Ceph Crimson 设计实现深入解析
Crimson 是 Crimson OSD 的代码名称,它是下一代用于多核心可扩展性的 OSD 。它通过快速网络和存储设备提高性能,采用包括 DPDK 和 SPDK 的顶级技术。BlueStore 继续支持 HDD 和 SSD。Crimson 旨在与早期版本的 OSD 守护进程与类 Ceph OSD 兼容。
Crimson 基于 SeaStar C++ 框架构建,是核心 Ceph 对象存储守护进程 OSD 组件的新实现,并替换了 Ceph OSD 。Crimson OSD 最小化延迟并增加 CPU 处理器用量。它使用高性能异步 IO 和新的线程架构,旨在最小化上下文切换和用于跨通信的操作间的线程通信。
以下分析基于 v19.2.1 进行分析。
一、架构对比
Ceph OSD 是 Ceph 集群的一部分,负责通过网络提供对象访问、维护冗余和高可用性,并将对象持久化到本地存储设备。作为 Classic OSD 的重写版本,Crimson OSD 从客户端和其他 OSD 的角度兼容现有的 RADOS 协议,提供相同的接口和功能。Ceph OSD 的模块(例如 Messenger、OSD 服务和 ObjectStore)在其职责上保持不变,但跨组件交互的形式和内部资源管理经过了大幅重构,以应用无共享设计和自下而上的用户空间任务调度。
经典 OSD 的架构对多核处理器并不友好,因为每个组件都包含工作线程池,并且每个组件之间共享队列。举个简单的例子,一个 PG 操作首先需要由一个 Messenger 工作线程处理,将原始数据流组装或解码成一条消息,然后放入消息队列进行调度。之后, PG 工作线程获取该消息,经过必要的处理后,将请求以事务的形式交给 ObjectStore 。事务提交后, PG 将完成操作,并通过发送队列和 Messenger 工作线程再次发送回复。虽然可以通过向池中添加更多线程将工作负载扩展到多个 CPU ,但这些线程默认共享资源,因此需要使用锁,从而引入争用。实际情况会更加复杂,因为每个组件内部都会实现更多的线程池,并且如果跨 OSD 进行复制,数据路径也会更长。
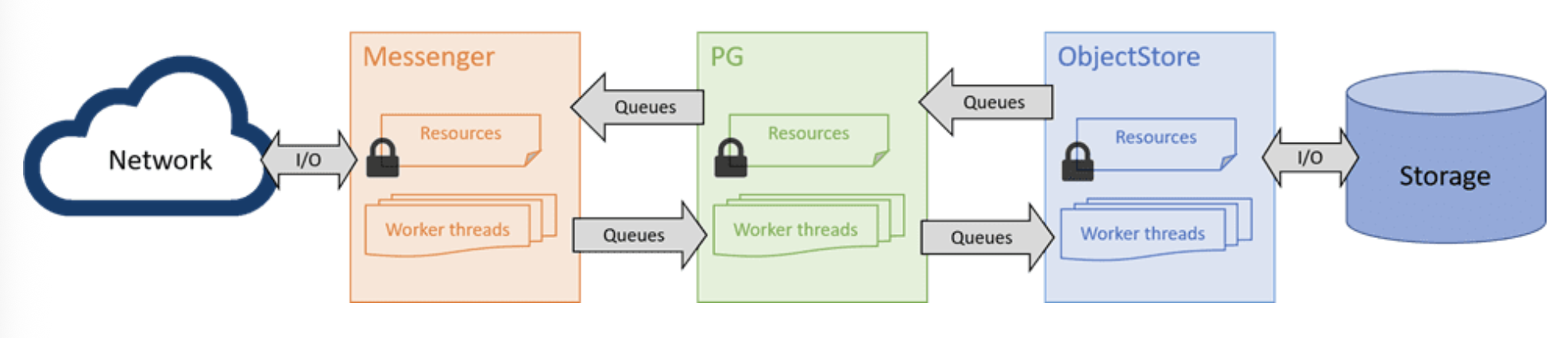
经典架构面临的一个主要挑战是,锁争用开销会随着任务和核心数量的增加而迅速增长,并且每个锁定点在某些情况下都可能成为扩展瓶颈。此外,即使在无争用的情况下,这些锁和队列也会产生延迟成本。多年来,人们在分析和优化更细粒度的资源管理和快速路径实现以跳过排队方面付出了巨大的努力。未来唾手可得的成果将会减少,在类似的设计下,可扩展性似乎正在收敛到某个乘数。此外,还存在其他挑战。由于簿记工作会在工作线程之间委派任务,延迟问题将随着线程池和任务队列的出现而恶化。锁可能会强制上下文切换,这会使情况更加糟糕。
Crimson 项目希望通过无共享设计和运行至完成模型来解决 CPU 的可扩展性问题。该设计的基本原理是强制每个核心(或 CPU)运行一个固定线程,并在用户空间中调度非阻塞任务。请求及其资源按核心进行分片,因此它们可以在同一核心中处理直至完成。理想情况下,所有锁和上下文切换都不再需要,因为每个正在运行的非阻塞任务都拥有 CPU,直到其完成或协同让出。没有其他线程可以同时抢占该任务。如果无需与数据路径中的其他分片通信,则理想的性能将随着核心数量线性扩展,直到 IO 设备达到其极限。这种设计非常适合 Ceph OSD,因为在 OSD 级别,所有 IO 都已按 PG 分片。
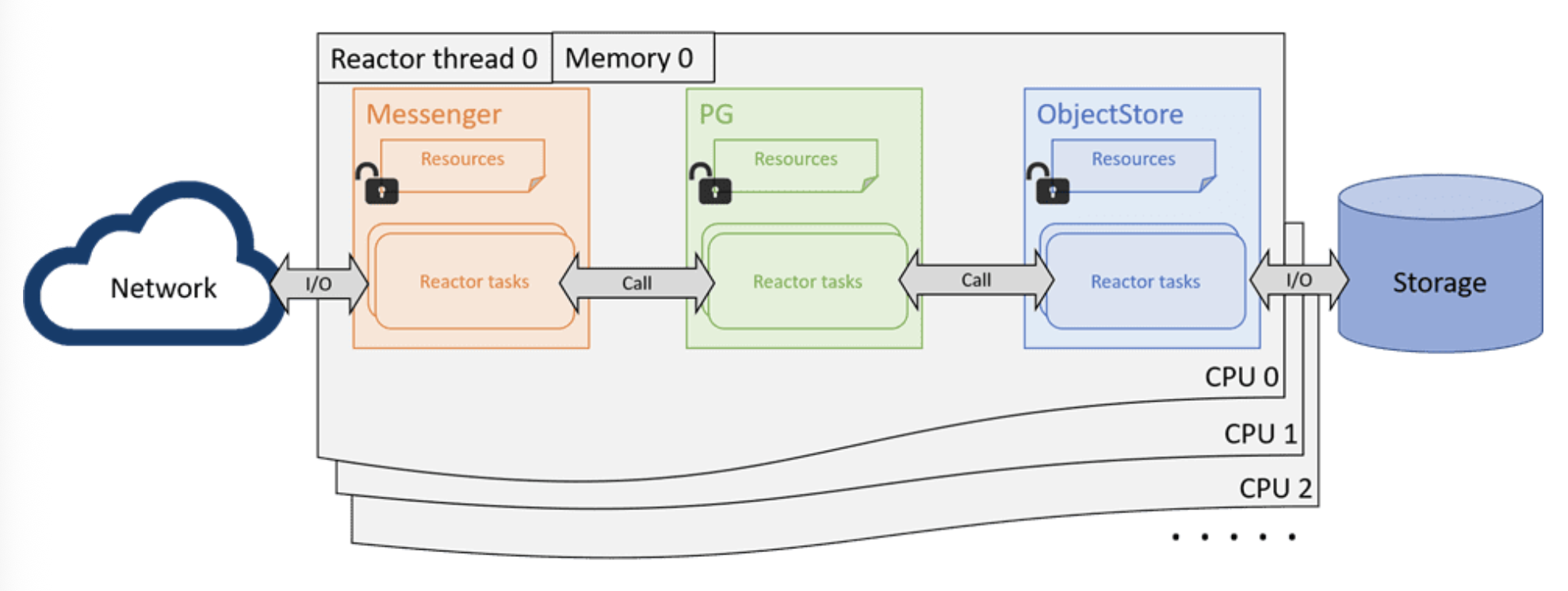
二、配置解析流程
配置解析的代码位于 src/crimson/osd/main.cc 文件中的 auto early_config_result = crimson::osd::get_early_config(argc, argv); 函数,该函数主要逻辑如下:
- 创建一个子进程,在子进程中尝试解析参数后,将参数编码后通过管道传递给父进程;
- 父进程解析并返回参数给 main 函数中;
子进程在 _get_early_config 函数中解析参数,其中 ceph 相关的参数使用 ceph_argparse_early_args 函数解析,并且根据 ceph 的 crimson_seastar_cpu_cores 参数来设置 --cpuset $cpu_cores --thread-affinity 1 ;或者根据 ceph 的 crimson_seastar_num_threads 参数来设置 --smp $smp --thread-affinity 0。注意 crimson_seastar_cpu_cores 参数的优先级高于 crimson_seastar_num_threads 参数。
之后 main 函数中通过 app.run 函数调用,将解析到的参数传递给 seastar ,进而设置了 seastar 要启动的 shard 的数量及绑定 cpu 的配置。但是由于目前 main 中的 seastar::async 函数逻辑中没有显示的使用 seastar::smp::count 来将任务分发给多个 shard 执行,因此关于日志的配置,prometheus 的配置,crimson osd 的对象均是在 shard 0 (即 PRIMARY_CORE )上执行的。
三、网络通信流程
在 crimson osd 进程启动的时候,会调用 OSD::start() 函数,其内部会对 public_msgr 和 cluster_msgr 两个对象执行 bind 和 start 操作。
bind 操作: 对应的函数为SocketMessenger::bind, 该函数内部最终通过调用 seastar 的invoke_on_all下发seastar::listen(s_addr, lo)操作给所有shard,使所有的shard开始监听相同的端口;start 操作: 对应的函数为SocketMessenger::start, 该函数内部通过调用ShardedServerSocket::accept,并在其内部调用 seastar 的invoke_on_all方法使每个 shard 接收新连接请求。每个shard接收到请求后,会逐步调用SocketMessenger::accept=>SocketConnection::start_accept=>ProtocolV2::start_accept=>ProtocolV2::execute_accepting等函数逐步处理请求,最终会调用到OSD::do_ms_dispatch函数正式处理客户端请求。
在 OSD::do_ms_dispatch 函数内部,针对于请求消息的类型,有如下操作:
必须在 PRIMARY_CORE shard 上执行的操作: 包括CEPH_MSG_OSD_MAP、MSG_COMMAND、MSG_OSD_MARK_ME_DOWN等;其他可以在任意 shard 上执行的操作:包括CEPH_MSG_OSD_MAP、CEPH_MSG_OSD_OP、MSG_COMMAND等;
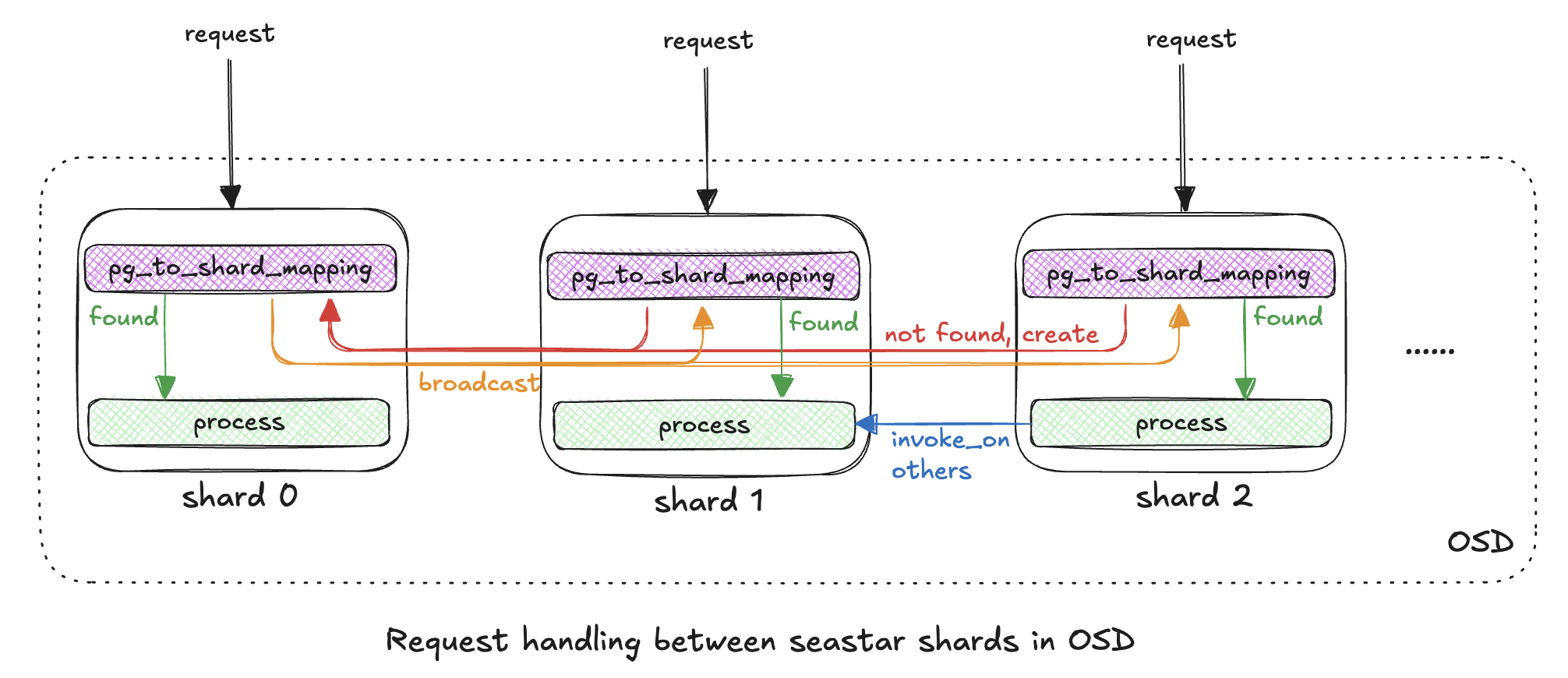
- 由于
OSD中的每个Shard都会监听网络信息,所以每个Shard都可以处理网络请求; - 但是由于需要对请求按照
PG映射到Shard中,所以内部引入了pg_to_shard_mapping的映射结构,每个请求都需要在Shard中检索映射表; - 如果当前
Shard中的映射表中缺少PG的映射信息,会将请求发送给Shard 0来尝试创建对应的映射记录,并将该记录广播给所有的Shard;
对于请求类型为 CEPH_MSG_OSD_OP 的关键代码链路如下:
|
四、线程模型
在服务启动时会通过解析 crimson_seastar_cpu_cores 或 crimson_seastar_num_threads 这两个配置来设置 seastar 框架的并发 shard 数量,之后在 PRIMARY_CORE 初始化环境,并通过 seastar 的 invoke_on、invoke_on_others、invoke_on_all、seastar::smp::submit_to 等方法来给 shard 下发任务,从而实现 osd 中相互独立的 shard 任务模型。
4.1、shard 相关任务
seastar 提供的不同的下发任务的方法比较:
| 接口 | 目标 Shard | 是否依赖 sharded 容器 | 典型用途 |
|---|---|---|---|
invoke_on | 指定单个 Shard | 是 | 访问特定 Shard 上的对象 |
invoke_on_others | 除当前 Shard 外的所有 | 是 | 广播操作(排除当前 Shard) |
invoke_on_all | 所有 Shard(包括当前) | 是 | 全局初始化/清理 |
smp::submit_to | 指定单个 Shard | 否 | 任意跨 Shard 任务 |
invoke_on 的部分操作如下:
|
invoke_on_others 的部分操作如下:
|
invoke_on_all 的部分操作如下:
|
seastar::smp::submit_to 的部分操作如下:
|
4.2、线程示例
当 crimson_seastar_num_threads 设置为 2 的时候,crimson osd 的线程情况:
|
当 crimson_seastar_num_threads 设置为 8 的时候,crimson osd 的线程情况:
|
五、存储模块设计
5.1、后端对象存储类型
main 函数中会通过 crimson::os::FuturizedStore::create 函数来创建 store 对象。根据 osd_objectstore 和 osd_data 参数来配置 store 对象。其中 osd_objectstore 参数指定了后端对象存储的类型,支持的参数有 alienstore/cyanstore/seastore ,默认为 alienstore (即后端存储为 bluestore )。其中 osd_data 参数指定了数据存储目录(比如当使用 vstart.sh 部署集群时,对应的配置默认为 ./build/dev/osd$id )。
对象存储类型:
alienstore: 是 seastar 线程中的一个代理,主要是与 bluestore 进行通信。由于 io 任务会与 bluestore 进行通信,因此无需针对多个 osd 分片进行特殊处理。BlueStore 中没有针对 crimson 的定制,因为 bluestore 依赖于第三方 RocksDB 项目,而该项目仍然采用线程化设计,因此无法真正将其扩展为无共享设计。然而,在 crimson 能够提供经过优化且足够稳定的原生存储后端 seastore 之前,使用合理的开销来换取完善的存储后端解决方案是可以接受的。cyanstore: crimson osd 中的 cyanstore 与 classic osd 中的 memstore 相对应。为了支持多分片,唯一的变化是每个分片创建独立的 cyanstore 实例。一个目标是确保虚拟 IO 操作能够在同一核心中完成,以帮助识别 osd 级别的可扩展性问题(如果有)。另一个目标是在 osd 级别与 Classic 进行直接性能比较,而不会受到 objectstore 的复杂影响。seastore: seastore 是 crimson osd 的原生 objectstore 解决方案,它使用 seastar 框架开发并采用相同的设计原则。
在 seastore 初始化的时候,会根据 seastore_main_device_type 参数来初始化 seastore 主设备,该参数可选值为 SSD/RANDOM_BLOCK_SSD (代码中还实现了 HDD/ZBD ,但是目前并不支持) ,默认为 SSD 。 在调用 Device::make_device(root, d_type) 函数创建 device 的过程中,会针对不同的设备类型又做了一些区分。
seastore 设备类型对比:
| device_type | backend_type | create func |
|---|---|---|
| HDD | backend_type_t::SEGMENTED | SegmentManager::get_segment_manager |
| SSD | backend_type_t::SEGMENTED | SegmentManager::get_segment_manager |
| ZBD | backend_type_t::SEGMENTED | SegmentManager::get_segment_manager |
| RANDOM_BLOCK_SSD | backend_type_t::RANDOM_BLOCK | get_rb_device |
5.2、段存储格式信息
当使用 vstart.sh 脚本部署测试集群后会发现 build/dev/osd*/ 目录下会存在一个 block 文件,该文件对应的就是一个 osd 组件后端的对象存储,由于一个 osd 中可能会启用多个 seastar shard ,并且由于 shard 间数据的隔离,因此需要对这大块存储空间进行切割,使每个 shard 各负责一块空间,从而实现操作数据的隔离。
后端存储的格式化规则:
- 开始部分为 superblock 空间,存储这个该存储空间的规划及使用信息;
- 剩余空间平均分配给每个 shard ,实现独立的操作空间;
创建 superblock 及 shard 空间规划函数如下:
|
六、客户端使用方式
由于 crimson osd 只支持 message v2 协议,所以我们在挂载 cephfs/cephrbd 等的时候需要使用 message v2 的方式。
相关命令:
|
相关代码实现:
|
七、其他特性实现
7.1、冷热存储分离
当使用 vstart.sh 脚本部署测试的时候,我们会发现 --seastore-secondary-devs 和 --seastore-secondary-devs-type 配置,如果指定了这两个参数,该脚本便会通过 dd 格式化对应盘,然后创建 ./dev/osd$id/block.$type.1 目录,之后执行 ln -s $device ./dev/osd$id/block.$type.1/block 创建一个软链文件。详细的代码可以查看: https://github.com/ceph/ceph/blob/v19.2.1/src/vstart.sh#L1194 。
按照官方解释这两个参数是用来指定次要块设备的列表和类型,进一步分析 crimson 官方文档 我们发现这两个配置可用于实现 ceph 的冷热存储分离特性,即随着时间的推移逐步将较快设备(主设备)中的冷数据迁移到较慢的设备(次要设备)中,通常要求次要设备的速度不应该比主设备更快。我们能发现该特性与 Cache Tiering 特性比较相似,之后也会做一下对比分析。
关于主设备剔除数据到次要设备的相关参数:
seastore_multiple_tiers_stop_evict_ratio: 当主设备的使用率低于此值时,停止将冷数据逐出到冷层。默认值为 0.5 。seastore_multiple_tiers_default_evict_ratio: 当主设备的使用率达到此值时,开始将冷数据迁移到次要设备。默认值为 0.6 。seastore_multiple_tiers_fast_evict_ratio: 当主设备的使用率达到此值时,开始执行快速逐出。默认值为 0.7 。
八、模块解析
九、代码逻辑梳理
main 函数中启动的 seastar::async 异步任务的关键逻辑如下:
- 设置日志级别并打开日志文件;
- 启动
prometheus api server; - 创建
client/cluster/hb_front/hb_back消息管理器SocketMessenger; - 创建
store对象; - 创建、初始化、启动
crimson osd对象;
9.1、消息管理器创建逻辑
通过调用 crimson::net::Messenger::create 函数来依次创建 client/cluster/hb_front/hb_back 消息管理器,最终创建的对象类型为 SocketMessenger 。
其中创建 client/cluster 消息对象的时候 dispatch_only_on_this_shard 参数为 false ,意味着接收到的消息可能会交由其他的 shard 进行处理;创建 hb_front/hb_back 消息对象的时候 dispatch_only_on_this_shard 参数为 true ,意味着接收到的消息仅会由当前 shard 处理。
9.2、store 对象创建逻辑
通过调用 crimson::os::FuturizedStore::create 函数来创建 store 对象。根据 osd_objectstore 和 osd_data 参数来配置 store 对象。其中 osd_objectstore 参数指定了后端对象存储的类型,支持的参数有 alienstore/cyanstore/seastore ,默认为 alienstore (即后端存储为 bluestore )。其中 osd_data 参数指定了数据存储目录(比如当使用 vstart.sh 部署集群时,对应的配置默认为 ./build/dev/osd$id )。
crimson 支持以下三个 objectstore 后端:
- alienstore: 提供与早期版本的对象存储(即 BlueStore)的兼容性。
- cyanstore: 用于测试的模拟后端,由易失性内存实施。此对象存储在典型的 osd 中的 memstore 后建模。
- seastore: 为 crimson osd 设计的新对象存储。对多个分片支持的路径因后端的特定目标而异。
9.3、crimson osd mkfs 逻辑
由于在启动 osd 组件之前,我们需要初始化 osd 的文件系统环境,为此需要执行 OSD::mkfs 函数(相关操作顺序可以参考 vstart.sh 脚本中在启动 osd 组件的步骤,其中在启动 osd 之前需要先对其存储路径的环境执行 mkfs 操作。)
OSD::mkfs 函数中关键逻辑为:
|
1. store.start()
由于 store 的类型存在三种: alienstore/cyanstore/seastore , 所以对应的 start 逻辑也有三种。由于 alienstore 只是 bluestore 的代理,且实现比较简单,为此不做介绍;而 cyanstore 是作为一个内存存储模块而存在,仅作为开发测试使用,为此这里也不做介绍;所以以下仅介绍 seastore 的实现逻辑,对应的函数为 SeaStore::start 。
SeaStore::start 函数中关联逻辑为:
|
1. Device::make_device(root, d_type) 逻辑解析:
在 seastore 中有一个 seastore_main_device_type 参数,用于设置 seastore 主设备的类型,可选值为 SSD/RANDOM_BLOCK_SSD (代码中还实现了 HDD/ZBD ,但是目前并不支持) ,默认为 SSD 。
Device::make_device(root, d_type) 函数内部在创建 device 的过程中,会针对不同的设备类型又做了一些区分,详细的类别分类如下:
| device_type | backend_type | create func |
|---|---|---|
| HDD | backend_type_t::SEGMENTED | SegmentManager::get_segment_manager |
| SSD | backend_type_t::SEGMENTED | SegmentManager::get_segment_manager |
| ZBD | backend_type_t::SEGMENTED | SegmentManager::get_segment_manager |
| RANDOM_BLOCK_SSD | backend_type_t::RANDOM_BLOCK | get_rb_device |
由于 seastore_main_device_type 默认为 SSD ,所以会通过 SegmentManager::get_segment_manager 函数来来创建一个 segment_manager::block::BlockSegmentManager 对象。
2. device->start() 逻辑解析:
当执行 device->start() 的时候,调用的就是 BlockSegmentManager::start 方法,继而调用的是 shard_devices.start(device_path, superblock.config.spec.dtype) ,由于 shard_devices 的类型为 seastar::sharded<NVMeBlockDevice> , 所以这里相当于调用了 seastar::sharded::start 函数来初始化了 BlockSegmentManager 对象。
3. shard_stores.start(root, device.get(), is_test) 逻辑解析:
之后的 shard_stores.start(root, device.get(), is_test) 函数执行中,由于 shard_stores 也是一个 seastar::sharded 封装的对象,所以其内部相当于调用了 seastar::sharded::start 函数来初始化了 SeaStore::Shard 对象。
2. store.mount()
store.mount() 函数对应的是 SeaStore::mount 函数。
SeaStore::mount 函数中关键逻辑为:
|
device->mount() 函数对应的是 BlockSegmentManager::mount 函数,这个之前解释过,其内部通过调用 shard_devices.invoke_on_all 来触发在每个 shard 中执行 local_device.shard_mount() 函数,因此每个 shard 中调用的函数其实是 BlockSegmentManager::shard_mount() ,该函数内部的执行逻辑主要包括打开 device ,读取 superblock 信息,校验 superblock 信息,更新 tracker 信息等。
3. open_or_create_meta_coll(store)
open_or_create_meta_coll(store) 对应的函数是 OSD::open_or_create_meta_coll 。
OSD::open_or_create_meta_coll 函数中关键逻辑为:
|
4. _write_superblock(…)
_write_superblock(...) 的完整调用为 _write_superblock(store, std::move(meta_coll), std::move(superblock)) ,其对应的函数是 OSD::_write_superblock 。其内部主要的逻辑为将 superblock 信息写入存储中。
OSD::_write_superblock 函数中关键逻辑为:
|
5. store.write_meta(…)
store.write_meta(…) 对应很多写元信息的操作,操作的元信息包括 ceph_fsid ,magic ,whoami ,osd_key , osdspec_affinity , ready 等字段。这些信息位于 osd 运行目录的各个配置对应的文件中。
6. store.umount()
store.umount() 对应的函数为 SeaStore::umount , 其内部会同通过调用 shard_stores.invoke_on_all 函数,让每个 shard 执行 local_store.umount() 函数。
7. store.stop()
store.stop() 对应的函数为 SeaStore::stop 。
SeaStore::stop 函数中关键逻辑为:
|
9.3.1、store.mkfs(osd_uuid)
SeaStore::mkfs 函数中关键逻辑为:
|
- read_meta(“mkfs_done”)
read_meta("mkfs_done") 用于校验之前是否已经执行过 mkfs 操作,监测方式为读取 store 目录中的 mkfs_done 文件中的内容。
- seastar::open_directory(root)
seastar::open_directory(root) 的逻辑为检索 store 目录中的文件,筛选前缀名为 block. 的文件/目录,通过解析该文件/目录的后缀,从而尝试调用 Device::make_device(path, dtype) 函数来创建对应的 device , 进而操作对应的 device 执行 start 和 mkfs 函数操作。
- device->mkfs(…)
device->mkfs(...) 对应的完整函数为 device->mkfs(device_config_t::create_primary(new_osd_fsid, id, d_type, sds)) , 由于 seastore_main_device_type 默认为 SSD ,所以这里的 device->mkfs 指的是 BlockSegmentManager::mkfs 函数。
BlockSegmentManager::mkfs 函数中关键逻辑为:
|
其中 shard_devices.local().primary_mkfs(sm_config) 对应的函数为 BlockSegmentManager::primary_mkfs 。其内部逻辑如下:
check_create_device(device_path, size): 通过seastar::open_file_dma函数来打开对应的block文件,并通过f.truncate和f.allocate(0, size)函数来调整对应文件的大小,用于后续存储数据。该步骤中的seastore_block_create配置用于控制是否创建block, 该参数默认为true;seastore_device_size配置用于控制block的文件大小,该参数默认为50GB。open_device(device_path): 通过seastar::open_file_dma方法来打开对应的block文件,用于后续的数据操作。make_superblock(get_device_id(), sm_config, stat): 初始化superblock信息。其内部根据seastar::smp::count的数量,seastore_segment_size参数(用于控制单个segment的大小,默认为64M)等信息来初始化superblock信息。write_superblock(get_device_id(), device, sb): 将序列化后的superblock信息写入block的文件头部。device.close(): 关闭打开的device。
之后通过调用 shard_devices.invoke_on_all(...) 函数,该函数是 Seastar 框架中使用的方法,用于在所有的 seastar shard 上执行给定的函数。之后每个 shard 上执行 local_device.shard_mkfs() 函数。其内部回依次打开 device ,读取 superblock 信息,校验 superblock 信息,更新 tracker 信息等;之后便关闭 device 。
- device->mount()
device->mount() 对应的函数为 BlockSegmentManager::mount 。
BlockSegmentManager::mount 函数中关键逻辑为:
|
这里也是通过调用 shard_devices.invoke_on_all 来触发在每个 shard 中执行 local_device.shard_mount() 函数,因此每个 shard 中调用的函数其实是 BlockSegmentManager::shard_mount() ,该函数内部的执行逻辑主要包括打开 device ,读取 superblock 信息,校验 superblock 信息,更新 tracker 信息等。
- local_store.mkfs_managers()
接着又通过调用 shard_stores.invoke_on_all(...) 来触发在每个 shard 中执行 local_store.mkfs_managers() 操作,对应的函数为 SeaStore::Shard::mkfs_managers 。
SeaStore::Shard::mkfs_managers 函数中关键逻辑为:
|
其中 init_managers() 函数指的是 SeaStore::Shard::init_managers() 函数,其内部会初始化 transaction_manager , collection_manager , onode_manager 对象。
transaction_manager: 初始化函数为TransactionManagerRef make_transaction_manager,该对象显然用于管理存储设备上的事务。collection_manager: 初始化函数为FlatCollectionManager::FlatCollectionManager;onode_manager: 初始化函数为FLTreeOnodeManager::FLTreeOnodeManager;
transaction_manager 相关执行逻辑:
transaction_manager->mkfs(): 对应TransactionManager::mkfs函数;transaction_manager->mount(): 对应TransactionManager::mount函数;transaction_manager->with_transaction_intr(...): 对应ExtentCallbackInterface::with_transaction_intr函数;
其中 TransactionManager::mkfs 函数中关键逻辑为:
|
其中 TransactionManager::mount 函数中关键逻辑为:
|
TODO:
onode_manager 相关执行逻辑:
相关操作为 onode_manager->mkfs(t) , 对应的函数为 FLTreeOnodeManager::mkfs 函数。 之后继续调用 Btree::mkfs => Node::mkfs
TODO:
collection_manager 相关执行逻辑:
相关操作为 collection_manager->mkfs(t)
TODO:
- prepare_meta(new_osd_fsid)
prepare_meta(new_osd_fsid) 函数对应的是 SeaStore::prepare_meta 函数,其内部主要是写入一些元信息到对应的数据目录的文件中,包括向 fsid 文件中写入集群 id 信息;向 type 文件中写入后后端存储类型(比如 seastore ) ; 往 mkfs_done 文件中写入 yes 。
- umount()
umount() 函数对应的是 SeaStore::umount 函数,其内部会通过 shard_stores.invoke_on_all 函数通知所有的 shard 执行 local_store.umount() 操作。
9.4、crimson osd start 逻辑
当 osd 通过 mkfs 初始化之后才会被正式的启动,这时候就会调用 OSD::start 函数启动。需要注意该函数内部限制当前的 shard 为 PRIMARY_CORE 。其中 store.start() 和 store.mount() 的执行逻辑之前在 osd mkfs 的逻辑中已经描述过了,这里不再赘述。部分实现比较详细或逻辑接近,因此放在一块一起解释。
OSD::start 函数中关键逻辑为:
|
1. pg_to_shard_mappings.start(…)
pg_to_shard_mappings.start(...) 的原始调用信息为 pg_to_shard_mappings.start(0, seastar::smp::count) 。由于 pg_to_shard_mappings 的定义为 seastar::sharded<PGShardMapping> pg_to_shard_mappings ,因此这里的 start 函数其实是调用 seastar::sharded::start 函数来初始化了 PGShardMapping 对象。在 PGShardMapping 对象初始化的过程中会向其内部的成员变量 std::map<core_id_t, unsigned> core_to_num_pgs 中添加 seastar::smp::count 个元素。
2. osd_singleton_state.start_single(…)
osd_singleton_state.start_single(...) 的原始调用信息为 osd_singleton_state.start_single(whoami, std::ref(*cluster_msgr), std::ref(*public_msgr), std::ref(*monc), std::ref(*mgrc)) 。由于 osd_singleton_state 的定义为 seastar::sharded<OSDSingletonState> osd_singleton_state ,因此这里的 start_single 函数其实是调用了 seastar::sharded::start_single 函数来创建了一个 OSDSingletonState 对象。在 OSDSingletonState 对象初始化的过程中会创建一些 perf 和 recoverystate_perf 对象指针。
3. osd_states.start()
由于 osd_states 的定义为 seastar::sharded<OSDState> osd_states ,因此这里的 start 函数其实是调用 seastar::sharded::start 函数来初始化了 OSDState 对象。
4. shard_services.start(…)
shard_services.start(...) 的原始调用信息为 shard_services.start(std::ref(osd_singleton_state), std::ref(pg_to_shard_mappings), whoami, startup_time, osd_singleton_state.local().perf, osd_singleton_state.local().recoverystate_perf, std::ref(store), std::ref(osd_states)) 。由于 shard_services 的定义为 seastar::sharded<ShardServices> shard_services ,因此这里的 start 函数其实是调用 seastar::sharded::start 函数来初始化了 ShardServices 对象。
5. heartbeat.reset(…)
重置 heartbeat 对象。
6. local_service.report_stats()
该函数的调用被封装在 shard_services.invoke_on_all 内部,意味着这会让每个 shard 执行 local_service.report_stats() 函数。但是只有在 crimson_osd_stat_interval 配置了非零的情况下才会执行该逻辑。 crimson_osd_stat_interval 参数默认为 0 。
7. store.report_stats()
store.report_stats() 对应的函数为 SeaStore::report_stats 。
SeaStore::report_stats 函数中关键逻辑为:
|
8. stats_timer.arm_periodic(…)
stats_timer.arm_periodic(...) 对应的原始调用为 stats_timer.arm_periodic(std::chrono::seconds(stats_seconds)) 。用于设置一个周期性的定时器,该定时器的运行是由 Seastar 框架的事件循环管理的,与函数调用的生命周期无关。
9. open_meta_coll
open_meta_coll 对应的函数为 OSD::open_meta_coll 。需要注意该逻辑仅限 PRIMARY_CORE 对应的 shard 执行。
SeaStore::report_stats 函数中关键逻辑为:
|
10. pg_shard_manager.get_meta_coll().load_superblock()
对应的函数为 OSDMeta::load_superblock 。用于从 store 存储中读取 superblock 信息。
11. pg_shard_manager.set_superblock(superblock)
对应的函数为 PGShardManager::set_superblock 。
PGShardManager::set_superblock 函数中关键逻辑为:
|
12. pg_shard_manager.get_local_map(superblock.current_epoch)
对应的函数为 OSDSingletonState::get_local_map 。
13. pg_shard_manager.update_map(std::move(map))
对应的函数为 PGShardManager::update_map 。
PGShardManager::update_map 函数中关键逻辑为:
|
14. local_service.local_state.osdmap_gate.got_map(…)
原始的调用为 local_service.local_state.osdmap_gate.got_map(osdmap->get_epoch()) , 该函数的调用被封装在 shard_services.invoke_on_all 内部,意味着这会让每个 shard 执行 local_service.local_state.osdmap_gate.got_map(osdmap->get_epoch()) 函数。
15. pg_shard_manager.load_pgs(store)
对应的函数为 PGShardManager::load_pgs 。
PGShardManager::load_pgs 函数中关键逻辑为:
|
16. cluster_msgr 和 public_msgr
对应的批量的原始调用为:
|
pick_addresses 函数执行的时候,其内部仅会选择 message v2 的地址,因此从这里可以看出在 crimson osd 中不支持 message v1 。
bind 函数对应的是 SocketMessenger::bind 。 start 函数对应的是 SocketMessenger::start 。
SocketMessenger::bind 函数中关键逻辑为:
|
从上面中可以看出会让每个 shard 都监听相同的端口。
SocketMessenger::start 函数中关键逻辑为:
|
17. monc 和 mgrc 的 start
对应的批量的原始调用为:
|
其中 monc->start() 对应的函数为 crimson::mon::Client::start 。 mgrc->start() 对应的函数为 crimson::mgr::Client::start 。
crimson::mon::Client::start 函数中关键逻辑为:
|
crimson::mgr::Client::start 函数中关键逻辑为:
|
18. _add_me_to_crush()
该函数对应的是 OSD::_add_me_to_crush 。在该函数中,如果 osd_crush_update_on_start 配置为 true ,则会在 osd 启动时尝试将自己的信息添加到 crush map 中。
OSD::_add_me_to_crush 函数中关键逻辑为:
|
19. monc->renew_subs()
对应的函数为 crimson::mon::Client::renew_subs 。 内部逻辑为向 monitor 发送 CEPH_MSG_MON_SUBSCRIBE 消息,用于订阅 osd_pg_creates , mgrmap , osdmap 的变更消息。
20. heartbeat->start(…)
原始的调用为 heartbeat->start(pick_addresses(CEPH_PICK_ADDRESS_PUBLIC), pick_addresses(CEPH_PICK_ADDRESS_CLUSTER)) , 对应的函数为 Heartbeat::start 。
21. start_asok_admin()
对应的函数为 OSD::start_asok_admin 。 用于创建本地的 socket 文件,并注册可执行的命令。
22. log_client.set_fsid(monc->get_fsid())
设置日志记录中的 fsid 信息。
23. start_boot()
对应的函数为 OSD::start_boot 。
OSD::start_boot 函数中关键逻辑为:
|
十、相关资料
- https://ceph.io/en/news/crimson/
- https://ceph.io/en/news/blog/2023/crimson-multi-core-scalability/
- https://ceph.io/en/news/blog/2025/crimson-T-release/
- https://docs.ceph.com/en/latest/dev/crimson/crimson/
- https://docs.ceph.com/en/latest/cephadm/install/#bootstrap-a-new-cluster
- https://www.51cto.com/article/749735.html
- https://zhuanlan.zhihu.com/p/667949613
- https://docs.redhat.com/zh-cn/documentation/red_hat_ceph_storage/7/html/administration_guide/crimson
- https://ceph.io/en/news/blog/2023/crimson-multi-core-scalability/
- https://www.icviews.cn/semiCommunity/postDetail/6586


