.revrange : 从一个时间序列中查询范围区间的时间样本数据,按照时间戳从新到老查询;
- ts.mrange : 从符合条件的多个时间序列中查询指定时间区间的时间样本数据,按照时间戳从老到新查询;
- ts.mrevrange : 从符合条件的多个时间序列中查询指定时间区间的时间样本数据,按照时间戳从新到老查询;
- ts.queryindex : 查询所有符合条件的时间序列的信息;
- ts.info : 查询指定时间序列的信息;
2.3、数据结构
2.3.1、时序主体数据结构
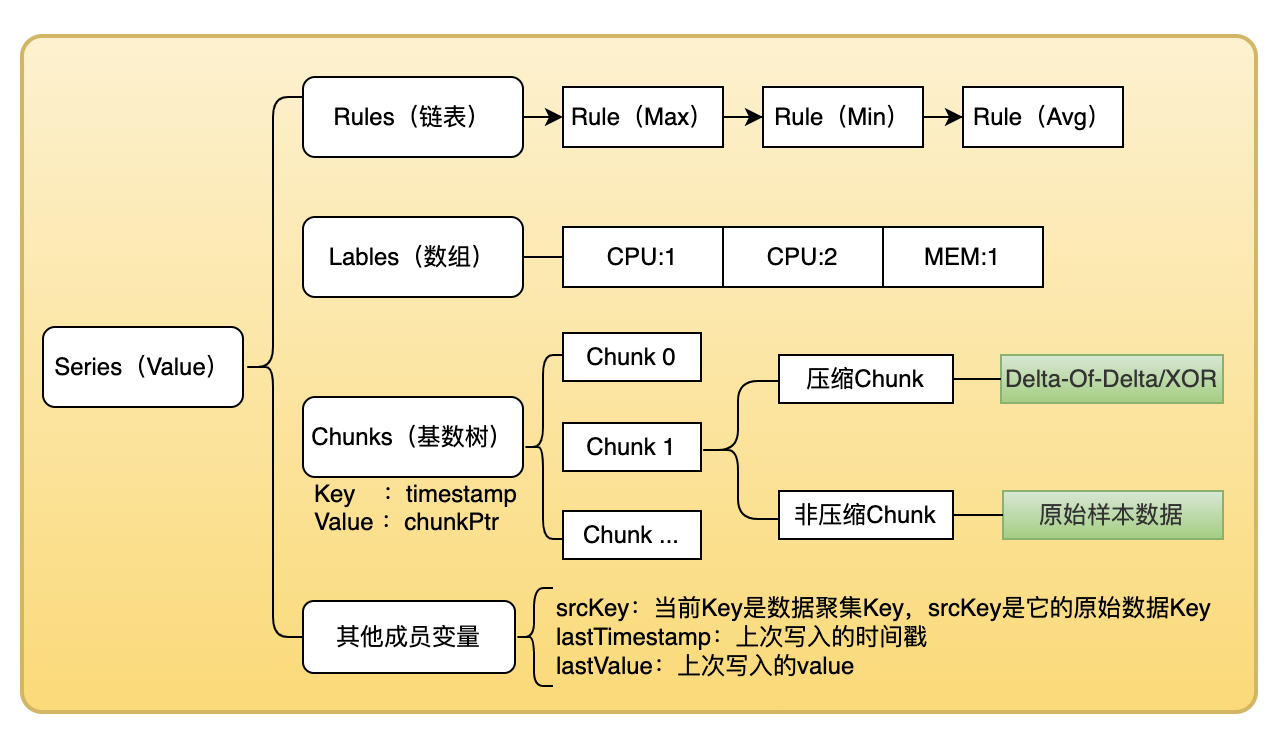
一个时间序列数据的存储结构主要由以下几个部分组成:
Rules:- 含义 : 时间序列的数据压缩规则,记录了当前时间序列数据的所有的数据压缩规则,并在数据写入的过程中逐步进行数据压缩;
- 格式 : 链表;
Labels:- 含义 : 时间序列的标签信息,记录了当前时间序列数据的所有标签信息,以便于后续进行索引查询;
- 格式 : 数组;
Chunks:- 含义 : 时间序列的样本数据信息,内部记录了当前时间序列的所有样本数据,便于后续的数据分析与查询;
- 格式 : 基数树;
- 类别 : 压缩格式(样本数据存储经过
Delta-Of-Delta和XOR压缩) 和 非压缩格式(直接存储原始样本数据);
- 其他成员变量信息;
|
2.3.2、时序二级索引数据结构
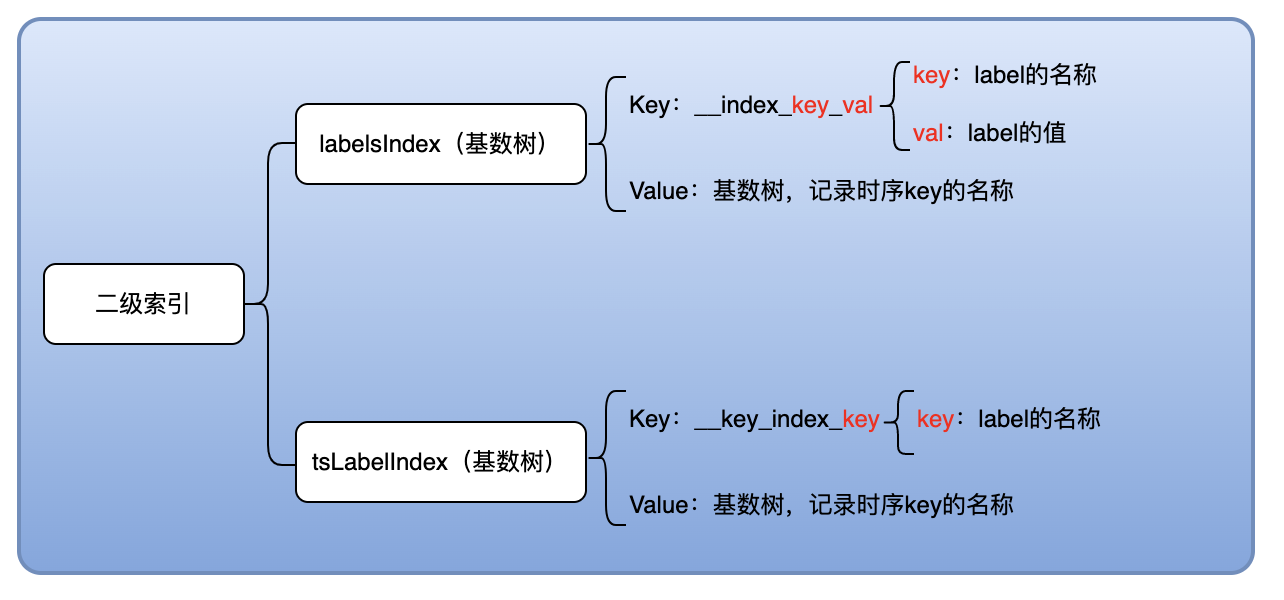
为了便于查询指定特征的时间序列,通过二级索引的方式保存了标签与时间序列的映射关系,主要的存储结构如下:
labelsIndex:- 含义 : 记录
标签名 + 值与时间序列的映射关系; - 格式 : 基数树;
- 含义 : 记录
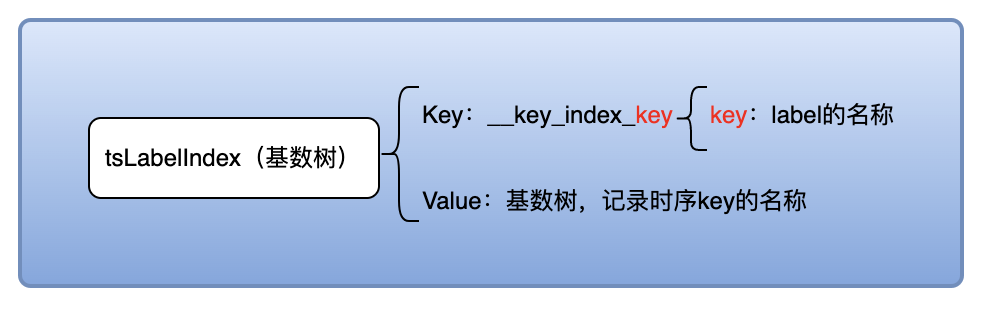
tsLabelIndex:- 含义 : 记录
标签名与时间序列的映射关系; - 格式 : 基数树;
- 含义 : 记录
|
2.4、持久化
2.4.1、RDB的持久化
