RedisModule剖析 - RedisBloom
RedisBloom 这个 Module 内集成了很多的小功能,其中主要包括:可扩展的布隆过滤器(BloomFilter),可扩展的布谷鸟过滤器(CuckooFilter),最小计数草图(Count-Min Sketch),近似百分位(T-Digest),头部K元素(TopK)等。
一、简介
RedisBloom 是一款集成了众多功能的 RedisModule 模块,其主要包含了 BloomFilter (布隆过滤器) ,CuckooFilter (布谷鸟过滤器),Count-Min Sketch (最小计数草图),T-Digest (近似百分位) 以及 TopK 功能,其中很多功能都是依据 BloomFilter类 的相关功能来进行实现的,这里将会对它们的具体实现做一下深度的剖析。
- 官网:https://redisbloom.io/
- GitHub 地址:https://github.com/RedisBloom/RedisBloom
- 命令文档地址:https://redis.io/docs/stack/bloom/
- 支持功能:
- 可扩展的 BloomFilter (布隆过滤器) : 用于确定一个元素是否存在于一个集群中;
- 可扩展的 CuckooFilter (布谷鸟过滤器) : 用于确定一个元素是否存在于一个集合中;
- Count-Min Sketch (最小计数草图) : 用于估计一个数据的出现次数;
- T-Digest (近似百分位) :
- TopK : 维护了 k 个最常见项目的列表;
二、可扩展的 BloomFilter (布隆过滤器)
社区在实现可扩展的 BloomFilter 的时候应该参考了论文: 《Scalable Bloom Filters》 ,这篇论文的翻译稿:
RedisBloom 通过将单个的数据表分散到多个数据表中,从而实现了一种可扩展数据表的布隆过滤器,虽然这种方式使用较为灵活,不受限于初始容量的约束,但是动态的申请多个子布隆过滤器会导致内存的增长比较严重,要这种方式就要在灵活以及内存间做一些取舍。
2.1、相关命令
以下命令仅参考当时的最新的代码,详细的准确命令请参考 社区命令文档地址 。
- bf.add : 向目标布隆过滤器中添加一个元素;
- bf.madd : 向目标布隆过滤器中添加多个元素;
- bf.exists : 在目标布隆过滤器中判断一个元素是否存在;
- bf.mexists : 在目标布隆过滤器中判断多个元素是否存在;
- bf.info : 查看对应布隆过滤器的基础信息;
- bf.debug : 查看对应布隆过滤器的详细信息(包含每个布隆过滤器表的信息);
- bf.insert : 向目标布隆过滤器中插入元素,如果对应布隆过滤器不存在则创建;
- bf.reserve : 修改目标布隆过滤器的属性;
- bf.loadchunk : 布隆过滤器从 AOF 中加载数据时用到的命令;
- bf.scandump : 布隆过滤器向 AOF 中持久化数据时用到的命令;
2.2、编码结构
一个可扩展的布隆过滤器所依赖的主要数据结构如下所示:
|
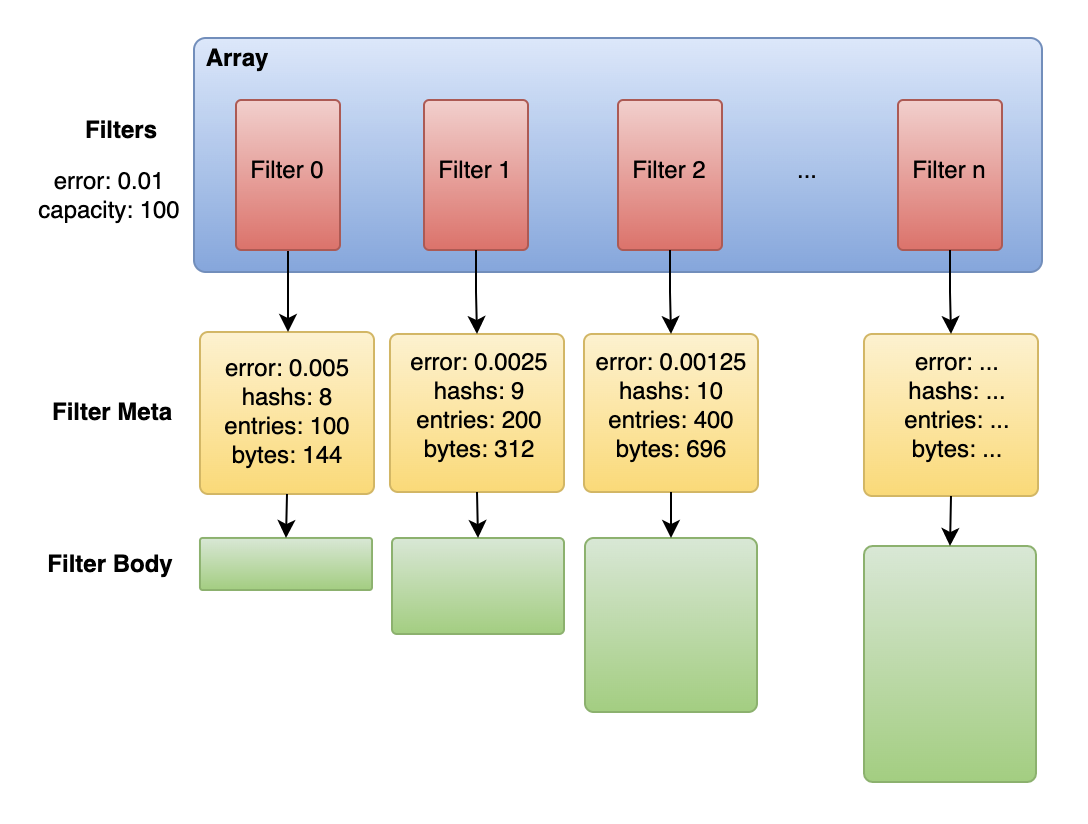
2.3、哈希规则(插入/判断规则)
按照布隆过滤器的计算规则,在不同的误判率的情况下我们需要使用多个不同的哈希函数计算对应的比特位,我们接下来看一下布隆过滤器的判断/插入规则:
- 哈希算法:
MurmurHash64A - 判断方式:
- 首先使用固定的哈希种子,对传入的元素计算其哈希值,并将其作为基础的哈希值;
- 然后使用传入元素的哈希值作为哈希种子,计算下一次哈希位置的步进值;
- 利用得到的传入元素的哈希特征,在多个布隆过滤器中进行判断元素是否存在;
- 判断基础的哈希值对应的比特索引;
- 利用计算的步进值,判断下一个对应的比特索引;
|
2.4、持久化
2.4.1、RDB的持久化
RDB 的存储过程比较简单,直接把对应结构体的所有信息持久化到 RDB 文件中,一个可扩展的布隆过滤器的存储流程如下:
- 存储对应的所有子布隆过滤器的元信息(包括子布隆过滤器的数量,配置项等);
- 存储每个子布隆过滤器的信息:
- 子布隆过滤器的元信息(包括元素数量,误判率,哈希数量等);
- 子布隆过滤器的数据信息;
2.4.2、AOF的持久化
数据 AOF 的持久化会在 AofRewrite 的时候时用到,因为需要封装一下命令以便于下一次的加载 bf.loadchunk,一个可扩展的布隆过滤器的存储流程如下:
- 首先存储对应布隆过滤器的元信息(包括布隆过滤器的数量,配置项,以及子布隆过滤器的元素数量,误判率,哈希数量等);
- 存储命令简化为:
BF.LOADCHUNK key 1 meta_data meta_len;
- 存储命令简化为:
- 然后存储所有子布隆过滤器的数据信息,默认单次存储的数据信息大小最大为 16MB,以下命令会持久化多次;
- 存储命令简化为:
BF.LOADCHUNK key iter body_data body_len;
- 存储命令简化为:
|
三、可扩展的 CuckooFilter (布谷鸟过滤器)
布谷鸟过滤器在某些场景下能够比布隆过滤器提供更好的填充率,并且支持了删除元素,在某些场景下也为很多业务提供了更好的支持。
3.1、相关命令
以下命令仅参考当时的最新的代码,详细的准确命令请参考 社区命令文档地址 。
- cf.add : 向目标布谷鸟过滤器中添加一个元素;
- cf.addnx : 向目标布谷鸟过滤器中添加一个元素,只有当元素不存在时才会添加成功;
- cf.count : 计算在目标布谷鸟过滤器中对应元素的个数,由于是计算对应元素的指纹的存在个数,因此最终结果可能不准确;
- cf.del : 从布谷鸟过滤器中删除一个元素,删除的是元素的指纹,并且只删除一次;
- cf.exists : 判断布谷鸟过滤器中对应元素是否存在;
- cf.mexists : 判断布谷鸟过滤器中多个元素是否存在;
- cf.info : 获取布谷鸟过滤器的信息;
- cf.insert : 向布谷鸟过滤器中插入一个元素,如果布谷鸟过滤器不存在则创建;
- cf.insertnx : 向布谷鸟过滤器中插入一个元素,如果布谷鸟过滤器不存在则创建,如果对应元素已经存在则不会插入成功;
- cf.reserve : 修改对应布谷鸟过滤器的属性;
- cf.loadchunk : 持久化的相关命令;
- cf.scandump : 持久化的相关命令;
3.2、编码结构
一个可扩展的布谷鸟过滤器所依赖的主要数据结构如下所示:
|
3.3、哈希规则(插入/判断规则)
按照布谷鸟过滤器的计算规则,当我们需要判断一个元素是否存在的时候需要判断两个位置上的空间中是否存在特定的指纹信息;当需要进行插入操作的时候需要从两个索引的位置上随机找到一个空余的空间进行插入操作,因此针对于每一个传入的元素,我们都会生成两个对应的特征值。
- 哈希算法:
MurmurHash64A - 判断方式:
- 依据传入的元素,利用哈希算法
MurmurHash64A计算其哈希值; - 利用哈希值计算对应传入元素的指纹信息(
fp),以及对应的两个哈希特征值(h1和h2); - 依次判断多个子布谷鸟过滤器中是否有足够的空间来存储新的元素;
- 每次都使用传入元素的两个哈希特征值(
h1和h2)判断在对应的 bucket 的数组中是否存在空位置:- 如果有空位置则将对应的元素指纹插入对应空位;
- 如果没有空位置则尝试进行踢除操作;
- 每次都使用传入元素的两个哈希特征值(
- 插入元素或者判断元素是否存在结束;
- 依据传入的元素,利用哈希算法
|
3.4、踢除规则
由于不同传入值的指纹可能相同,同一个 bucket 的空间可能会被其他相同指纹的传入值占满,导致新的值无法插入,这时就需要对已有空间中的值进行踢除操作。
- 相关函数:
Filter_KOInsert - 具体流程:
- 将从最新的布谷鸟过滤器中执行踢除操作;
- 依据传入值的其中一个哈希值,找到对应的 bucket 的位置,获取其中特定位置中的指纹信息,然后将新的指纹存储到特定位置上;
