Redis主从复制演进史与奇思妙想
Redis 的主从复制模型从 Redis2.8 版本到 Redis7.0 经历了很多大的优化与改造,从最初版本的全量数据同步,到后续的 PSYNC 的增量数据同步,无盘数据传输方案,PSYNC2 的同源数据同步方案,无盘数据加载方案到当前的最新版本中的共享复制缓冲区的方案。同时社区中也诞生了一些奇妙的解决方案,例如基于AOF文件的增量同步等。这篇文章主要借鉴于 Redis 主从复制演进历程与百度实践 ,同时按照自己的理解绘制了一些示意图。
一、简介
目前 Redis 支持两种主从数据同步方式:全量同步和增量同步。
二、Redis主从复制演进史
2.1、SYNC方案
版本范围:1.3.6 ~ 2.6.17 (以下分析基于 2.6.17 版本)
方案特点:
- 支持全量数据同步;
持久化及传输流程:
- 调用 fork 生成子进程,并在子进程中将内存中的数据持久化到 rdb 文件中;
- 获取所有状态为 WAIT_BGSAVE_END 的从库,为其注册发送 rdb 数据的事件;
- 发送 rdb 数据完成后,将发送堆积的增量数据给从库;
交互流程:
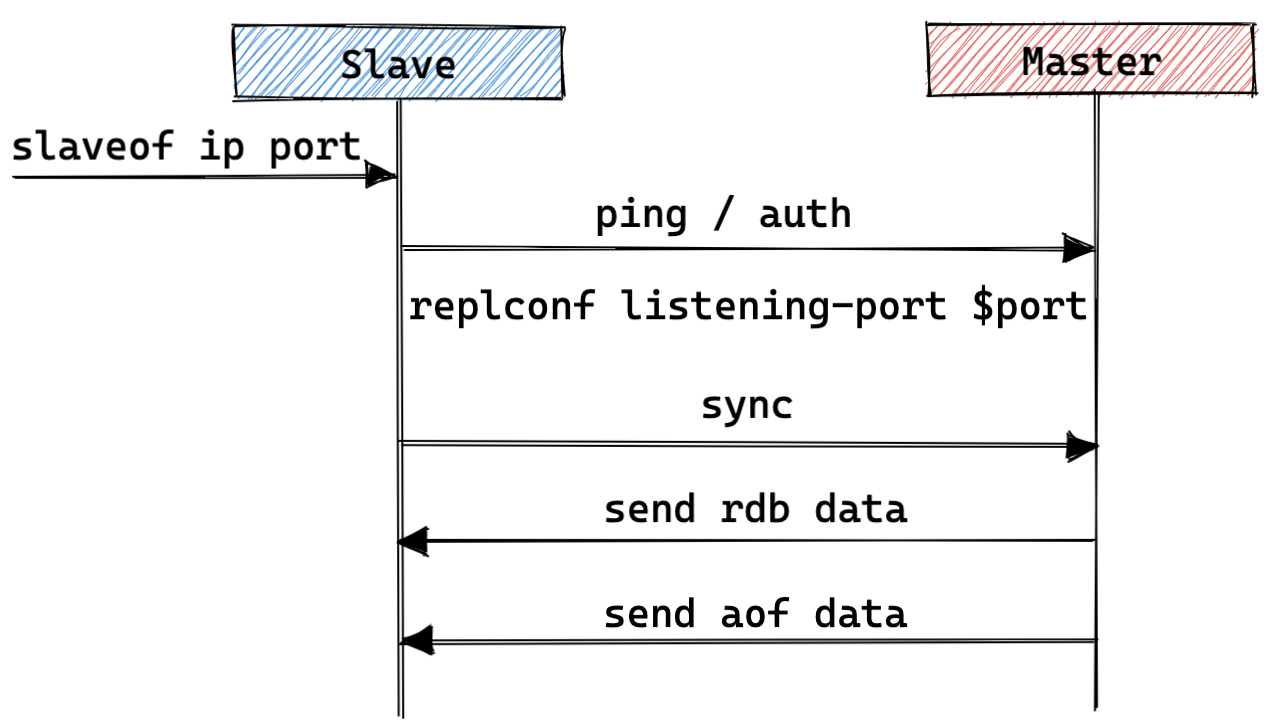
- 主库:
- 接收从库的建连请求;
- 处理从库发送的探测消息,并依次按需给从库返回 pong / ok / ok 消息;
- 处理从库发送的 sync 命令,使用 fork 的方式持久化 rdb 数据,之后在主线程中注册一个读写事件将其数据发送给从库;
- 从库:
- 外部对从库执行 slaveof master_ip master_port 操作,从库主动与主库建立连接;
- 从库依次按需发送 ping / auth / replconf listening-port $port 消息给主库,并接受主库回复;
- 从库给主库发送 sync 命令,准备接收主库的 rdb 消息内容,并在接收完成后加载数据;
- 主库:
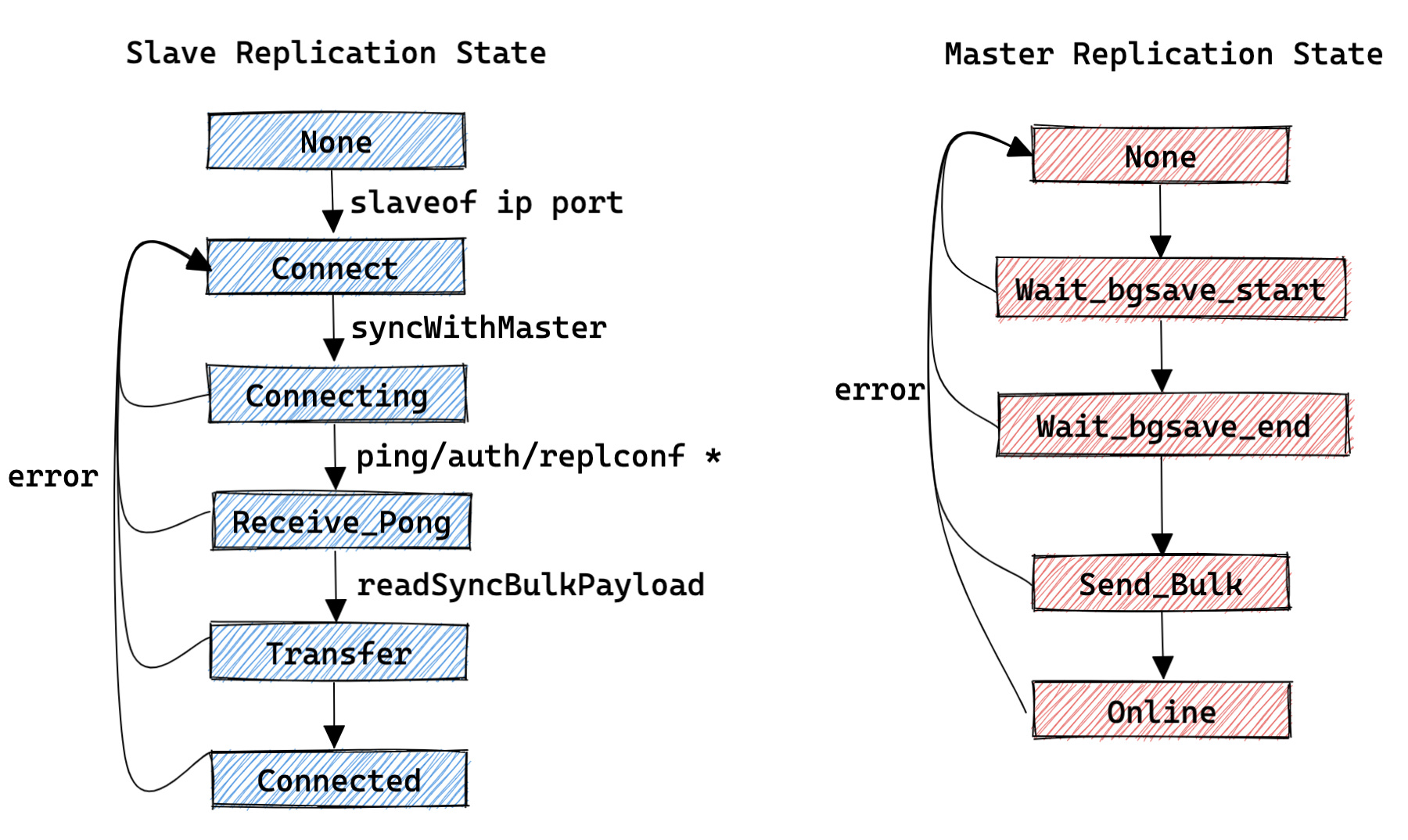
- 复制状态机:
- 主库(slave->replstate):
- REDIS_REPL_NONE : 创建从库客户端的初始状态;
- REDIS_REPL_WAIT_BGSAVE_START : 当前存在正在执行 bgsave 的任务,需要等待下一次的 bgsave 的标记状态;
- REDIS_REPL_WAIT_BGSAVE_END : 对应客户端正在等待 bgsave 完成的标记状态;
- REDIS_REPL_SEND_BULK : 正在给对应的客户端发送 rdb 数据的状态;
- REDIS_REPL_ONLINE : 发送完成 rdb 数据后状态;
- 从库(server.repl_state):
- REDIS_REPL_NONE : 初始状态;
- REDIS_REPL_CONNECT : 从库执行 slaveof 之后的状态;
- REDIS_REPL_CONNECTING : 从库连接主库之后的状态;