RDB 的存储过程比较简单,直接把对应结构体的所有信息持久化到 RDB 文件中,一个时序数据的存储流程如下:
- 存储时序数据的元信息:
- 存储时序数据的基础信息(包括时序数据的名称,数据保留时间,每个桶的大小,最新的时间样本数据,样本总数,重复样本策略等);
- 存储时序数据的标签信息(包括多个标签的名称及其值);
- 存储时序数据的压缩规则信息(包括多个压缩规则的名称,压缩类型等);
- 存储时序数据的数据信息:
- 每个桶中存储的数据(压缩或者非压缩)信息;
2.4.2、AOF的持久化
AOF 的存储过程没有使用自定义的命令,而直接使用了 RESTORE 命令进行持久化,这种方式直接将整个时序数据作为一个命令存储起来,因此在读取的时候可能受限于 proto-max-bulk-len 参数的大小(默认为 1MB )而导致加载数据失败;
- 相关函数:
RMUtil_DefaultAofRewrite;- 依赖库:RedisModulesSDK
- 具体格式:
RESTORE key 0 buffer buffer_len;
三、功能设计
3.1、数据压缩
考虑到时序样本数据的特征,针对于样本数据的时间戳以及样本值信息,RedisTimeSeries 分别使用不同的压缩算法进行编码,这两种编码算法都来自于论文 《Gorilla: A Fast, Scalable, In-Memory Time Series Database》 ,基本业界大部分的时序数据库的数据压缩算法都是借鉴了这篇论文中的方式。
3.1.1、样本时间数据压缩
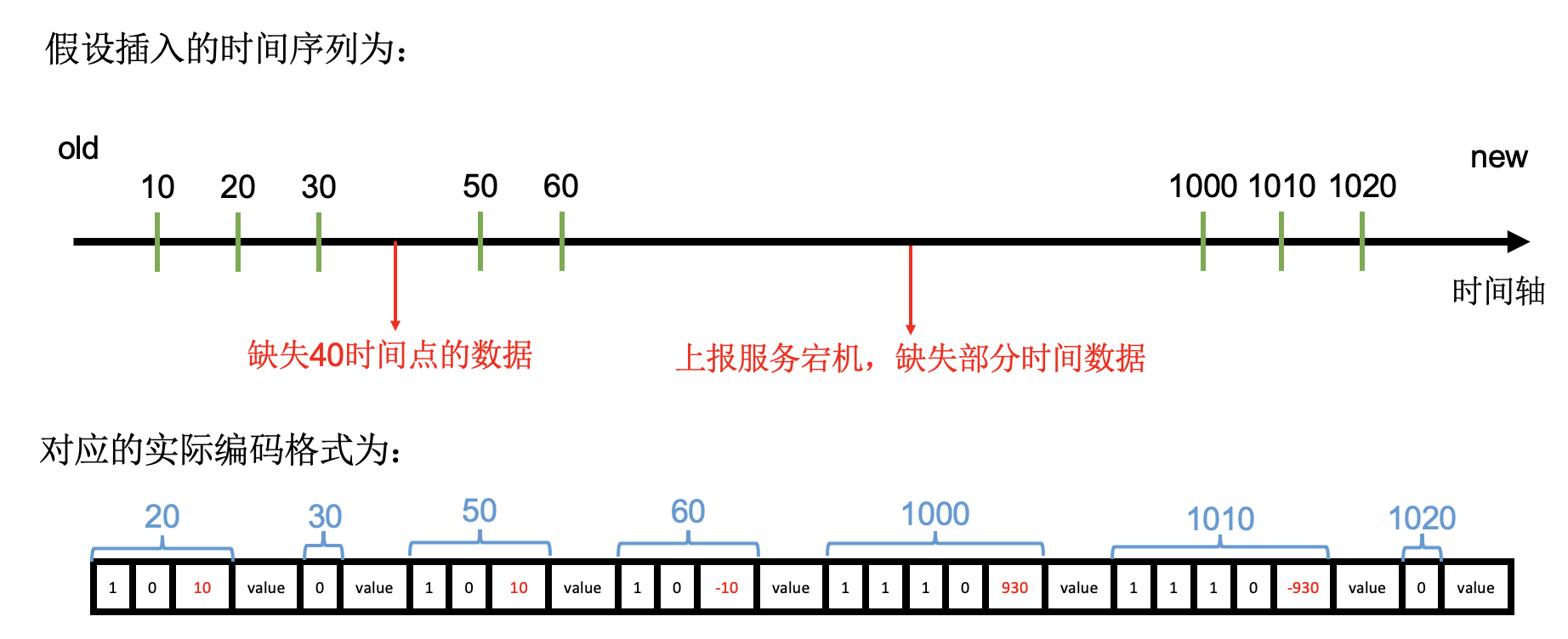
针对于时序数据样本中的时间戳,其采用了 Delta-Of-Delta 的编码方式,Redis在实现的时候,时间范围区间相比于论文 《Gorilla: A Fast, Scalable, In-Memory Time Series Database》 中更加细化,使用七种时间范围区间来进行编码。