- 寻找上次获取到的 bucket 中的老的指纹的下一个位置点,判断对应的 bucket 中是否有空闲位置:
- 如果有空闲位置,则将之前替换出的指纹存到新 bucket 的空闲位置中;
- 如果没有空闲位置,则再次进行寻找,再次从第2步开始;
3.5、持久化
3.5.1、RDB的持久化
RDB 的存储过程比较简单,直接把对应结构体的所有信息持久化到 RDB 文件中,一个可扩展的布谷鸟过滤器的存储流程如下:
- 存储对应的所有子布谷鸟过滤器的元信息(包括子布谷鸟过滤器的数量,配置项等);
- 存储每个子布谷鸟过滤器的信息:
- 子布谷鸟过滤器的元信息(包括 bucket 数量等);
- 子布谷鸟过滤器的数据信息;
3.5.2、AOF的持久化
数据 AOF 的持久化会在 AofRewrite 的时候时用到,因为需要封装一下命令以便于下一次的加载 cf.loadchunk,一个可扩展的布谷鸟过滤器的存储流程如下:
- 首先存储对应布谷鸟过滤器的元信息(包括布谷鸟过滤器的数量,配置项,以及子布谷鸟过滤器的 bucket 数量等);
- 存储命令简化为:
CF.LOADCHUNK key 1 meta_data meta_len;
- 存储命令简化为:
- 然后存储所有子布谷鸟过滤器的数据信息,默认单次存储的数据信息大小最大为 16MB,以下命令会持久化多次;
- 存储命令简化为:
CF.LOADCHUNK key iter body_data body_len;
- 存储命令简化为:
四、Count-Min Sketch (最小计数草图)
Count-Min Sketch (最小计数草图) 的实现思路类似于 Counting-BloomFilter (计数布隆过滤器) , 插入的过程中,使用多个哈希函数使得对应元素在对应位置上的值(范围是uint32_t)加1;查询的过程中,使用多个哈希函数获取对应元素在对应位置上的值(范围是uint32_t),并返回最小值(将其作为这个元素的操作次数),因此最终的值有可能会大于实际的操作值,Count-Min Sketch 的名字也是这么来的。
4.1、相关命令
以下命令仅参考当时的最新的代码,详细的准确命令请参考 社区命令文档地址 。
- cms.incrby : 按增量增加对应元素的计数值,支持多元素增加计算;
- cms.info : 获取对应草图的宽度、深度和总数;
- cms.initbydim : 根据指定的
width和depth来初始化Count-Min Sketch;- 格式 :
cms.initbydim key width depth - 解释 :
key: 草图的名称;width: 每个数组中计数器的数量,如果该值较小,则误判的概率较大;depth: 每次需要比较的数组的数量(计数器阵列的数量),减少特定大小错误的概率(占总数的百分比);
- 格式 :
- cms.initbyprob : 根据错误率计算得到对应的
width和depth来初始化Count-Min Sketch;- 格式 :
cms.initbyprob key error probability - 解释 :
key: 草图的名称;error: 预估错误的值,这应该是介于0和1之间的十进制值,错误是总计数项目的百分比,影响草图的宽度;probability: 膨胀计数的期望概率,这应该是介于0和1之间的十进制值(例如0.001),影响草图的深度;
- 计算规则 :
- 相关函数 :
CMS_DimFromProb; width值 :ceil(2 / error);depth值 :ceil(log10f(probability) / log10f(0.5));
- 相关函数 :
- 格式 :
- cms.merge : 将多个草图合并为一个草图。所有草图必须具有相同的宽度和深度,支持设置合并的权重;
- cms.query : 返回草图中一个或多个项目的计数;
4.2、编码结构
|
4.3、哈希规则
- 哈希算法:
MurmurHash2; - 具体流程:
- 每一个最小计数草图都有一个深度的值,依据该深度值依次查询对应深度的对应索引上的值;
- 根据当前的深度,设置获取哈希值的种子(从
