Redis异地多活方案杂谈
Redis 的异地多活是一种跨地域容灾、并提供低延迟访问的部署方案。业界提供了很多的构建思路,这里将对比一下这里方案,并详细介绍一下业界的设计与实现。
一、简介
二、思考
2.1、Redis异地多活的定位
在使用 Redis 的异地多活部署方案之前,为了提供 Redis 集群的高可用,我们也会提供跨地域主从的部署方式,通过这种方式我们也能实现地域级别的容灾能力。考虑到业务在使用 Redis 前的关注点一般是:性能、延迟、可用性以及数据一致性,我们将通过这四个关键点来对比一下这两种方案的不同:
- 性能(高性能, QPS ):
- 跨地域主从:跨地域写性能较差,本地域读性能较好;
- 异地多活:本地域读写性能较好;
- 延迟(低延迟, Avg , P99 等):
- 跨地域主从:跨地域写延迟交高,本地域读延迟较低;
- 异地多活:本地域读写延迟较低;
- 可用性(高可用):
- 跨地域主从:集群间的容灾切换,存在主从切换的瞬时访问问题,满足高可用需求;
- 异地多活:集群内的主从故障切换,满足高可用需求;
- 数据一致性:
- 跨地域主从:提供 Redis 的主从同步的数据一致性保障,弱最终一致性(主从数据同步可能会执行失败);
- 异地多活:依赖于同步组件提供的数据一致性保障,基本也符合弱最终一致性;
因此我们可以看到:Redis异地多活的主要定位还是提供低延迟高性能的访问需求,地域级别的容灾只是它的特性之一。
2.2、Redis异地多活的功能
- 集群规模:支持两集群,三集群以及多集群的部署规模;
- 同步性能:能够支撑 Redis 极端负载情况下的数据写入速度;
- 数据一致性:尽可能的满足多集群数据一致性的需求;
- 运维:完善的监控报警,便捷的运维手段;
三、设计
3.1、数据同步
3.1.1、数据同步方式
异地多活架构下一个非常重要的点就是数据要如何同步到其他地域,按照数据流的写入链路,这里提供了几种实现思路:
Proxy 多写:
- 思路:Proxy 在收到客户端写请求之后,不仅将其转发到本地域的 Redis 实例上,还要将其转发到其他地域的 Proxy 上;
- 特点:
- 数据推送模型;
- 前置路由的方式;
- 无需改造 Redis ,适用于该架构下的所有 Redis 版本;
- 仅适用于 Proxy + Redis 的部署架构;
- 案例:未知;
Redis 主动转发:
- 思路:Redis 在收到写请求之后,依据事先设定的转发规则,将其转发到其他地域的 Redis 集群中;
- 特点:
- 数据推送模型;
- 后置路由的方式;
- 适用于 Proxy + Redis 和 RedisCluster 的部署架构;
- 需要改造每个版本的 Redis ,开发成本较高;
- 案例: KeyDB 等;
旁路组件转发(最常用):
- 思路:旁路组件通过伪造 Redis 从库或者其他的方式实时拉取 Redis 数据,然后将其转发到其他地域的 Redis 集群中;
- 特点:
- 数据推 + 拉模型;
- 后置路由的方式;
- 基本与 Redis 解偶(可能需要改造 Redis ),架构上更加清晰,能够实现更多的定制化功能;
- 案例:阿里、百度、携程、京东等;
多主架构:
- 思路:实现 Redis 多主的部署架构,多活集群内部的主库既是本地域集群的主库,也是其他地域集群的从库;
- 特点:
- 数据拉取模型;
- 需要深度改造 Redis ,很多主从复制相关的流程都需要进行变动;
- 案例:未知;
以上几种数据同步方式中,业界主要实现的还是 旁路组件转发 的方案, Proxy 多写 的方式有一些厂商支持,但是并不是专门针对于多活的场景进行开发的,通常是为了业务进行集群升级切换使用的。而 Redis 主动转发 的方案由于需要深度开发改造 Redis ,并且和存储节点耦合的过于严重,目前业界云厂商里面还没有相关的实现,不过 KeyDB 倒是实现了一种类似于这种的 Redis 的双主方案,感兴趣的可以去阅读一下相关的实现。
3.1.2、数据同步架构
多集群部署架构下,集群间数据同步链路的架构对于整个多活集群的可用性有着一些影响,而常用的数据同步结构基本包括如下几种:
- 环形结构:
- 数据流:每个节点(集群)都只有一个数据写入流和一个数据写出流,数据同步呈现单向环式流转;
- 特点:
- 拓扑简易易理解;
- 存在单节点(集群)故障影响全局数据同步的问题;
- 案例:未知;
- 星状结构:
- 数据流:每个节点(集群)都只有一个数据写入流和数据写出流,数据同步全部经由一个中心路由节点进行流转;
- 特点:
- 中心路由节点(集群)可以拥有全局的数据同步视角,进而实现对全局数据流的管控;
- 中心路由节点(集群)的故障会影响全局数据同步;
- 案例:未知;
- 网状结构:
- 数据流:每个节点(集群)都拥有多个数据写入和数据写出流,每个节点(集群)之间都有数据流交互;
- 特点:
- 节点(集群)的故障不会影响其他节点(集群)间的数据同步,不存在中心节点(集群)的故障问题;
- 节点(集群)间的数据同步链路比较复杂,有很高的观测要求;
- 案例:阿里、百度等;
3.2、数据安全
3.2.1、数据回环
3.2.1.1、数据回环问题
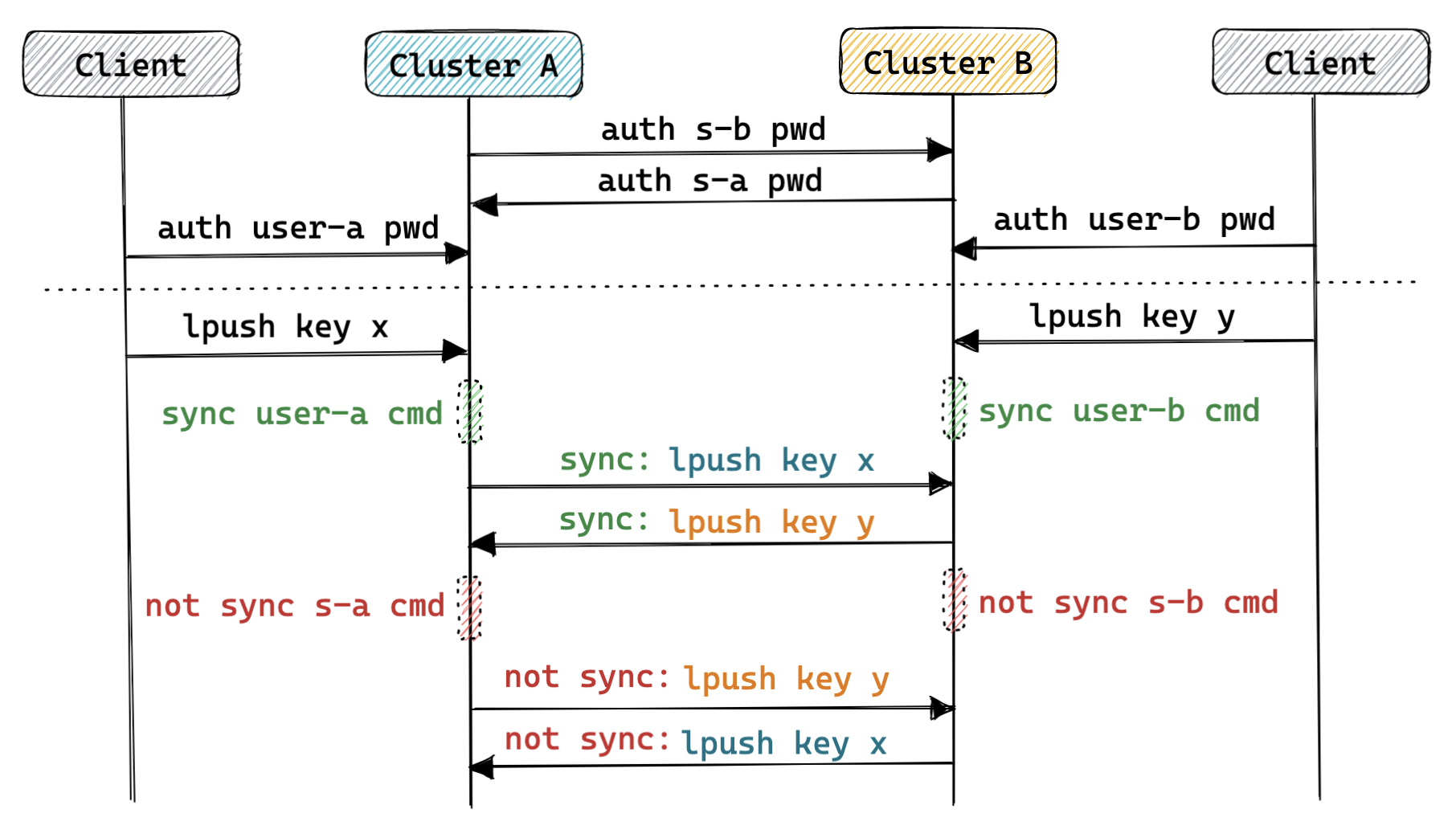
异地多活集群间的数据同步有一个比较典型的问题就是数据回环问题。简单举一个例子,两个集群( A 集群 和 B 集群)进行数据同步时,客户端向 A 集群执行一个写命令后,该命令会被转发写入到 B 集群,如果这时候 B 集群不对写入命令进行区分和过滤,那么 B 集群有可能还会把这个写命令转发给 A 集群,如此循环往复。在这种场景下,这个命令不应该再次被写入 A 集群,这个问题就是 数据回环 。
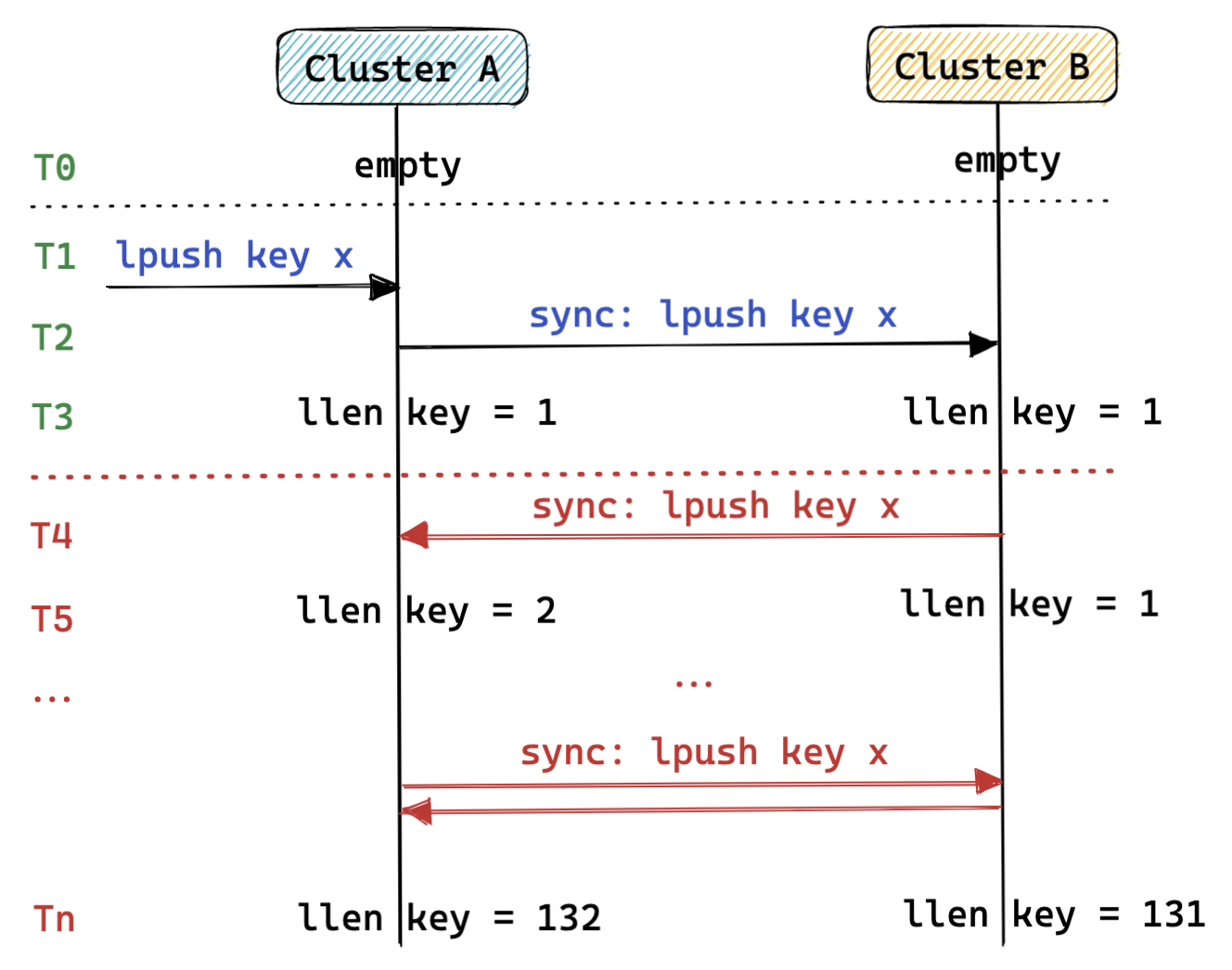
3.2.1.2、数据回环解决方案
为了避免重复转发 Redis 命令,我们需要在转发数据节点阶段添加一些额外的信息用于标记命令的来源,以便于目标集群能够选择性的转发命令,避免出现数据回环问题。
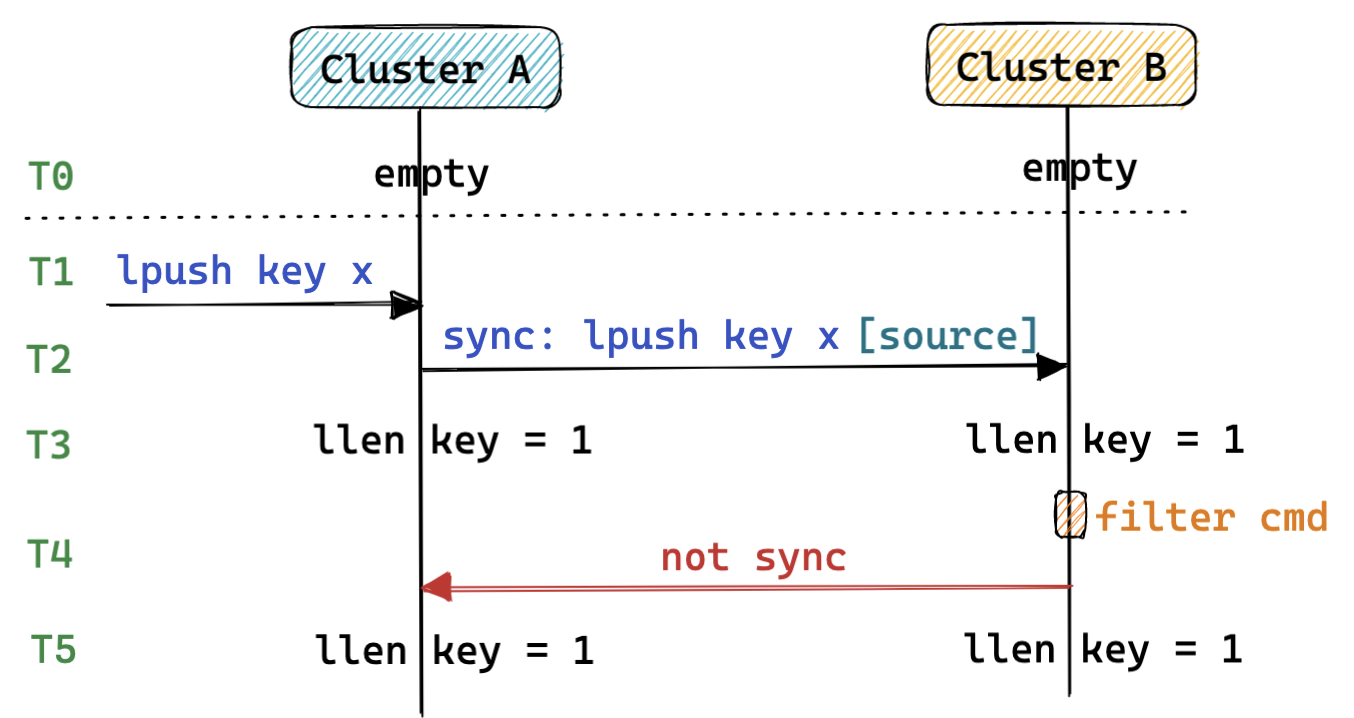
以下列出了几种为了解决数据回环的信息标记方式:
- 改造 RESP 协议(最常用):
- 思路:改造 Redis 的 RESP 协议,通过使用一些字段来标记命令的特征,便于后续选择性的转发命令;
- 特点:
- 严格遵循 Redis 的 RESP 协议规范;
- 自定义的改造空间很大;
- 社区版 Redis 无法识别改造后的命令请求,存在兼容性问题;
- 案例:百度、京东等;
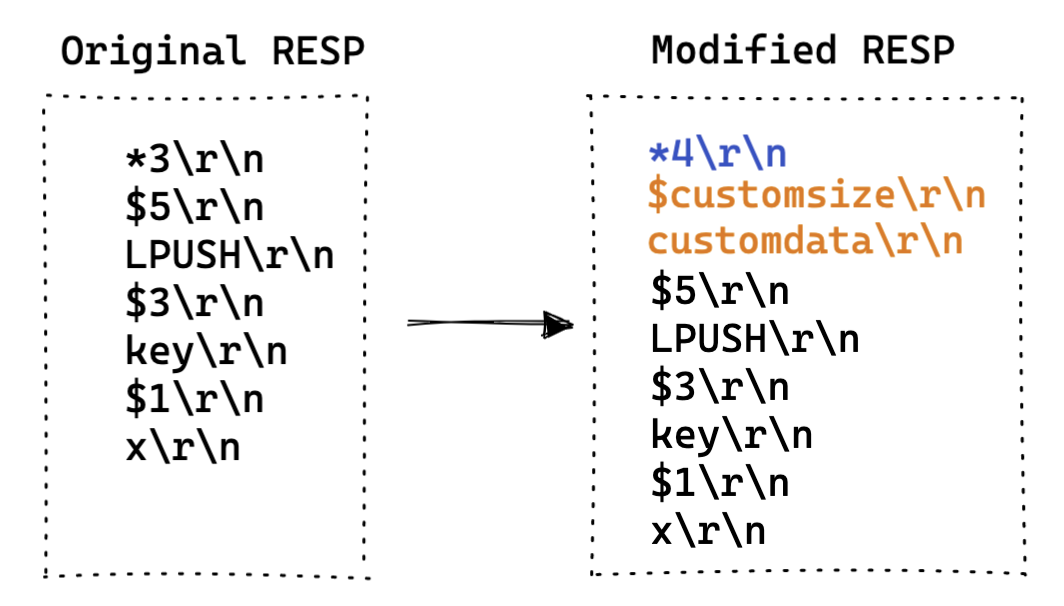
- 自定义命令:
- 思路:
- 每次执行 Redis 命令前/后补充一个自定义的命令,用于标示下一个/上一个命令的特征,便于后续选择性的转发命令;
- 自定义命令的想法也可以和改造 RESP 协议的想法进行结合,即改造命令中新增加的字段就是自定义的命令;
- 特点:
- 严格遵循 Redis 的 RESP 协议规范;
- 自定义命令的改造空间很大;
- Redis 在处理命令时需要记录上下文信息,存在上下文丢失隐患;
- 社区版 Redis 无法识别新添加的自定义命令,存在兼容性问题;
- 案例:未知;
- 思路:
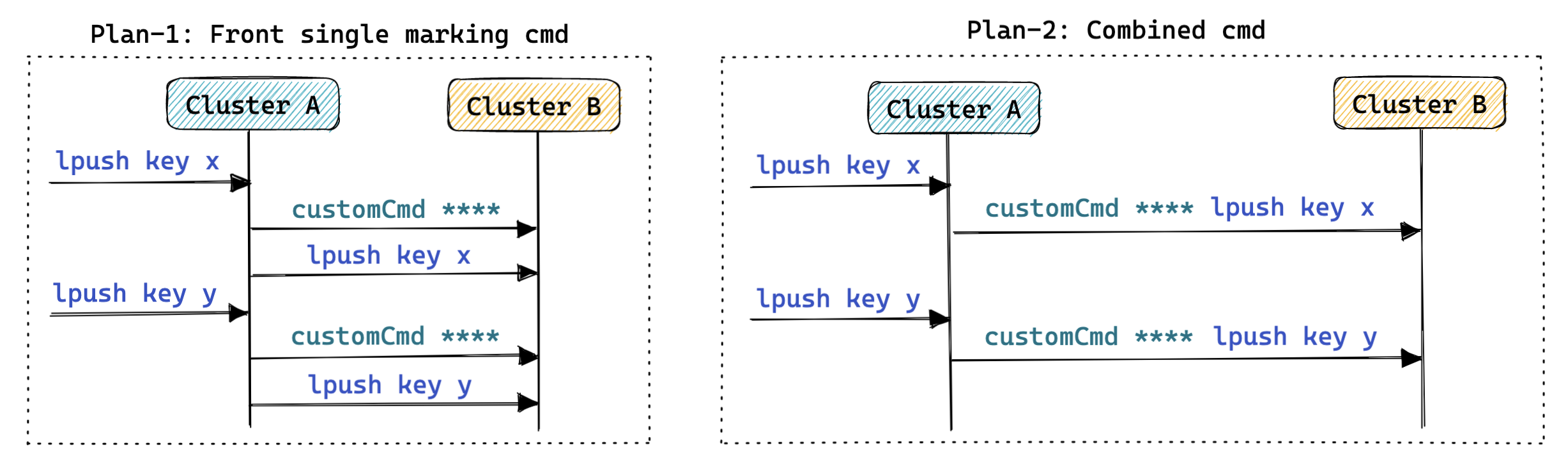
注释:
思路:基于社区版 Redis 的注释功能 Pull/9326 进行扩展,添加更加丰富属性;
特点:
- 能够尽可能的兼容社区版 Redis ;
- 需要考虑 AOF 持久化访问对存量数据注释信息影响;
案例:未知;
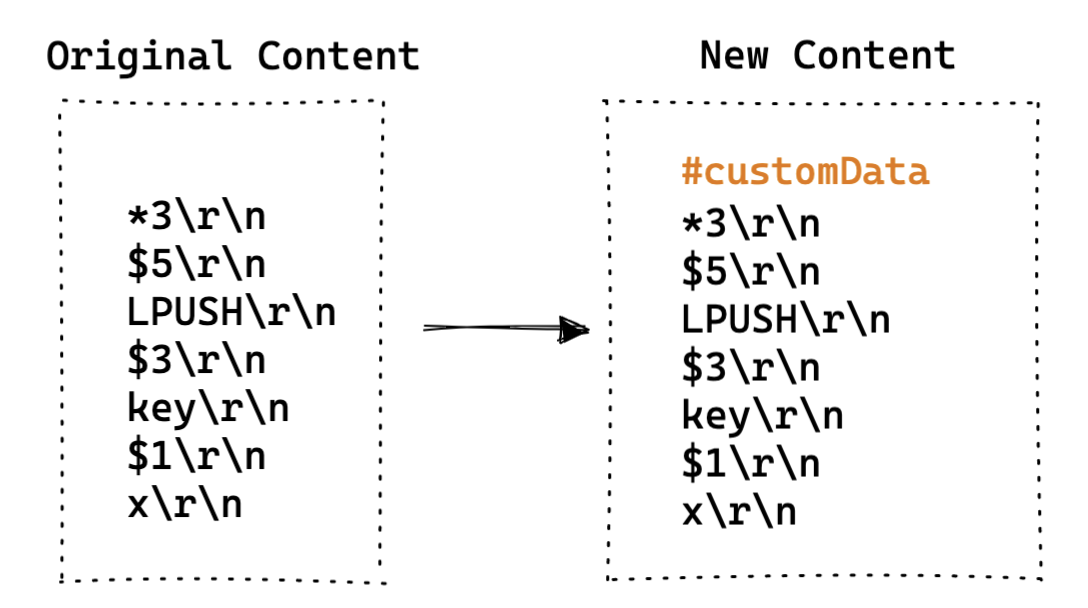
- 特殊连接:
思路:基于 Redis 的 ACL 特性进行改造,从连接维度区分命令的数据来源,针对于不同用户连接上的命令执行不同的处理策略;
特点:
- 不需要变更现有的 Redis 协议或新增命令,完全兼容社区版 Redis ;
- 可能仅能依靠 Redis 资深进行数据同步,无法依赖于外部组件;
案例:未知;
3.2.2、数据重放
在数据同步的过程中不可避免的会由于网络等原因导致命令重发,而考虑到 Redis 的部分命令不是幂等操作的,比如 List 数据类型的相关操作(LPUSH 、 RPUSH 等),对此不加限制就有可能会导致数据不一致的问题,这就会导致 数据重放 问题。在 Redis 主从同步模型中,其实也会出现这个问题,不过目前社区对此的处理方案是:主从同步期间,主库不处理从库的执行结果,并且主库不会主动向从库重发数据。
在 Redis 异地多活的场景下,数据重放的问题主要体现在两个场景中:代码级别的重试 和 断点续传 。代码级别的重试是为了保障同步组件的健壮性,断点续传是为了应对各种故障情况后的数据同步的连续性。业界提供的一些应对数据重放问题的方案与实现:
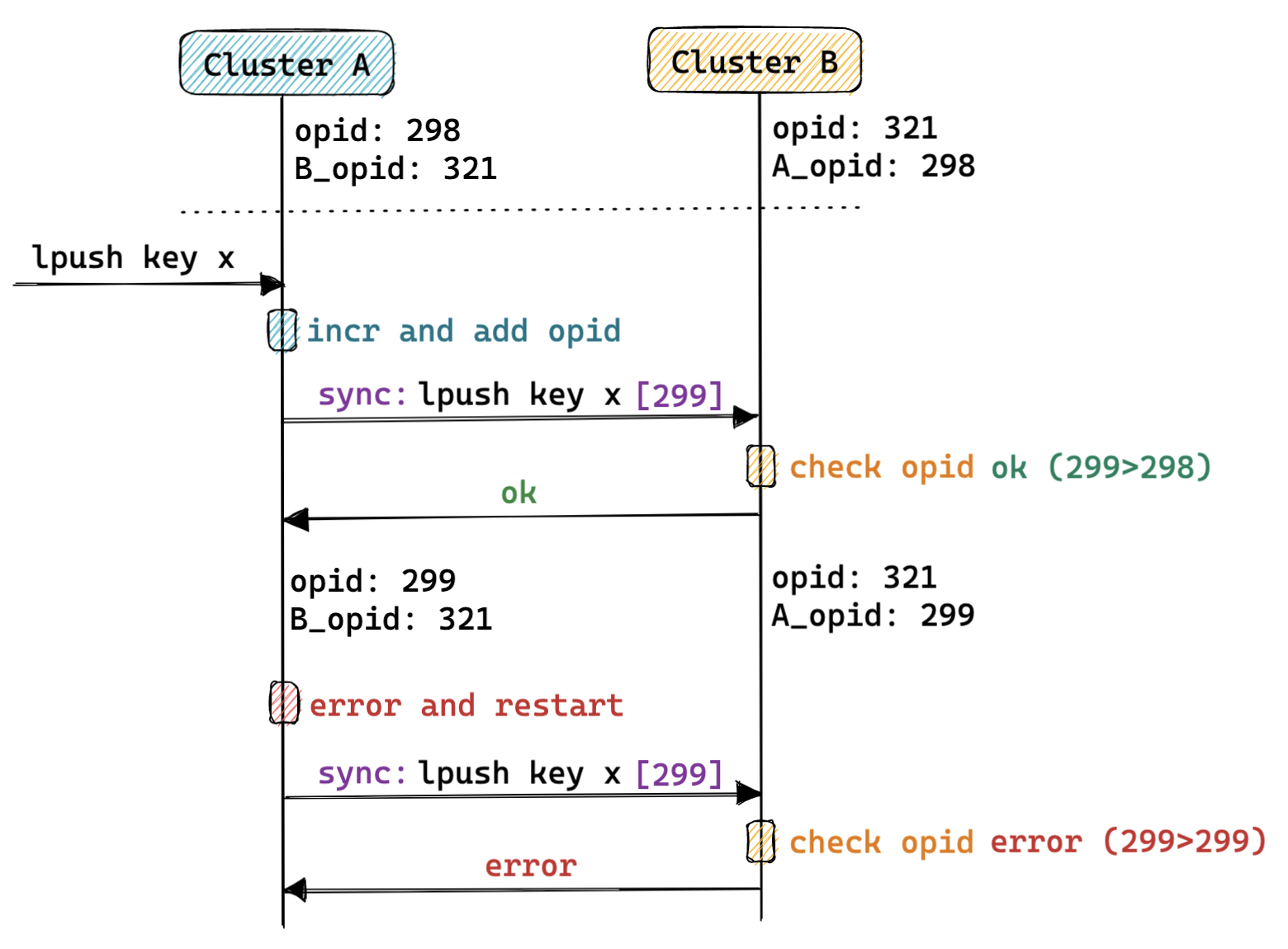
- 命令级别操作序号 :
- 思路:
- 源集群:Redis 在转发命令之前,在命令中添加一些本地递增的命令序号,并将命令序号也转发给目标集群;
- 目标集群:接收到源集群的命令后,会依据上次记录的命令序号判断当前写操作是否合法,并选择是否执行,之后更新记录的命源集群的命令序号;
- 特点:
- 判重的逻辑可以在一个中心转发节点中实现,也可以在 Redis 内部实现;
- 需要考虑 Redis 主从切换等情况的影响;
- 案例:阿里、百度等;
- 思路:
3.2.3、数据冲突
3.2.3.1、CRDT方案
3.2.3.2、Redo/Undo方案
3.2.4、数据修复
3.2.5、数据校验
3.3、高可用
3.4、运维操作
3.4.1、主从切换
3.4.2、纵向扩缩容
3.4.3、横向扩缩容
3.4.4、增删集群
3.5、监控报警
3.5.1、同步延迟
五、业界实践
5.1、阿里异地多活方案
5.2、百度异地多活方案
5.2.1、架构
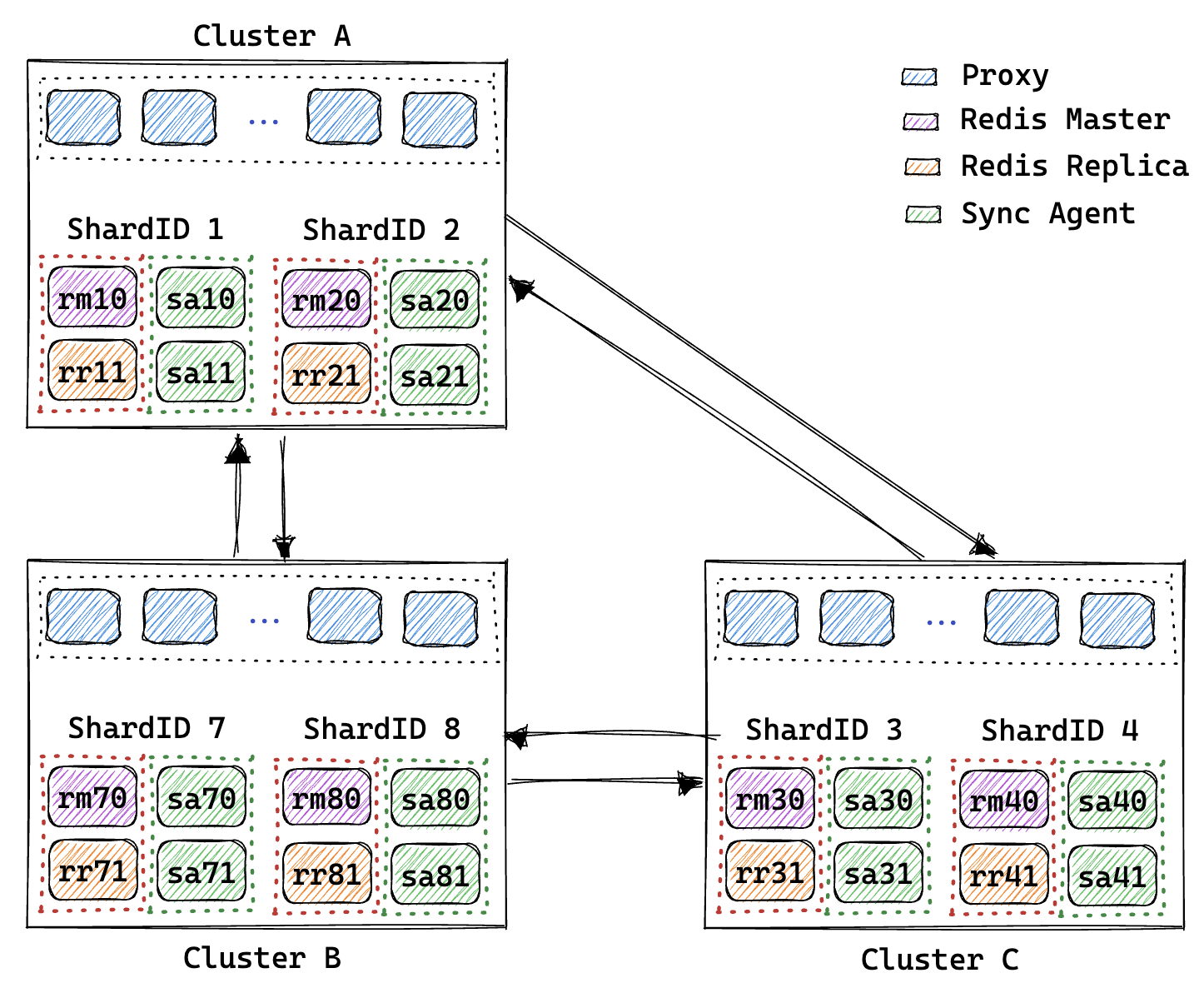
架构图解释:
- 图中展示了三地域 Redis 集群的异地多活架构;
- 每个集群包含两个分片,每个分片中包含一主一从的两个 Redis 节点,每个 Redis 节点对应一个同步组件;
- 每个分片中只有 Redis 主库对应的同步组件处于运行状态(同步数据),当 Redis 出现主从切换后,新主库对应的同步组件会被激活,老主库(此时切换为从库或下线)的同步组件会被停用;
- 每个同步组件都会定期访问其对应的 Redis 实例,从而获取 Redis 的主从状态;
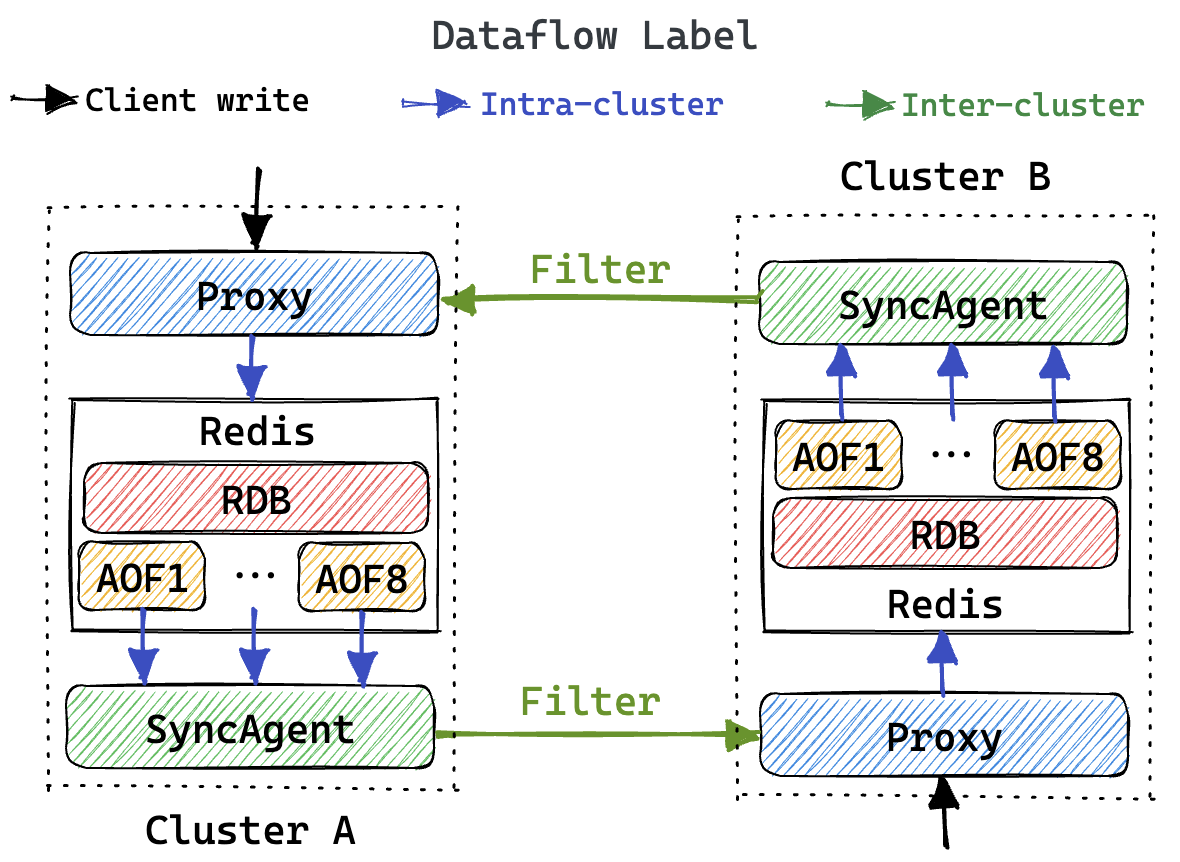
架构图解释:
- 图中展示了两地域 Redis 集群在异地多活架构下的数据同步链路;
- 客户端的写入流量经由 Proxy 转发给集群内部的 Redis 实例;
- Redis 将写入数据持久化到 RDB(定期写入) 和 AOFs(实时写入) 中(定制化的混合持久化机制);
- 同步组件监听获取对应 Redis 实例的增量 AOFs 数据,并在过滤(避免循环复制)后将其转发给目标集群;
5.2.2、特点
5.3、携程异地多活方案
5.4、京东异地多活方案
5.5、银联异地多活方案
六、参考链接