Delta-Of-Delta中D定义:D = (T(N) – T(N-1)) – (T(N-1) – T(N-2))D区间范围:0: 使用1个bit存储二进制0,共1个bit;[-15, 16]: 使用2个bits存储二进制10,后面使用5个bits存储D值,共7个bits;[-127, 128]: 使用3个bits存储二进制110,后面使用8个bits存储D值,共11个bits;[-1023, 1024]: 使用4个bits存储二进制1110,后面使用11个bits存储D值,共15个bits;[-16383, 16384]: 使用5个bits存储二进制11110,后面使用15个bits存储D值,共20个bits;[-2147483647, 2147483648]: 使用6个bits存储二进制111110,后面使用32个bits存储D值,共38个bits;其它区间: 使用6个bits存储二进制111111,后面使用64个bits存储D值,共70个bits;
3.1.2、样本值数据压缩
针对于时序数据样本中的样本值,其采用了 XOR 的编码方式,下面介绍 XOR 编码的流程:
- 第一个
Value存储时不做任何压缩; - 从第二个
Value开始,写入时计算与前一个Value的XOR值:- 如果
XOR值为0,则代表两值相同,使用1个bit存储二进制0即可; - 如果
XOR值为非0,先使用1个bit存储二进制1,然后计算XOR中前后0的个数(前导零/尾随零):- 如果
前导零和尾随零与前一个相同,则使用1个bit存储二进制0,然后存储有效XOR值; - 如果
前导零和尾随零与前一个不同:- 使用
1个bit存储二进制1; - 使用
5个bit存储前导零的长度; - 使用
6个bit存储有效XOR的长度; - 存储
有效XOR的值;
- 使用
- 如果
- 如果
3.2、二级索引
为了便于查询指定特征的时间序列key列表,RedisTimeSeries 使用两种不同的索引来记录对应标签与时序key的映射关系。
labelsIndex 索引记录了标签名 + 值与时间序列的映射关系,并通过Redis提供的基数树的编码结构来存储,最终可以能够精确的筛选出特定标签值的时序key列表;tsLabelIndex 索引记录标签名与时间序列的映射关系,并通过Redis提供的基数树的编码结构来存储,最终可以能够精确的筛选出含有特定标签(不检查对应的标签值)的时序key列表;