0到当前最小计数草图的深度),然后得到对应的哈希值; - 依据哈希值得到当前深度下的对应位置上的值;
- 获取或者变更对应位置上的值;
|
4.4、持久化
4.4.1、RDB的持久化
RDB 的存储过程比较简单,直接把对应结构体的所有信息持久化到 RDB 文件中,一个最小计数草图的存储流程如下:
- 存储对应的最小计数草图的元信息(包括深度,宽度,当前计数和等);
- 存储对应的最小计数草图的数据信息(即对应结构体中的
array指针指向的内存块信息);
4.4.2、AOF的持久化
AOF 的存储过程没有使用自定义的命令,而直接使用了 RESTORE 命令进行持久化:
- 相关函数:
RMUtil_DefaultAofRewrite; - 具体格式:
RESTORE key 0 buffer buffer_len;
五、T-Digest (近似百分位)
T-Digest 是一个简单、快速、精确度高、可并行化的近似百分位算法,被 ElastichSearch、Spark 和 Kylin 等系统使用。TDigest 主要有两种实现算法,一种是 buffer-and-merge 算法,一种是 AVL树 的聚类算法。RedisBloom 使用的是 buffer-and-merge 算法。
5.1、相关命令
以下命令仅参考当时的最新的代码,详细的准确命令请参考 社区命令文档地址 。
- tdigest.create : 创建一个
T-Digest草图; - tdigest.add : 将一个或多个值添加到
T-Digest草图; - tdigest.reset : 清空草图并重新初始化它;
- tdigest.merge : 将多个
T-Digest草图中的数据合并到目标T-Digest草图中; - tdigest.min : 获取草图中最小的值;
- tdigest.max : 获取草图中最大的值;
- tdigest.quantile : 返回一个或多个截止值的估计值,使得添加到此
T-Digest的观察值的指定分数将小于或等于每个指定的截止值; - tdigest.cdf : 估计添加的所有观察值中 <= 值的比例;
- tdigest.info : 获取
T-Digest草图的信息; - tdigest.rank : 检索值的估计等级(草图中小于值的观察数 + 等于值的观察数的一半);
- tdigest.revrank : 检索值的估计等级(草图中大于值的观察数 + 等于值的观察数的一半)
- tdigest.byrank : 检索具有给定等级的值的估计值;
- tdigest.byrevrank : 使用给定的反向排名检索值的估计;
- tdigest.trimmed_mean : 估计草图中的平均值,不包括低和高截止分位数之外的观察值;
5.2、编码结构
|
5.3、数据压缩
- 相关函数:
- 判断函数:
should_td_compress - 执行函数:
td_compress
- 判断函数:
- 压缩逻辑:
- 快速排序等待压缩的节点数组,调用
td_qsort; - 其他压缩逻辑,详见函数:
td_compress;
- 快速排序等待压缩的节点数组,调用
5.4、持久化
5.4.1、RDB的持久化
RDB 的存储过程比较简单,直接把对应结构体的所有信息持久化到 RDB 文件中,一个 T-Digest 的存储流程如下:
- 尝试进行数据压缩;
- 存储对应的
T-Digest的所有元信息(包括压缩值,最大最小值,容量,节点数等); - 存储对应的
T-Digest的节点信息(已经 merge 节点的值和权重值);
5.4.2、AOF的持久化
AOF 的存储过程没有使用自定义的命令,而直接使用了 RESTORE 命令进行持久化:
- 相关函数:
RMUtil_DefaultAofRewrite; - 具体格式:
RESTORE key 0 buffer buffer_len;
六、TopK(头部K元素)
TopK 用于展示前 K 个分数最高的数据,数据存储方式参考了 Count-Min Sketch (最小计数草图) 的设计实现,可以容纳的有效数据量依赖于初始化时指定的 width 和 depth ,并且引入了一种分数衰减机制来实现对老数据的清理。