- REDIS_REPL_RECEIVE_PONG : 从库向主库发送 ping 之后等待接收 pong 时的状态;
- REDIS_REPL_TRANSFER : 从库开始接收 rdb 数据的状态;
- REDIS_REPL_CONNECTED : 从库接收 rdb 并加载数据完成的状态;
- 主库(slave->replstate):
2.2、PSYNC方案
版本范围:2.8.0 ~ 2.8.17 (以下分析基于 2.8.17 版本)
方案特点:
- 引入 repl_backlog 的概念,用于在主库上保存一部分写入历史,作为后续从库增量同步的数据源;
- 引入 psync_runid 和 psync_offset 的概念,用于支持从库发起增量同步,并且用于主库进行增量同步的验证;
持久化及传输流程:
- 主库调用 fork 生成子进程,并在子进程中将内存中的数据持久化到 rdb 文件中;
- 主库获取所有状态为 WAIT_BGSAVE_END 的从库,为其注册发送 rdb 数据的事件;
- 主库发送 rdb 数据完成后,将发送堆积的增量数据给从库;
交互流程:
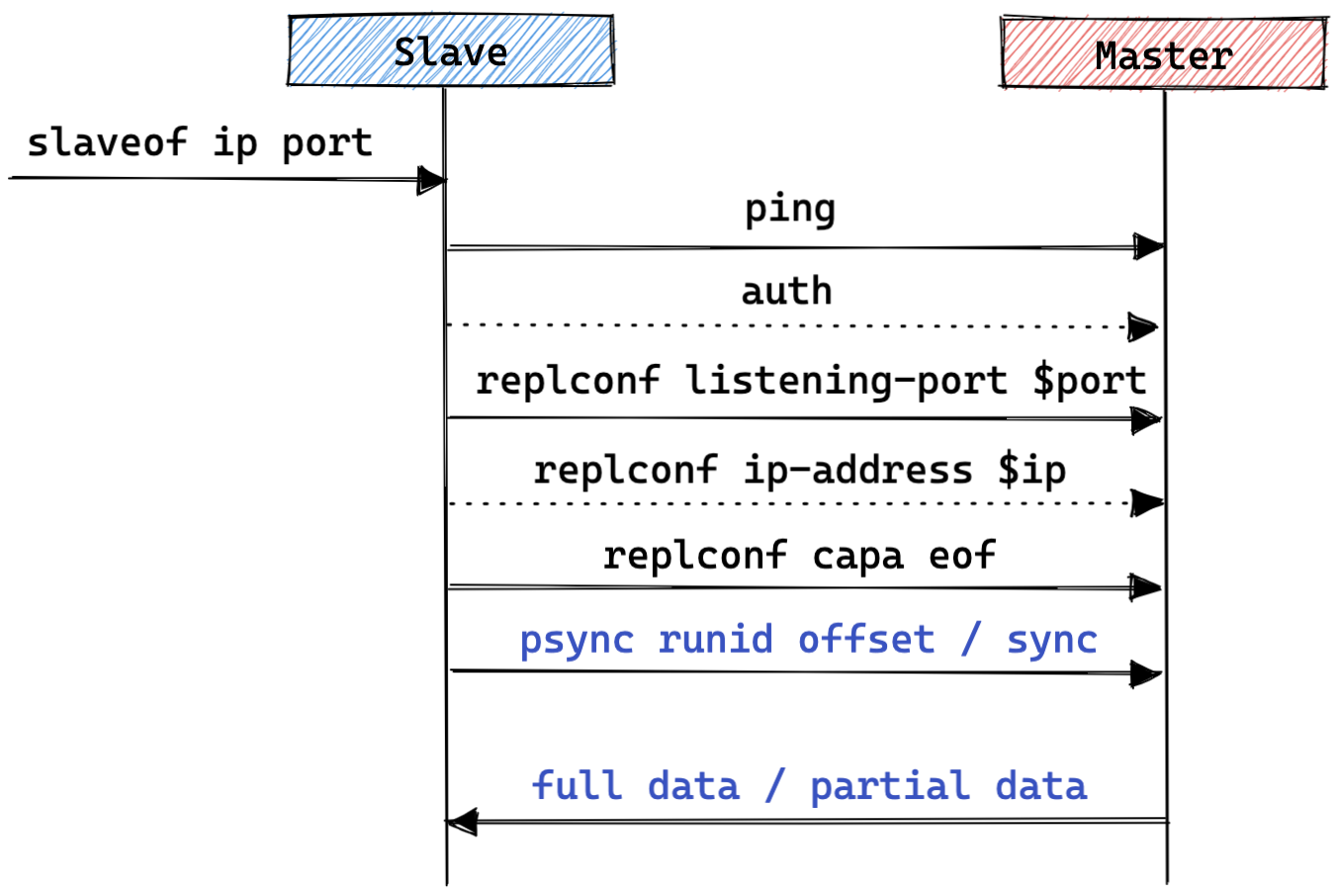
主库:
- 接收从库的建连请求;
- 处理从库发送的探测消息,并依次按需给从库回复消息;
- 处理从库发送的 psync runid offset 或 sync 命令,校验 runid 和 offset ,之后主库给从库回复标识以及对应数据,其中标识为:
- 全量同步标识 :
+FULLRESYNC runid offset; - 增量同步标识 :
+CONTINUE;
- 全量同步标识 :
从库:
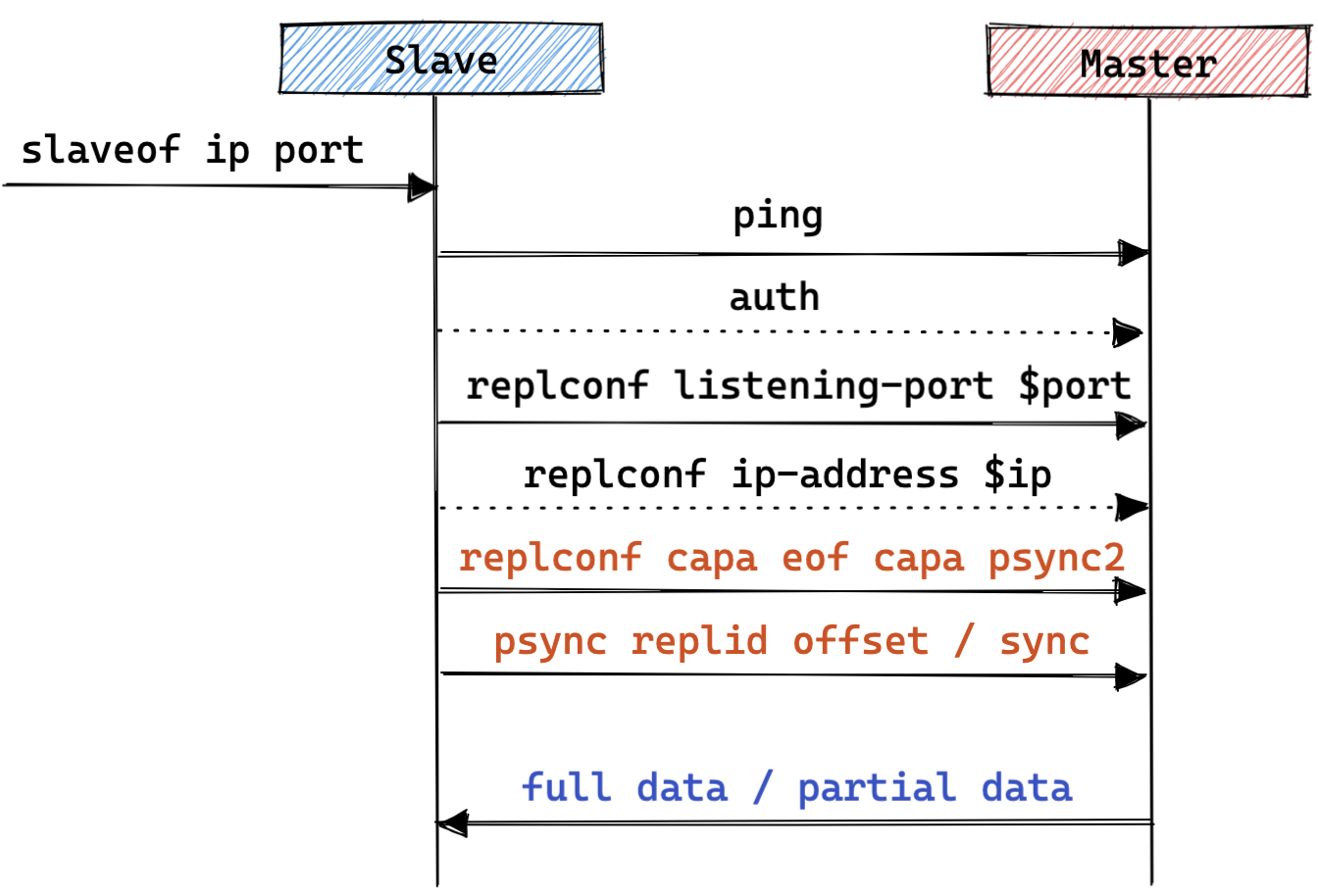
外部对从库执行 slaveof master_ip master_port 操作,从库主动与主库建立连接;
从库向主库发送 ping 命令,并接收回复消息;
从库按需向主库发送 auth 命令,并接收回复消息;
从库向主库发送 replconf listening-port $port 消息,并接收回复消息;
从库按需向主库发送 replconf ip-address $ip 消息,并接收回复消息;
从库向主库发送 replconf capa eof 消息,并接收回复消息;
从库向主库发送 psync runid offset 或者 sync 消息,并接收回复消息,从库之后进入全量或增量数据同步;
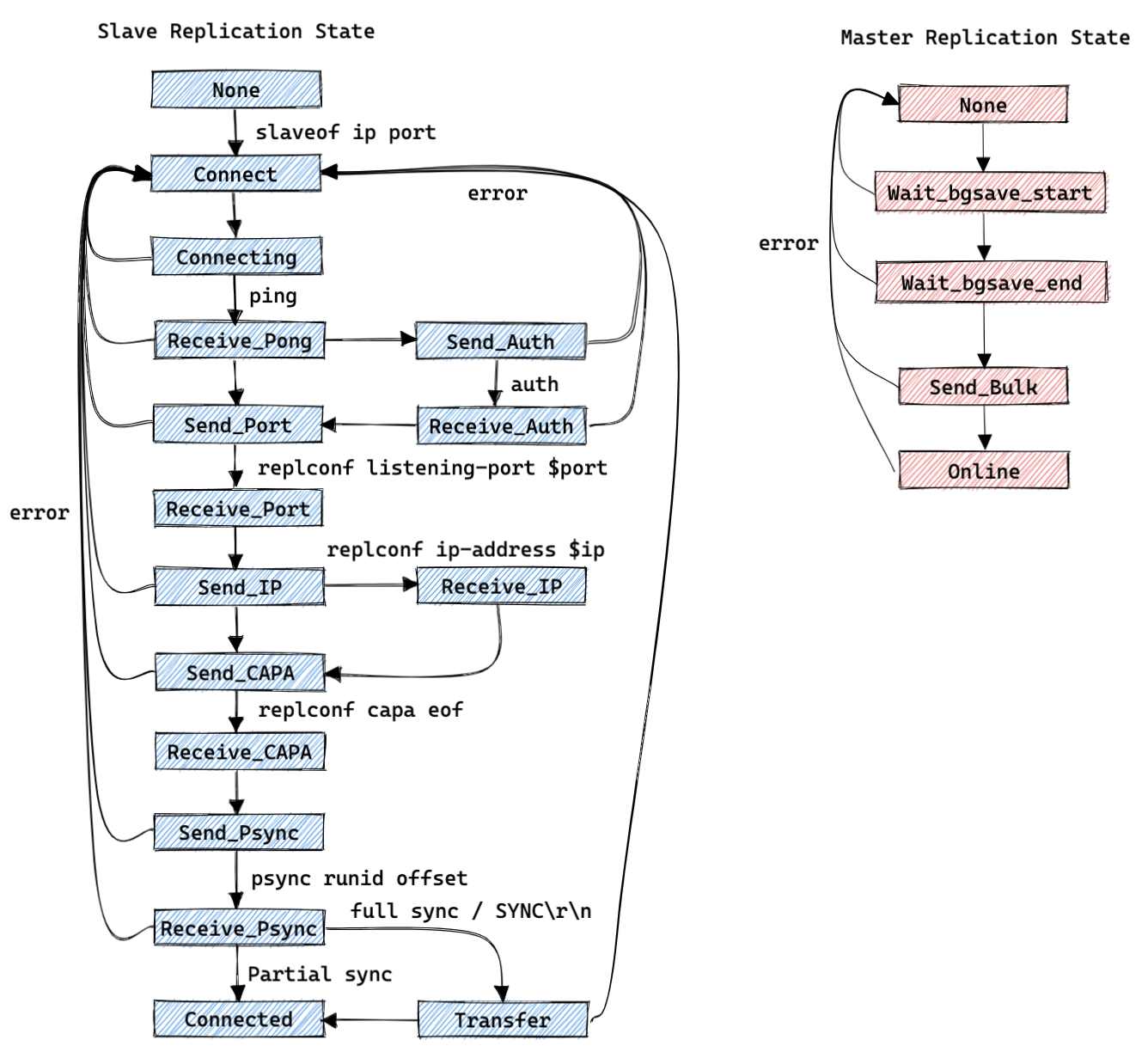
复制状态机:
主库(slave->replstate):
- REPL_STATE_NONE : 创建从库客户端后的初始状态;
- SLAVE_STATE_WAIT_BGSAVE_START : 等待开始生成一个 rdb 数据文件;
- SLAVE_STATE_WAIT_BGSAVE_END : 等待生成一个 rdb 数据文件完成;
- SLAVE_STATE_SEND_BULK : 正在给对应的客户端发送 rdb 数据的状态;
- SLAVE_STATE_ONLINE : 发送完成 rdb 数据后状态;
从库(server.repl_state):
- REPL_STATE_NONE : 初始状态;
- REPL_STATE_CONNECT : 从库执行 slaveof 之后的状态;
- REPL_STATE_CONNECTING : 从库连接主库之后的状态;
- REPL_STATE_RECEIVE_PONG : 从库向主库发送 ping 之后等待接收 pong 时的状态;
- REPL_STATE_SEND_AUTH : 从库接下来按需向主库发送 auth 消息;
- REPL_STATE_RECEIVE_AUTH : 从库向主库发送 auth 之后等待接收返回消息时的状态;
- REPL_STATE_SEND_PORT : 从库接下来要向主库发送 replconf listening-port $port 消息;
- REPL_STATE_RECEIVE_PORT : 从库向主库发送 replconf listening-port $port 之后等待接收返回消息时的状态;
- REPL_STATE_SEND_IP : 从库接下来按需向主库发送 replconf ip-address $ip 消息;
- REPL_STATE_RECEIVE_IP : 从库向主库发送 replconf ip-address $ip 之后等待接收返回消息时的状态;
- REPL_STATE_SEND_CAPA : 从库接下来要向主库发送 replconf capa eof 消息;
- REPL_STATE_RECEIVE_CAPA : 从库向主库发送 replconf capa eof 之后等待接收返回消息时的状态;
- REPL_STATE_SEND_PSYNC : 从库接下来要向主库发送 psync runid offset 或者 sync 消息
- REPL_STATE_RECEIVE_PSYNC : 从库向主库发送 psync / sync 之后等待接收返回消息时的状态;
- REPL_STATE_TRANSFER : 从库开始等待接收全量(rdb)的数据;
- REPL_STATE_CONNECTED : 从库开始等待接收增量的数据;
2.3、无盘传输方案
版本范围:2.8.18 ~ 3.2.13 (以下分析基于 3.2.13 版本)
方案特点:
- 主库无需将 rdb 数据持久化就可以将数据传输给从库(引入 repl-diskless-sync 开关控制);
- 支持同时给多个从库传输 rdb 数据;
持久化及传输流程(仅介绍无盘传输):
主库获取所有状态为 WAIT_BGSAVE_START 的从库列表,记录对应的 fd 信息;
主库调用 fork 生成子进程,并在子进程中将持久化的数据写给对应的 fds ,传输 rdb 前发送标记信息为
"$EOF: $eofmask,传输 rdb 后发送标记信息为$eofmark(其中 $eofmask 为 40 位的随机数);主库的子进程传输数据完成后,通过管道的方式告知父进程相关从库的数据同步状态;
主库的父进程后续将发送堆积的增量数据给从库;
交互流程:与 2.2 PSYNC 方案完全一致;
复制状态机:与 2.2 PSYNC 方案完全一致;
2.4、PSYNC2方案
版本范围:4.0 ~ 5.0.14(以下分析基于 5.0.14 版本)
方案特点:
- 支持同源增量数据同步,解决了切主之后,从库与新主库之间需要进行全量同步的问题;
持久化及传输流程(仅考虑有盘传输):
- 主库调用 fork 生成子进程,并在子进程中将内存中的数据持久化到 rdb 文件中;
- 主库获取所有状态为 WAIT_BGSAVE_END 的从库,为其注册发送 rdb 数据的事件;
- 主库发送 rdb 数据完成后,将发送堆积的增量数据给从库;
交互流程:
主库:
- 接收从库的建连请求;
- 处理从库发送的探测消息,并依次按需给从库回复消息;
- 处理从库发送的 psync replid offset 或 sync 命令,校验 replid 和 offset ,之后主库给从库回复标识以及对应数据,其中标识为:
- 全量同步标识 :
+FULLRESYNC replid offset; - 增量同步标识 :
+CONTINUE或者+CONTINUE replid;
- 全量同步标识 :
从库:
外部对从库执行 slaveof master_ip master_port 操作,从库主动与主库建立连接;
从库向主库发送 ping 命令,并接收回复消息;
从库按需向主库发送 auth 命令,并接收回复消息;
从库向主库发送 replconf listening-port $port 消息,并接收回复消息;
从库按需向主库发送 replconf ip-address $ip 消息,并接收回复消息;
从库向主库发送 replconf capa eof capa psync2 消息,并接收回复消息;
从库向主库发送 psync replid offset 或者 sync 消息,并接收回复消息,从库之后进入全量或增量数据同步;
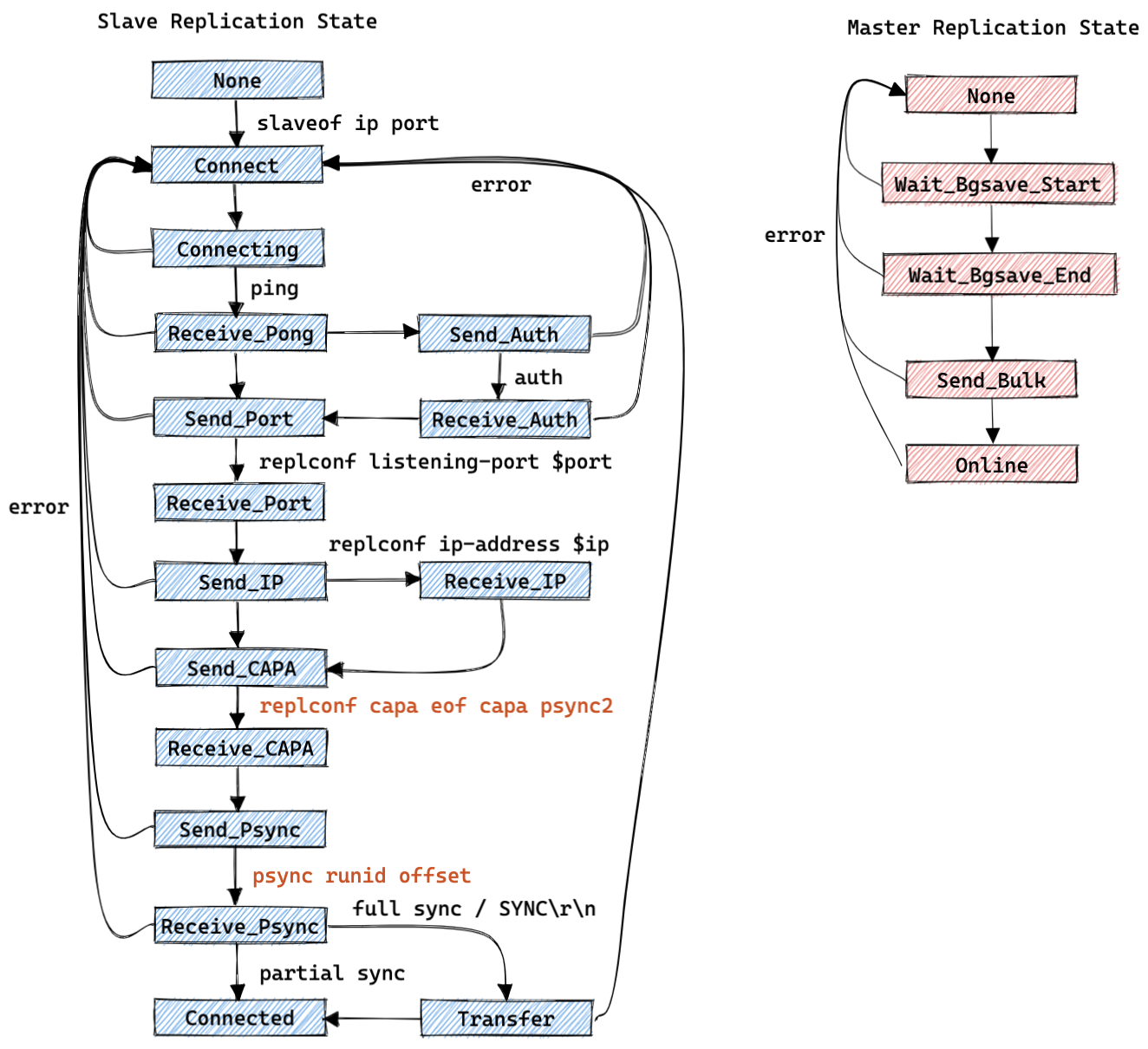
复制状态机:
主库(slave->replstate):
- REPL_STATE_NONE : 创建从库客户端后的初始状态;
- SLAVE_STATE_WAIT_BGSAVE_START : 等待开始生成一个 rdb 数据文件;
- SLAVE_STATE_WAIT_BGSAVE_END : 等待生成一个 rdb 数据文件完成;
- SLAVE_STATE_SEND_BULK : 正在给对应的客户端发送 rdb 数据的状态;
- SLAVE_STATE_ONLINE : 发送完成 rdb 数据后状态;
从库(server.repl_state):
- REPL_STATE_NONE : 初始状态;
- REPL_STATE_CONNECT : 从库执行 slaveof 之后的状态;
- REPL_STATE_CONNECTING : 从库连接主库之后的状态;
- REPL_STATE_RECEIVE_PONG : 从库向主库发送 ping 之后等待接收 pong 时的状态;
- REPL_STATE_SEND_AUTH : 从库接下来按需向主库发送 auth 消息;
- REPL_STATE_RECEIVE_AUTH : 从库向主库发送 auth 之后等待接收返回消息时的状态;
- REPL_STATE_SEND_PORT : 从库接下来要向主库发送 replconf listening-port $port 消息;
- REPL_STATE_RECEIVE_PORT : 从库向主库发送 replconf listening-port $port 之后等待接收返回消息时的状态;
- REPL_STATE_SEND_IP : 从库接下来按需向主库发送 replconf ip-address $ip 消息;
- REPL_STATE_RECEIVE_IP : 从库向主库发送 replconf ip-address $ip 之后等待接收返回消息时的状态;
- REPL_STATE_SEND_CAPA : 从库接下来要向主库发送 replconf capa eof capa psync2 消息;
- REPL_STATE_RECEIVE_CAPA : 从库向主库发送 replconf capa eof capa psync2 之后等待接收返回消息时的状态;
- REPL_STATE_SEND_PSYNC : 从库接下来要向主库发送 psync replid offset 或者 sync 消息;
- REPL_STATE_RECEIVE_PSYNC : 从库向主库发送 psync / sync 之后等待接收返回消息时的状态;
- REPL_STATE_TRANSFER : 从库开始等待接收全量(rdb)的数据;
- REPL_STATE_CONNECTED : 从库开始等待接收增量的数据;
2.4.1、同源增量同步详解
- 关键变量:
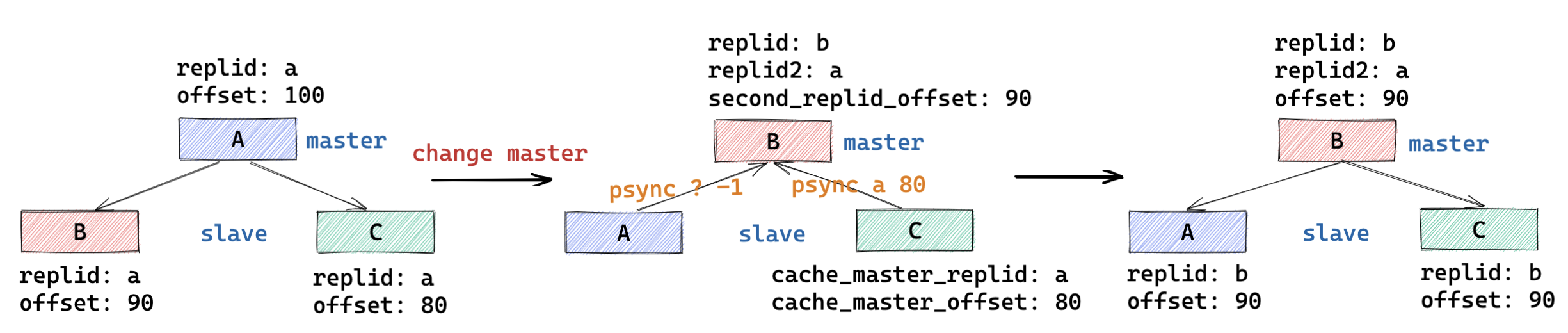
- server.replid : 当前实例对应主库的 replid ,如果当前实例为主库则为其自身的 replid ,该信息会在主从同步交互的流程中同步给从库,该信息会被持久化到 rdb 文件中;
- server.replid2 : 当前实例记录的前一个主库的 replid ;
- server.second_replid_offset : 与 server.replid2 对应,记录的是前一个主库对应的复制 offset 值,用于主库校验从库发起的增量同步请求是否合法;
- server.cached_master :用于记录当前连接的主库信息,用于记录下一次发起增量同步时所需要的信息;
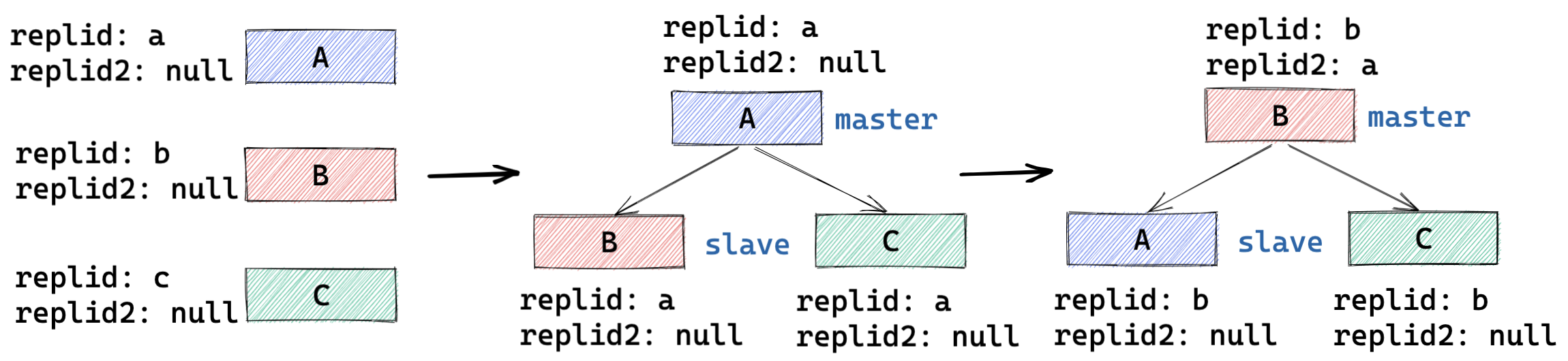
- 主从复制 ID 变更流程:
- 从库 => 主库 : replid 为自己生成新的,replid2 为老主库的 replid ;
- 主库 => 从库 : replid 为新主库的 replid ,replid2 清空;
- 从库 => 从库(变更主库) : replid 为新主库的 replid ,replid2 清空;
2.5、无盘加载方案
版本范围:6.0.0 ~ 6.2.6(以下分析基于 6.2.6 版本)
方案特点:
- 从库支持了无盘加载 rdb 数据,即无需将 rdb 存储到本地后就可以将其数据加载到内存中;
- 从库支持在加载 rdb 数据时使用临时 db 备份之前内存的数据,避免加载的 rdb 数据异常;
无盘加载启用条件(满足其一即可):
- 加载数据前要求备份原始数据(REPL_DISKLESS_LOAD_SWAPDB);
- 本地无任何数据的情况(REPL_DISKLESS_LOAD_WHEN_DB_EMPTY);
数据加载流程(仅考虑无盘加载):
- 从库注册一个读事件 readSyncBulkPayload ,用于从主库接收 rdb 数据;
- 从库根据设定的加载的条件,按需备份本地的 DB 数据;
- 从库不断的从与主库的连接 socket 中读取传输的 rdb 数据,并解析后加载到本地 DB 中;
- 从库根据配置的清理 DB 的策略,异步或同步的清空备份的 DB 数据,完成数据加载;
交互流程:与 PSYNC2 方案的交互流程完全一致;
复制状态机:与 PSYNC2 方案的复制状态机完全一致;
2.6、共享复制缓冲区
版本范围: 7.0.0 ~ 7.0.5(该文章编写时 7.0.5 为最新版,以下分析基于 7.0.5 版本)
方案特点:
- 创造性的将 Backlog 和从库连接的 OutputBuffer 合二为一,节省了多从库场景下的重复内存占用问题;
数据结构设计:
- 默认情况下每一个缓存区块(replBufBlock 节点)的最小 buffer 大小为 16K (PROTO_REPLY_CHUNK_BYTES);
- 默认情况下每添加 64(REPL_BACKLOG_INDEX_PER_BLOCKS) 个缓存区块,就会记录一些快查索引节点;
// server.repl_backlog 的类型变成了 replBacklog* 类型
typedef struct replBacklog {
listNode *ref_repl_buf_node; // 复制缓冲区块的引用节点
size_t unindexed_count; // 从上一次向 blocks_index 添加索引后增加的区块数量
rax *blocks_index; // 用于快速查询的复制缓冲区块的索引集
long long histlen; // 积压缓冲区的实际大小
long long offset; // 复制积压缓冲区中记录的第一个有效字节的偏移值
} replBacklog;
// ref_repl_buf_node 中的每一个节点的数据结构
typedef struct replBufBlock {
int refcount; // 使用该节点的引用计数
long long id; // 复制缓冲区块的唯一编号,递增
long long repl_offset; // 该区块的第一有效字节数据对应的复制偏移值
size_t size, used; // 记录柔性数组对应内存块大小和使用的大小
char buf[]; // 柔性数组存储复制堆积数据
} replBufBlock;
// 客户端连接的数据结构
typedef struct client {
...
listNode *ref_repl_buf_node; // 复制缓冲区块的引用节点
size_t ref_block_pos; // 下一个要发送的偏移量
...
} client;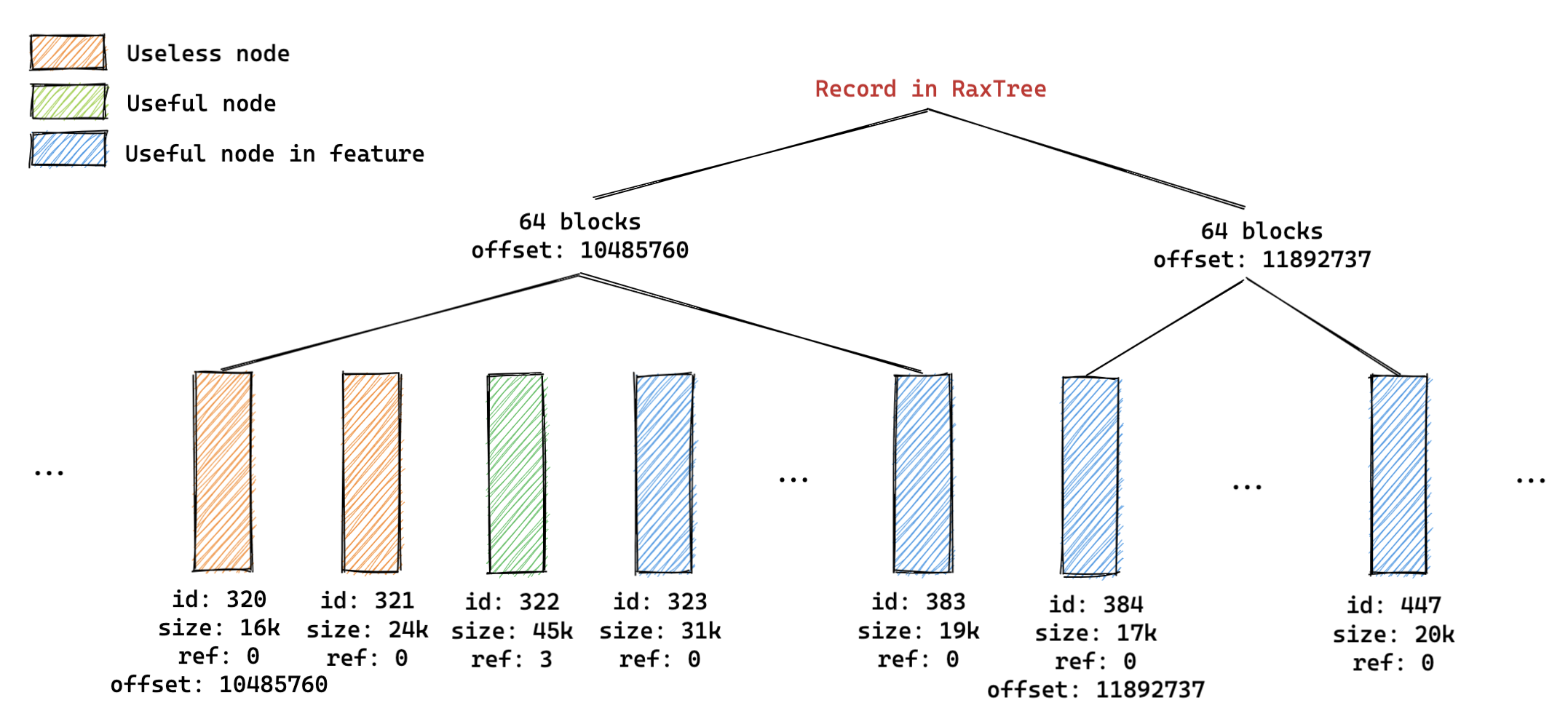
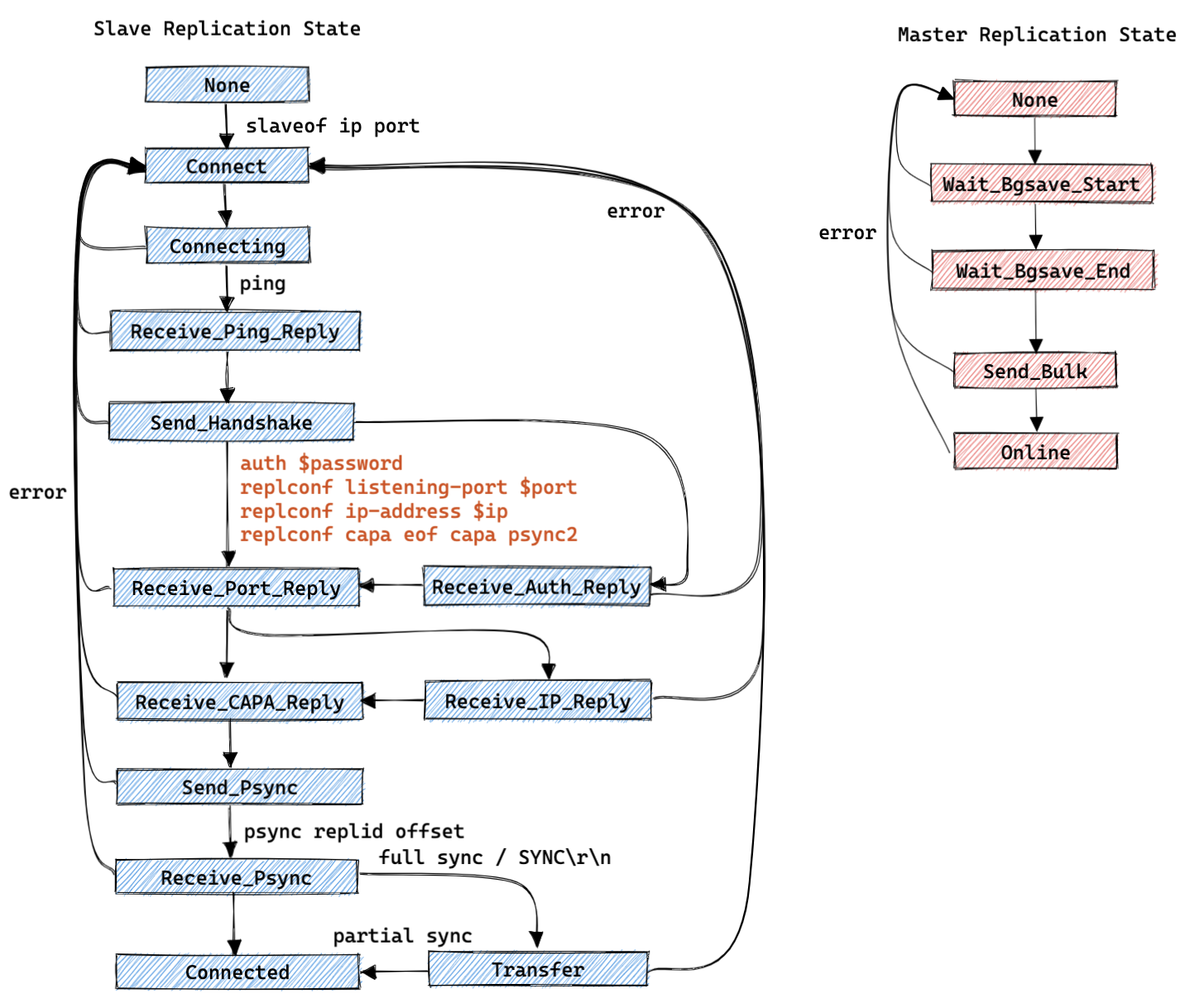
复制状态机:
主库(slave->replstate):
- REPL_STATE_NONE : 创建从库客户端后的初始状态;
- SLAVE_STATE_WAIT_BGSAVE_START : 等待开始生成一个 rdb 数据文件;
- SLAVE_STATE_WAIT_BGSAVE_END : 等待生成一个 rdb 数据文件完成;
- SLAVE_STATE_SEND_BULK : 正在给对应的客户端发送 rdb 数据的状态;
- SLAVE_STATE_ONLINE : 发送完成 rdb 数据后状态;
从库(server.repl_state):
- REPL_STATE_NONE : 初始状态;
- REPL_STATE_CONNECT : 从库执行 slaveof 之后的状态;
- REPL_STATE_CONNECTING : 从库连接主库之后的状态;
- REPL_STATE_RECEIVE_PING_REPLY : 从库向主库发送 ping 之后等待接收 pong 时的状态;
- REPL_STATE_SEND_HANDSHAKE : 从库处于此状态时会依次向主库发送auth(按需), replconf listening-port $port , replconf ip-address $ip (按需), replconf capa eof capa psync2 消息;
- REPL_STATE_RECEIVE_AUTH_REPLY : 从库按需从主库处接收 auth 消息的回复;;
- REPL_STATE_RECEIVE_PORT_REPLY : 从库从主库处接收 replconf listening-port $port 消息的回复;
- REPL_STATE_RECEIVE_IP_REPLY : 从库按需从主库处接收 replconf ip-address $ip 消息的回复;
- REPL_STATE_RECEIVE_CAPA_REPLY : 从库从主库处接收 replconf capa eof capa psync2 消息的回复;;
- REPL_STATE_SEND_PSYNC : 从库接下来要向主库发送 psync replid offset 或者 sync 消息;
- REPL_STATE_RECEIVE_PSYNC_REPLY : 从库向主库发送 psync / sync 之后等待接收返回消息时的状态;
- REPL_STATE_TRANSFER : 从库开始等待接收全量(rdb)的数据;
- REPL_STATE_CONNECTED : 从库开始等待接收增量的数据;
三、奇思妙想
3.1、AOF增量同步方案
我们知道 Redis 实现了基于 Backlog 的增量复制方案,但是考虑到线上实际的资源占用,Backlog 的内存大小通常不会设置的太大。如果 Redis 在写入量很大的情况下出现网络异常导致主从同步中断,从库重连时大概率会由于主库的 Backlog 被冲掉而导致无法进行增量同步的情况。在这种情况下,业界就出现了一些使用 AOF 来扩展 Backlog 数据范围的方案,从而形成了比较典型的基于 AOF 的增量同步方案。
- 方案特点:
- 基于 AOF 文件实现增量的数据同步,支持同步完成 AOF 文件后选择是否切换到 Backlog 的数据同步;
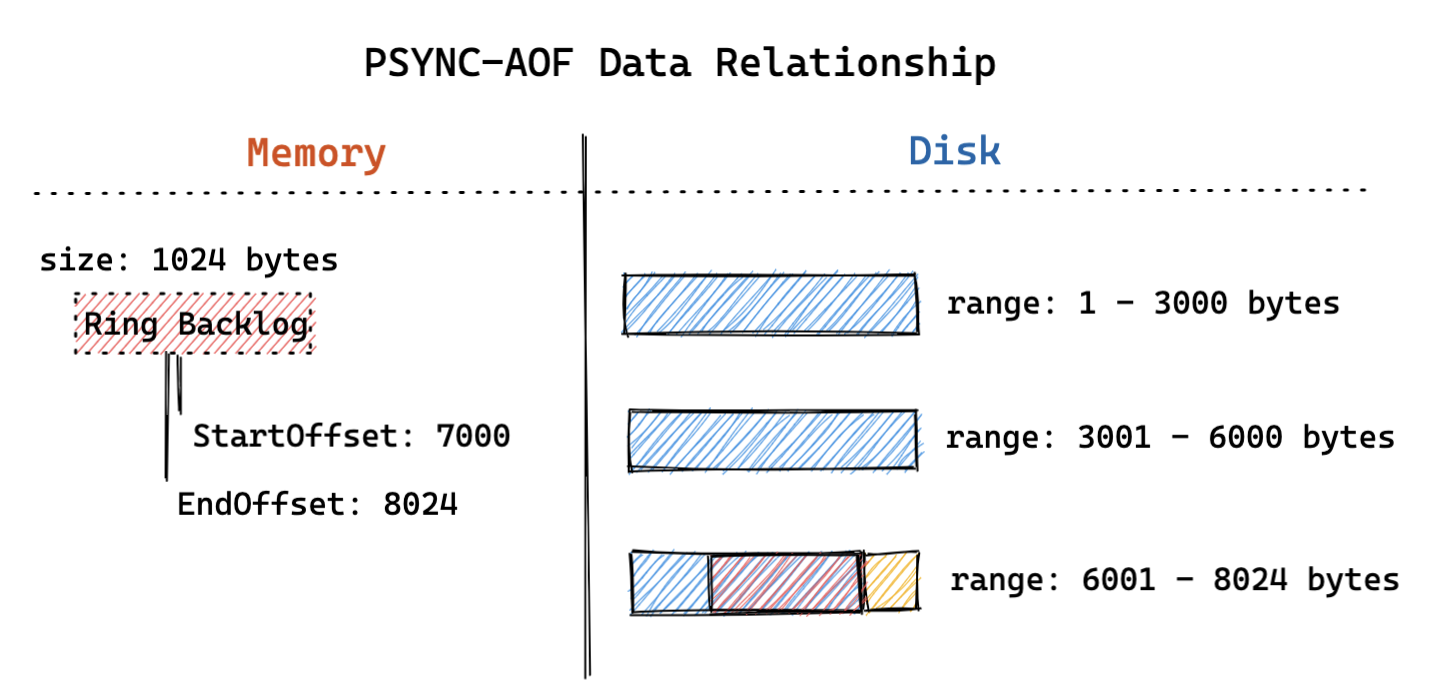
- 持久化流程(AOF 数据持久化):
- 主库关闭重写 AOF 文件,限制单个 AOF 文件大小,允许 AOF 文件按照文件大小进行滚动拆分;
- 主库将与 Backlog 中完全一致的写操作以同步或者异步的方式持久化到 AOF 文件中;
- 主库保证 Backlog 中数据始终可以与最新 AOF 中的一段数据完全对应;
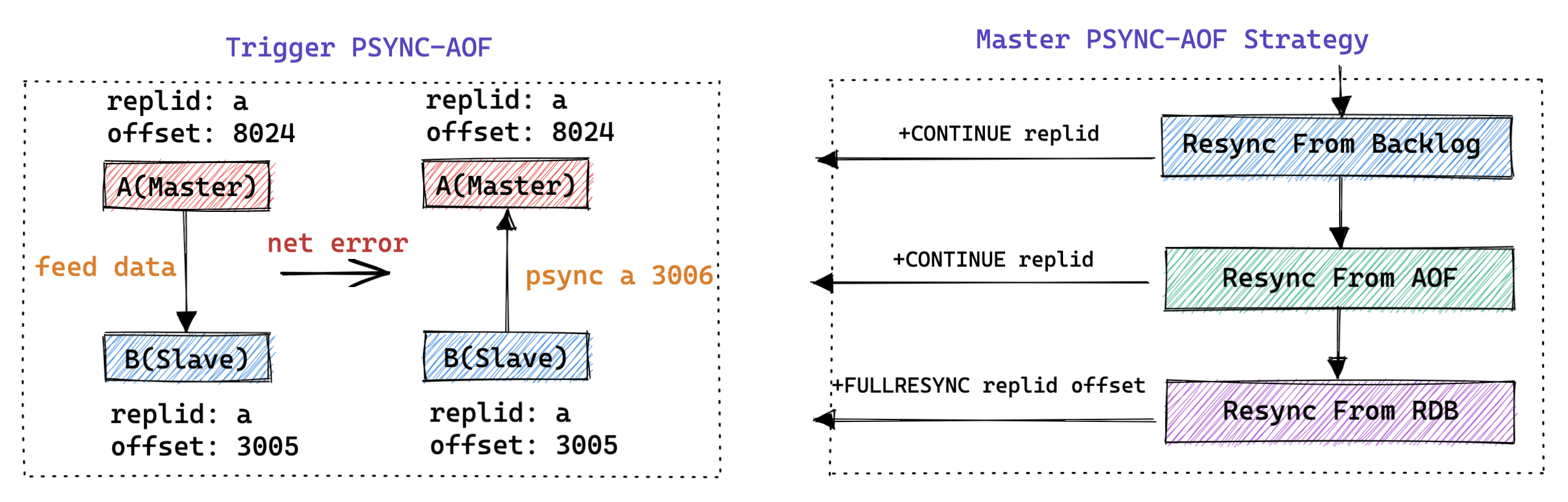
- 增量同步流程:
- 主库处理从库发起的 psync replid offset 增量同步请求,尝试寻找 offset 对应的数据所在的位置;
- 如果 offset 可以在 Backlog 中找到,则可以直接从 Backlog 中进行增量数据同步【主线程直接发送数据】;
- 如果 offset 可以在 AOF 中找到,则可以直接从 AOF 中进行增量数据同步(发送数据文件)【单独线程发送数据】;
- 增量数据同步延迟较小后,后续可以执行两种不同的策略:
- 继续使用独立的线程不断的发送 AOF 中的数据;
- 切换到使用 Backlog 的方式发送后续的增量数据;
- 主库处理从库发起的 psync replid offset 增量同步请求,尝试寻找 offset 对应的数据所在的位置;
3.2、社区的其他讨论
PSYNC3(PSYNC-AOF) 基于 AOF 实现复制:
SYNC-less replication 无全量同步的复制:
Multiplex replication 多路复用复制:
四、参考链接