3.2.1、索引变动
- 新增索引 :
IndexMetric: 新增时序key,变更时序key标签,restore时序key,rename时序key,copy时序key,加载时序key时会触发调用
- 删除索引 :
RemoveIndexedMetric: 删除特定时序key;RemoveAllIndexedMetrics: 删除所有时序key;
3.2.2、索引查询
- 相关命令 :
ts.mget: 批量查询多个符合条件的时序key,期间会查询标签信息;ts.queryindex: 查询特定标签的key的列表;
- 过滤器 :
label=value: 查询特定的 label 是 value 的 keys ;label!=value: 查询特定的 label 不是 value 的 keys ;label=: 查询所有有对应 label 的 key ;label!=: 查询所有不是对应 label 的 key ;label=(_value1_,_value2_,...): 查询 label 是列表中的其中一个值的 key ;label!=(value1,value2,...): 查询 label 不是列表中的任何一个值的 key ;
3.3、插值变更
正常情况下时序数据都是时间戳递增的样本数据,但是在极端的情况下,如果上报服务出现故障,故障恢复后客户可能期望将之前未上报的数据再次上报,这时候就会出现新插入的样本数据的时间戳小于已有样本数据时间戳的情况,这种情况下就需要一定的策略处理这些老数据。
3.3.1、插值变更策略
目前提供了多种插值变更(重复/乱序)的处理策略,该配置在操作时序数据时的相关参数为 DUPLICATE_POLICY :
block: 不允许出现乱序样本数据,默认的策略;first: 忽略任何新样本的值;last: 每次都更新样本的值;min: 只有新样本的值较小时,才采用新样本的值;max: 只有新样本的值较大时,才采用新样本的值;sum: 保存新样本和老样本值的和;
3.3.2、插值变更优先级
低优先级:ts.create和ts.alter命令可以初始化时序key的默认插值变更(重复/乱序)的策略,该策略的优先级较低;高优先级:ts.add和ts.madd命令可以指定命令级的插值变更的策略,该优先级较高;
3.3.3、插值变更实现
由于差值变更的过程中需要对现有的老的 chunk 进行变更,因此相比如单纯的追加样本数据,该操作的耗时较大,如果 chunk 启用了压缩特性,耗时会更加明显(由于需要解压缩),因此尽量慎用插值变更。
- 相关函数 :
SeriesUpsertSample; - 非压缩的chunk :
- 相关函数 :
Uncompressed_UpsertSample; - 执行逻辑 :
- 在对应的 chunk 中找到需要插入的位置;
- 将对应的样本数据插入对应的位置中;
- 重新分配 chunk 的大小,并插入位置之后的所有内存块(耗时);
- 相关函数 :
- 压缩的chunk :
- 相关函数 :
Compressed_UpsertSample; - 执行逻辑 :
- 找到对应的 chunk ;
- 分配一个新的 chunk ,将比当前样本的时间戳小的数据全部插入新的 chunk 中;
- 按照更新策略尝试更新当前样本的新的样本值,并将其加入到新的 chunk 中;
- 将对应样本之后的样本数据加入到新的 chunk 中;
- 将新的 chunk 替换掉老的 chunk ;
- 相关函数 :
3.4、降采样(数据压缩)
时序数据库在保存样本数据时支持一些数据降采样(数据压缩)策略,以便于节省数据存储空间。当需要对原始时序数据进行降采样时,可以通过 ts.createrule 命令新增一个 特殊的时序key 来存储降采样的时序数据,并且可以指定自定义的降采样规则。
降采样规则:- 支持多种降采样规则 (Min 、 Max 、 Avg 、 Sum 、 Range 、 Count 、 First 、 Last 、 STD.P 、 STD.S 、 Var.P 、 Var.S 、 twa);
- 支持设置降采样的时间周期,即多长的时间周期内降采样一次数据;
- 时间对齐策略;
降采样流程:- 随着对原始时间样本的增加,会自动计算符合条件的降采样规则;
- 自动将降采样之后的新的时间样本数据添加到对应的
特殊的时序key中;
3.5、聚合查询
业务在查询时序数据的场景下,通常不需要获取完整的时序数据,例如我们需要查看近一年所有股票的平均市值,这种情况下就需要时序数据库本身能够支持对一段时间范围内的样本数据进行聚合查询。
相关命令:ts.range,ts.revrange,ts.mrange,ts.mrevrange;聚合方式: Min 、 Max 、 Avg 、 Sum 、 Range 、 Count 、 First 、 Last 、 STD.P 、 STD.S 、 Var.P 、 Var.S 、 twa ;聚合配置:时间周期 (bucketDuration): 每次聚合的时间周期,单位毫秒;
四、对比与思考
4.1、RedisTimeSeries的一些问题
- 在
RedisCluster的架构模式下,各节点之间能够知道其他节点的信息,因此能够满足需要一次性获取分布在多个节点上的时序数据的需求(相关命令ts.mget,ts.queryindex,ts.mrange,ts.mrevrange),RedisTimeSeries目前使用的是 LibMR 这个 MapReduce 库来实现多实例的数据聚合,之后再一起返回给客户端,但是如果使用那个独立的Proxy + Redis的架构,就需要使得Proxy主动访问多Redis实例并对数据做聚合处理; - 原始时序样本 key 和 降采样(数据压缩)时序样本 key 都作为实际的 key 存储在 DB 中,容易触发数据误删的风险,并且在扩缩容的场景下也会有数据丢失的问题;
4.1、TairTS对比
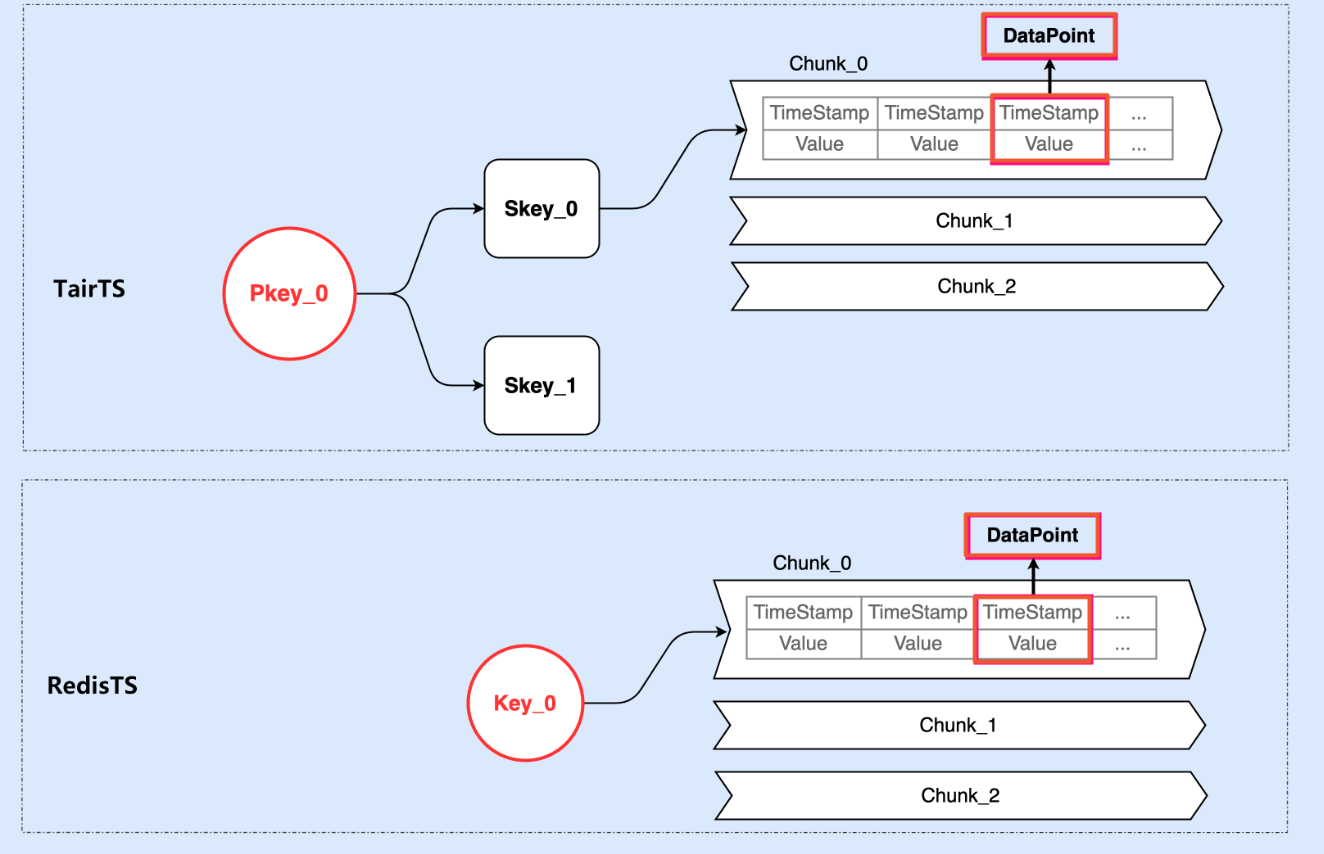
TairTS 的整体架构类似于 RedisTimeSeries 的设计,比较显著的区别是他们引入了 Pkey 和 Skey 的概念,同时为这两个概念又引入的不同的存储结构,经过简单的试用之后,这里做一下初略的对比介绍。
TairTS设计实现 :Pkey作为实际的时序Key存储在DB中;Skey只作为Pkey的属性存在(测试中通过增加Skey发现keys数量没有变化);Skey拥有与RedisTimeSeries中时序key一样的标签,样本有效期等属性信息;- 业务的时序样本数据最终需要同时指定
Pkey和Skey才能完成写入(从命令接口上来看与RedisTimeSeries有出入);
TairTS一些思考 :- 通过引入
Pkey和Skey的概念,能够实现二次数据聚合,完成RedisTimeSeries所不支持的功能,介绍; - 由于一个
Pkey中记录了很多的时间线数据,为了避免出现单分片数据的热点访问,数据分布不均以及大Key等情况发生,业务侧需要做一些数据的拆分,具体如何拆分需要结合实际业务场景进行;
- 通过引入
4.2、Redis时序模型存在的意义
众所周知,时序数据是一种数据量极大,写请求很高,极端情况下读请求也很高的数据模型,仅仅使用内存去存储这些数据,所消耗的成本将会非常大,虽然内存相比于硬盘在访问性能上能够带来极大的提升,但是如果仅仅使用一部分数据缓存在内存中,而不是全部使用内存,这种性能的差异会很大吗?初略看了一下目前业界的专业的时序数据库的压测报告,基本上访问性能已经不是瓶颈了,因此单纯的内存型时序数据库的场景到底在哪里,感觉还需要对市场做一些评估和调研。
Redis社区曾给出了几个使用Redis作为时序数据库的一些案例 3 Real-Life Apps Built with Redis Data Source for Grafana ,其中比较典型的一个案例是关于新冠病毒的病例情况,这种场景偏向于短时间段,或者说数据量不大的场景,从这里来看这的确是Redis时序的一种使用场景,但是这也不是Redis时序独有的场景,其他时序产品也完全能够胜任,甚至于更专业,但是换种方式去考虑一下,数据量较小的场景下,业务也完全可以不使用时序类的产品去存储。因此在这种场景下,Redis时序的蛋糕是被两头不断分割的,最后剩下的也就不多了。
五、相关链接