6.1、相关命令
以下命令仅参考当时的最新的代码,详细的准确命令请参考 社区命令文档地址 。
- topk.reserve : 初始化一个
TopK; - topk.add : 向
TopK中添加元素,支持添加多个元素; - topk.incrby : 按增量增加一个或多个元素的计数;
- topk.query : 检查一个或多个项目是否在
TopK中; - topk.count : 返回项目的计数;
- topk.list : 返回
Top K列表中项目的完整列表; - topk.info : 返回
TopK的数量、宽度、深度和衰减值;
6.2、编码结构
|
6.3、哈希规则
- 哈希算法:
MurmurHash2; - 具体流程:
- 获取元素的指纹信息;
- 依次遍历整个
TopK的不同深度中对应索引处的值,判断数据是否存在;- 使用对应的深度值
i作为哈希种子,计算对应元素的哈希值; - 哈希值取模
TopK 的宽度,计算出对应元素在当前深度中的索引; - 判断对应索引处的信息是否为插入的元素,以便于应对插入与查询操作;
- 使用对应的深度值
|
6.4、TopK堆更新机制
- 触发条件:
- 操作元素的分数值大于
TopK中的最小值;
- 操作元素的分数值大于
- 更新方式:
- 如果对应元素已经存在:更新对应元素的分数,然后重新排序对应元素的位置直到结束的位置;
- 如果对应元素不存在:剔除
TopK中第一个元素,将其替换为本次变更的元素,然后对整个TopK进行重新排序;
- 更新细节:
- 相关函数:
heapifyDown;
- 相关函数:
|
6.5、衰减算法
- 衰减的考量:
- 之前写入的老数据可能长时间不在访问,但是它们还会一直占用着对应的存储位置,如果老数据之前的分数较高,则其可能长时间位于
TopK中; - 随着数据量的增加,新写入的数据可能会和被计算到与老数据相同的位置上,如果位置相同,但是指纹却不同,此时我们无法对现有的分数进行变更,但是我们可以尝试不断衰减老数据的分数,直到其为零后,我们就可以将其指纹以及分数替换成新的数据值;
- 通过这种方式我们可以实现变化的
TopK排行,并且解决了老数据占位的问题;
- 之前写入的老数据可能长时间不在访问,但是它们还会一直占用着对应的存储位置,如果老数据之前的分数较高,则其可能长时间位于
- 触发衰减的条件(必须全部满足):
- 执行元素插入操作,相关命令:
topk.add,topk.incrby; - 根据元素而计算的存储位置处非空且对应的指纹和元素的指纹不匹配;
- 执行元素插入操作,相关命令:
- 衰减的机制:
- 临时
delay的值:- 对应位置的分数
小于 256,则值为topk->lookupTable[count]; - 对应位置的分数
大于 256,则值为pow(topk->lookupTable[255], count/255 * topk->lookupTable[count%256]);
- 对应位置的分数
- 随机值
chance: 等于rand() / (double)(2^32-1);- 如果随机值
chance小于decay则将原始分数减1;
- 如果随机值
- 临时
|
6.5、持久化
6.5.1、RDB的持久化
RDB 的存储过程比较简单,直接把对应结构体的所有信息持久化到 RDB 文件中,一个 TopK 的存储流程如下:
- 尝试进行数据压缩;
- 存储对应的
TopK的所有元信息(包括保留分数最大的数量,数组的计数数量,数组的计数深度,衰减值等); - 存储对应的
TopK的数据信息(包括所有的数据及分数信息,TopK中的数据及其分数信息);
6.5.2、AOF的持久化
AOF 的存储过程没有使用自定义的命令,而直接使用了 RESTORE 命令进行持久化:
- 相关函数:
RMUtil_DefaultAofRewrite; - 具体格式:
RESTORE key 0 buffer buffer_len;
七、参考链接:


