Ceph QoS 机制深入分析
一、CephFS QoS
社区的相关实现:
- 基于 tokenbucket 算法的目录 QoS : https://github.com/ceph/ceph/pull/29266
- 基于 dmclock 算法的 subvolume QoS : 来自日本的 line 公司提出的想法,https://github.com/ceph/ceph/pull/38506 , https://github.com/ceph/ceph/pull/52147
1.1、基于 TokenBucket 算法的目录 QoS
该实现并未合并到主分支。
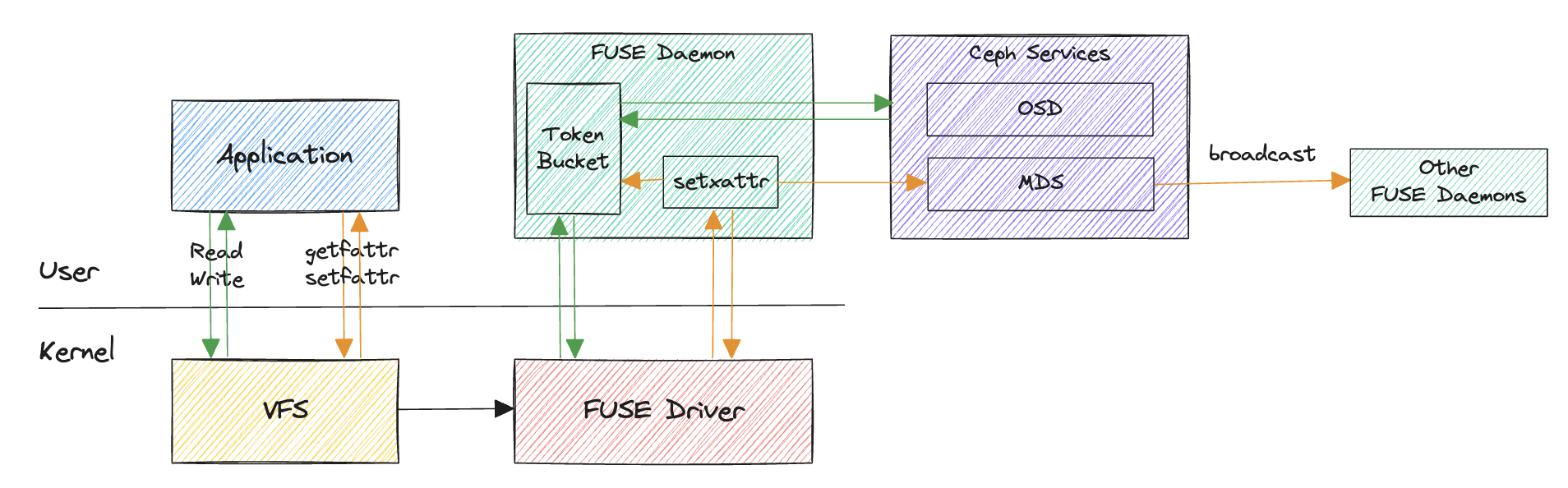
相关材料:
实现特点:
- 基于
TokenBucketThrottle类在客户端侧实现的TokenBucket类型的QoS,用于约束每个独立的客户端的访问请求; QoS的限制粒度为每个独立的客户端,没有全局的QoS限制;- 用于限制目录级别的操作
QoS; - 支持
IOPS和BPS的QoS限制,且支持突发流量; - 仅支持
FUSE类型的挂载方式,该代码未引入 Linux 内核,所以暂不支持Kernel类型的挂载方式;
相关命令:
|
1.2、基于 mclock 算法的 subvolume QoS
该方案是由日本的 Line 公司开发的,该方案已经在他们内部环境线上运行。然后在 2023 年的 Cephalcon 上进行了分享。该实现并未合并到主分支。
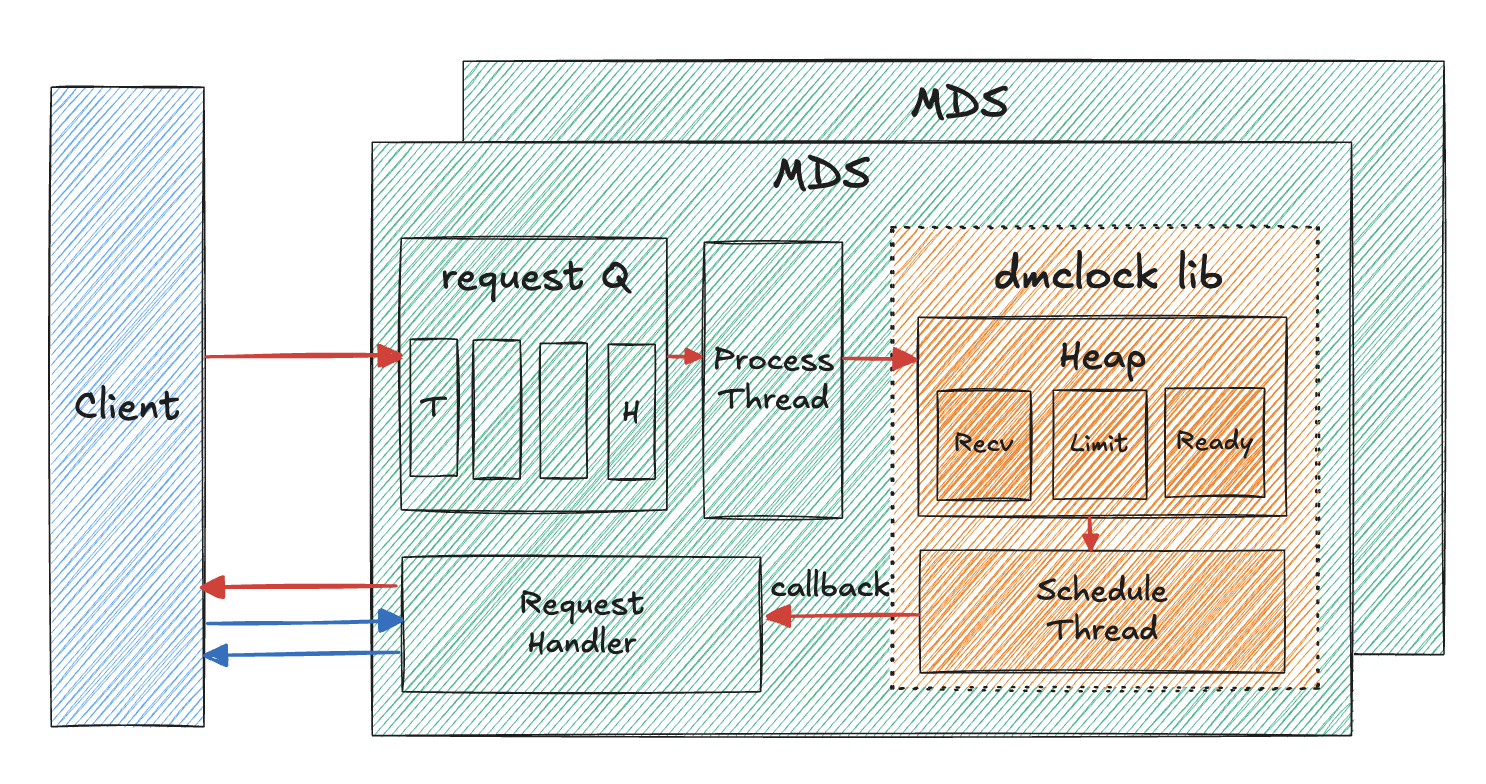
相关材料:
- ceph dmclock 项目代码: https://github.com/ceph/dmclock
- Cephalcon 2023 关于 MDS QoS 的演讲日程: https://ceph2023.sched.com/event/1JKas/optimizing-cephfs-with-combining-mds-qos-scheduling-and-static-dynamic-subtree-partitioning-yongseok-oh-jinmyeong-lee-line
- Cephalcon 2023 关于 MDS QoS 的演讲视频: https://www.youtube.com/watch?v=pDURll6Y-Ug#t=21m07s
- 社区的第一版提交代码: https://github.com/ceph/ceph/pull/38506
- 社区的第二版提交代码: https://github.com/ceph/ceph/pull/52147
- Ceph MDS QoS Tracker: https://tracker.ceph.com/issues/48509
- Ceph MDS QoS 邮件列表讨论记录: https://lists.ceph.io/hyperkitty/list/dev@ceph.io/thread/XO33ZPJ3BONNIKWMGN6A7K62F74C5AJO/
- dmClock: Handling Throughput Variability for Hypervisor IO Scheduling 论文: https://www.usenix.org/legacy/events/osdi10/tech/full_papers/Gulati.pdf
实现特点:
- 从
MDS侧改造支持,无需客户端改造支持; - 限制了客户端对
subvolume的元数据请求(create/mkdir/lookup等)的QoS, 限制粒度为subvolume; - 如果多个客户端挂载了相同的
subvolume,则多个客户端的综合性能之和满足对应的subvolume的QoS限制; - 多个
MDS均可针对不同的subvolume配置对应的QoS,但是MDS间该配置相互独立,所以虽然社区PR中叫做dmclock,但是目前使用的仍是mclock的逻辑; - 只有
active的MDS才会尝试开启该特性,如果对应的MDS状态发生了变化,该特性也会尝试开启或者关闭; - 处理客户端请求时,会解析对应请求所属的
subvolume, 从而判断是否执行QoS约束限制; dmclock的后端实现依赖于crimson::dmclock::PushPriorityQueue类的实现, 相关代码位于src/dmclock/src/dmclock_server.h文件中的crimson::dmclock::PriorityQueueBase::do_add_request函数;
相关配置:
- 全局配置:
mds_dmclock_enable: 使用启用dmclock的QoS功能, 默认为false;mds_dmclock_limit: 限制每个subvolume的QoS的上限,默认值为1000, 需要使用qos set命令来操作开启subvolume的该配置;mds_dmclock_reservation: 限制每个subvolume的QoS的预留值,默认值为1000, 需要使用qos set命令来操作开启subvolume的该配置;mds_dmclock_weight: 限制每个subvolume的QoS的权重,默认值为1000, 需要使用qos set命令来操作开启subvolume的该配置;
- subvolume 配置:
limit: 限制每个subvolume的QoS的上限,该值需不小于reservation;reservation: 限制每个subvolume的QoS的预留值;weight: 限制每个subvolume的QoS的权重;
相关命令:
|
1.3、基于 mclock 算法 user QoS
该方案相比于 1.2、基于 mclock 算法的 subvolume QoS 的实现,限制的粒度有所不同,1.2 中提到的限制粒度是基于 subvolume ,而该方案中限制 auth user ,后端的具体实现基本一致。
实现特点:
- 限制粒度为 auth user ,可针对不同的用户自定义访问 QoS ;
- 不依赖于 subvolume 的特性,即使业务不使用 subvolume 也能使用;
- 在多 MDS 的情况下,由于用户的访问请求可能会打到不同的 MDS 上,并且目前 MDS 间没有针对于用户的总访问请求进行沟通(即后端 MDS 对于 QoS 的限制是相互独立的),所以可能需要针对用户的访问目录进行一定的约束,或者在限制用户的总 QoS 的数量时考虑除以特定的 MDS 的数量来进行均摊访问限制;
二、CephRBD QoS
以下分析基于 Ceph V18.2.7 分支代码。
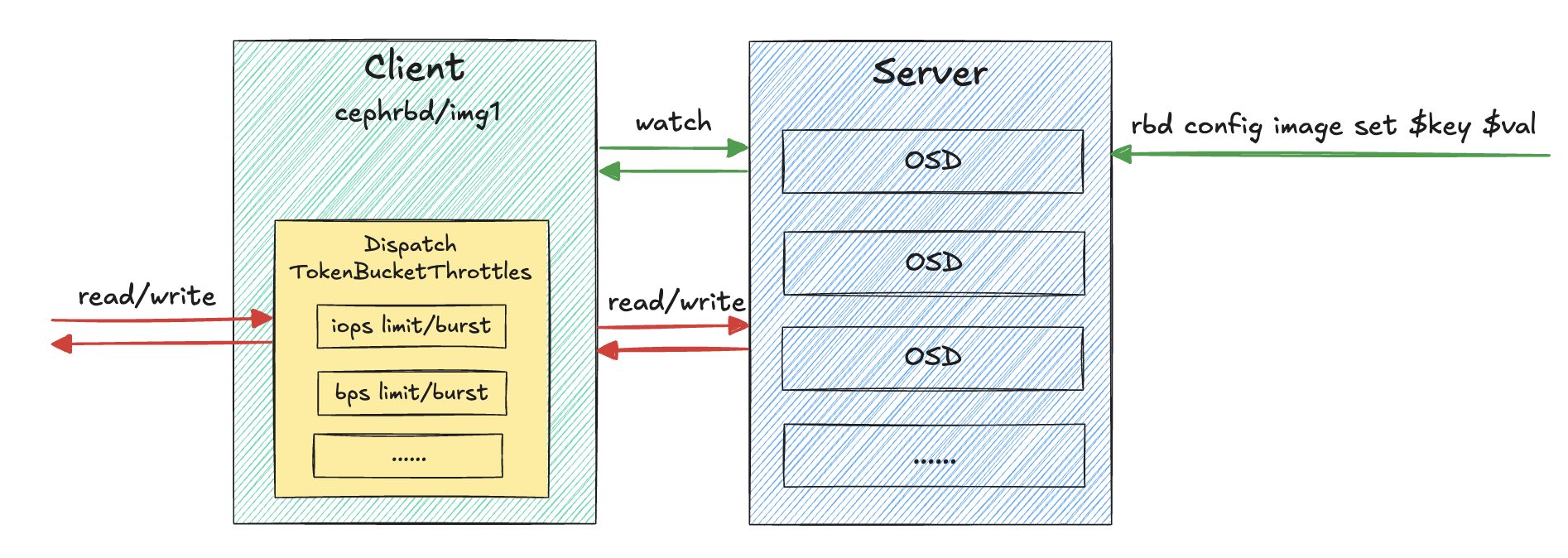
相关材料:
- Ceph RBD QoS 的资料: https://docs.ceph.com/en/latest/rbd/rbd-config-ref/#qos-settings
- 相关PR: https://github.com/ceph/ceph/pull/17032 , https://github.com/ceph/ceph/pull/21635
实现特点:
- 基于 TokenBucket 实现的 QoS;
- 在客户端侧进行实现,每个客户端之间的限制互不关联,相互独立;
- 当启用多个限制条件时,最终会依据配置的最严格的限制条件;
- 配置信息以 OMAP 的方式存储在对应 pool 中的 image 的 header 对象中,可以通过
rbd info ceph-rbd/rbd01.img命令查看block_name_prefix字段中的后缀信息,之后使用rados -p ceph-rbd listomapvals rbd_header.$postfix命令来获取已经设置过的配置信息;
相关配置:
rbd_qos_iops_limit: 每秒 IO 操作的期望限制,默认为 0 ;rbd_qos_iops_burst: 所需的 IO 操作突发限制,默认为 0 ;rbd_qos_iops_burst_seconds: IO 操作所需的突发持续时间(以秒为单位),默认为 1秒 ;rbd_qos_read_iops_limit: 每秒读取操作的期望限制,默认为 0 ;rbd_qos_read_iops_burst: 所需的读取操作突发限制,默认为 0 ;rbd_qos_read_iops_burst_seconds: 读取操作所需的突发持续时间(以秒为单位),默认为 1秒 ;rbd_qos_write_iops_limit: 每秒写入操作的期望限制,默认为 0 ;rbd_qos_write_iops_burst: 所需的写入操作突发限制,默认为 0 ;rbd_qos_write_iops_burst_seconds: 写入操作所需的突发持续时间(以秒为单位),默认为 1秒 ;rbd_qos_bps_limit: 每秒 IO 字节数的期望限制,默认为 0 ;rbd_qos_bps_burst: 所需的 IO 字节突发限制,默认为 0 ;rbd_qos_bps_burst_seconds: 所需的 IO 字节突发持续时间(以秒为单位),默认为 1秒 ;rbd_qos_read_bps_limit: 每秒读取字节数的期望限制,默认为 0 ;rbd_qos_read_bps_burst: 所需的读取字节突发限制,默认为 0 ;rbd_qos_read_bps_burst_seconds: 所需的读取字节突发持续时间(以秒为单位),默认为 1秒 ;rbd_qos_write_bps_limit: 每秒写入字节数的期望限制,默认为 0 ;rbd_qos_write_bps_burst: 所需的写入字节突发限制,默认为 0 ;rbd_qos_write_bps_burst_seconds: 所需的写入字节突发持续时间(以秒为单位),默认为 1秒 ;rbd_qos_schedule_tick_min: 这决定了当达到节流阀的限制时,I/O 可以解除阻塞的最短时间(以毫秒为单位)。就令牌桶算法而言,这是将令牌添加到桶中的最小间隔。默认为 50秒;rbd_qos_exclude_ops: 可选地从 QoS 中排除操作。此设置接受整数位掩码值或以逗号分隔的操作名称字符串。此设置始终在内部存储为整数位掩码值。操作位掩码值和操作名称之间的映射如下:+1 -> read,+2 -> write,+4 -> discreply,+8 -> write_same,+16 -> compare_and_write ;
相关命令:
|
三、CephRGW QoS
以下分析基于 Ceph V18.2.7 分支代码。
相关材料:
- Ceph RGW QoS 的资料: https://docs.ceph.com/en/latest/radosgw/config-ref/#qos-settings
- 基于 mClock 的 QoS: https://docs.ceph.com/en/reef/rados/configuration/osd-config-ref/#dmclock-qos
实现特点:
- 从 Nautilus 版本中引入,当前最新代码尚处于实验阶段,不建议用于生产环境;
- 基于 mClock 实现的 QoS ,后端 mclock 的实现采用
crimson::dmclock::PullPriorityQueue类; - 当 osd_op_queue 配置的值为 mclock_scheduler 时才会启用 mclock 算法;如果使用 throttler 调度器则只是一个普通的限流器,用于判断是否返回到达限制错误,没有使用 mclock 的算法实现;
- 每次调度请求时,先会调用
PullPriorityQueue::add_request函数记录请求,之后会立刻通过AsyncScheduler::process函数来调用PullPriorityQueue::pull_request函数处理请求; - 该 mclock 实现的是不同的请求类别(admin/auth/data/metadata)间的 QoS 控制,详细对应的 OP 操作类别关系如下:
- admin 请求类别对应的操作为
RGWGetClusterStat/RGWRESTOp; - auth 请求类别对应的操作为
RGW_SWIFT_Auth_Get; - data 请求类别对应的操作为
RGWGetObj/RGWBulkDelete/RGWBulkUploadOp/RGWPutObj/RGWPostObj/RGWDeleteObj/RGWCopyObj; - metadata 请求类别对应的操作为
RGWOp/RGWGetBucketPolicyStatus/RGWPutBucketPublicAccessBlock/RGWGetBucketPublicAccessBlock/RGWDeleteBucketPublicAccessBlock;
- admin 请求类别对应的操作为
相关配置:
rgw_scheduler_type: 使用的 RGW 调度程序。可选值为 throttler 和 dmclock ,默认值为 throttler 。 当使用 dmclock 时会采用dmc::AsyncScheduler调度器, 当使用 throttler 时会采用dmc::SimpleThrottler调度器;rgw_max_concurrent_requests: Beast 前端能够处理的最大并发 HTTP 请求数。调整此值有助于限制高负载下的内存使用量。默认值为 1024 ;- 当 rgw_scheduler_type 配置为 throttler 时, 该值用于限制同时最大请求的数量,超过此值会快速失败,并返回客户端
-ERR_RATE_LIMITED错误,如果没有到达最大限制,则会正常执行; - 当 rgw_scheduler_type 配置为 dmclock 时,
- 当 rgw_scheduler_type 配置为 throttler 时, 该值用于限制同时最大请求的数量,超过此值会快速失败,并返回客户端
rgw_dmclock_admin_res: mclock 预留给管理员请求,默认值为 100.0 ;rgw_dmclock_admin_wgt: 管理请求的 mclock 权重,默认值为 100.0 ;rgw_dmclock_admin_lim: 管理请求的 mclock 限制,默认值为 0.0 ;rgw_dmclock_auth_res: 对象数据请求的 mclock 保留,默认值为 200.0 ;rgw_dmclock_auth_wgt: 对象数据请求的 mclock 权重,默认值为 100.0 ;rgw_dmclock_auth_lim: 对象数据请求的 mclock 限制,默认值为 0.0 ;rgw_dmclock_data_res: 用于对象数据请求的 mclock 保留,默认值为 500.0 ;rgw_dmclock_data_wgt: 对象数据请求的 mclock 权重,默认值为 500.0 ;rgw_dmclock_data_lim: 用于元数据请求的 mclock 预留,默认值为 0.0 ;rgw_dmclock_metadata_res: 用于元数据请求的 mclock 预留,默认值为 500.0 ;rgw_dmclock_metadata_wgt: 元数据请求的 mclock 权重,默认值为 500.0 ;rgw_dmclock_metadata_lim: 元数据请求的 mclock 限制,默认值为 0.0 ;
相关命令:
|
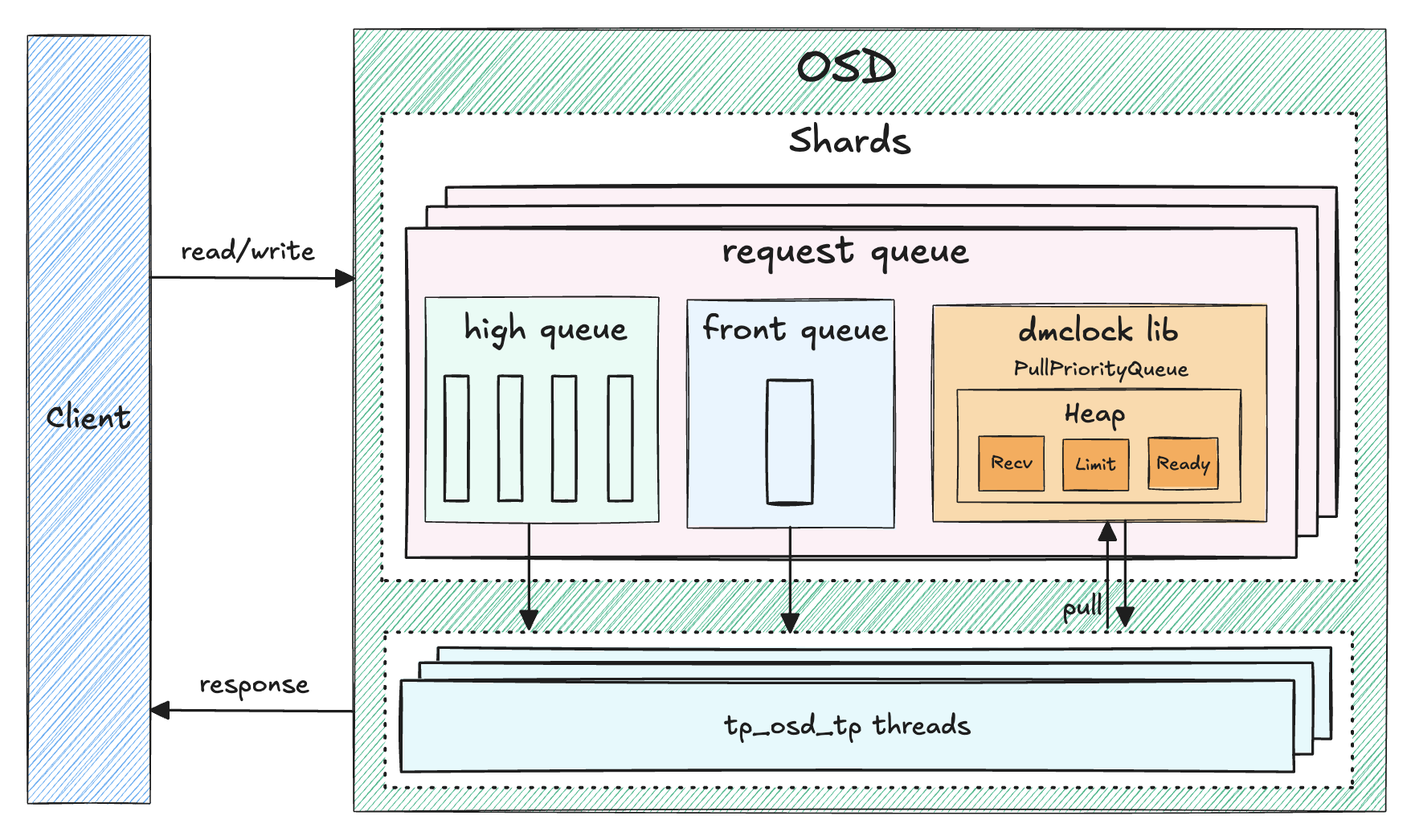
四、OSD QoS
以下分析基于 Ceph V18.2.7 分支代码。
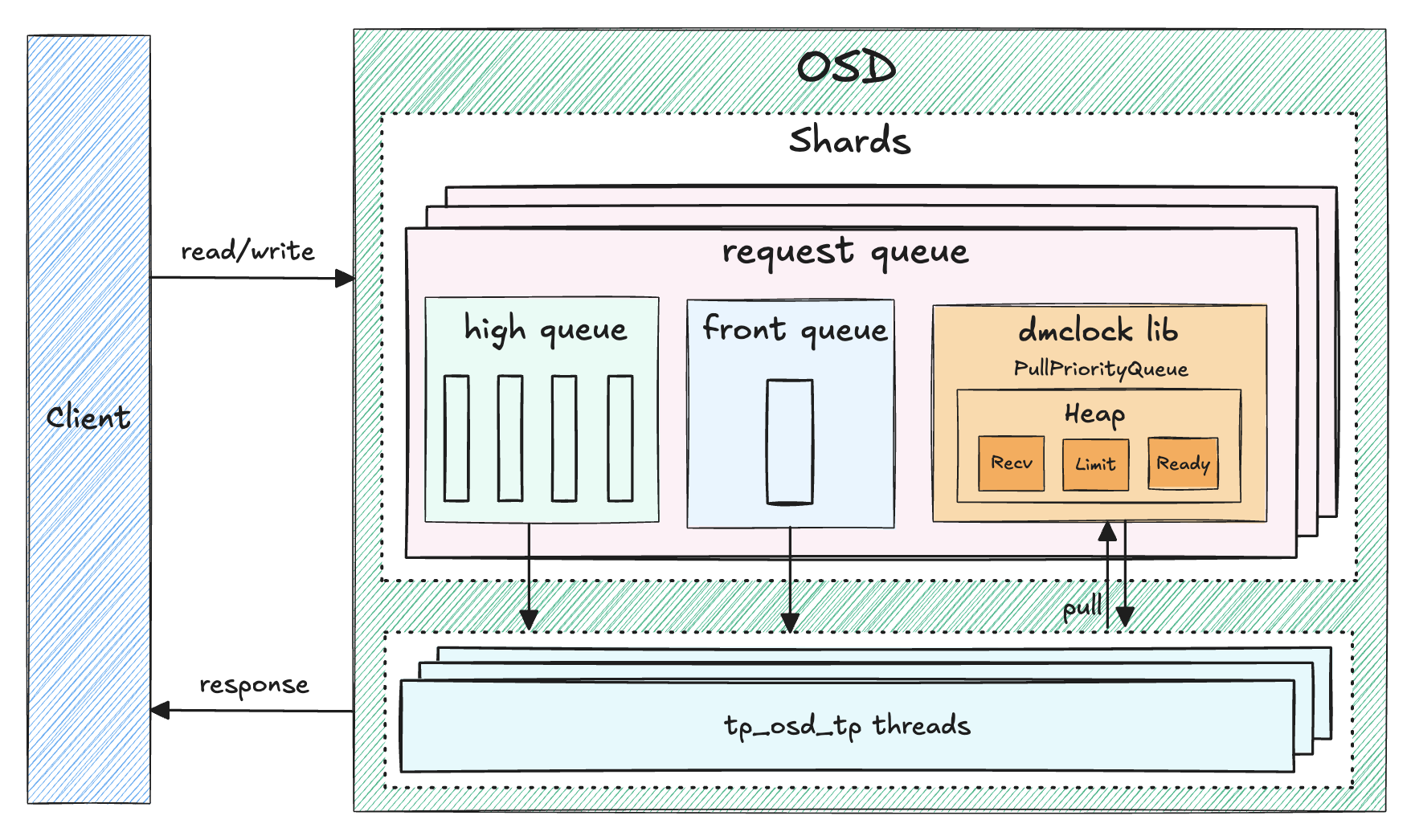
相关材料:
- Ceph OSD mclock 官方文档: https://docs.ceph.com/en/latest/rados/configuration/osd-config-ref/#dmclock-qos
- https://ceph.io/en/news/blog/2021/qos-study-with-mclock-and-wpq-schedulers/
- https://ceph.com/en/news/blog/2022/mclock-vs-wpq-testing-with-background-ops-part1/
- https://ceph.com/en/news/blog/2022/mclock-vs-wpq-testing-with-background-ops-part2/
- https://docs.ceph.com/en/quincy/dev/osd_internals/mclock_wpq_cmp_study/
- https://github.com/ceph/ceph/pull/14997
- https://github.com/ceph/ceph/pull/14330
实现特点:
- 限制粒度为 OSD 中抽象出的多种请求模式间的 QoS , 按照 mclock 的限制规则,我们需要限制不同请求间的流量,在限制的请求中,请求类别被作为 Key ,目前 OSD Scheduler 中共引入了四种请求类别,分别是 background_recovery/background_best_effort/immediate/client , 每个操作都有与之对应的请求类别,进而每个 OSD Shard 内部可以限制不同请求类别间的 QoS ;
- 配置中引入了 osd_mclock_profile 参数,提供了一种配置不同请求类别间 QoS 参数的方式,详细的配置影响及关系参见相关配置中的解释;
- client/background_recovery/background_best_effort 的 res/wgt/lim 配置的有效范围都是 0 到 1.0 ,这并不是实际应用在 mclock 中的参数,实际应用的值的计算公式为:
osd_mclock_max_sequential_bandwidth_[hdd/ssd] / osd_op_num_shards * []_res或者osd_mclock_max_sequential_bandwidth_[hdd/ssd] / osd_op_num_shards * []_lim, 这样才是每个 OSD Shard 针对不同的请求类别配置的 QoS 参数;
相关配置:
osd_op_queue: 每个 OSD 内普通队列的操作优先级队列算法,可选值为 wpq/mclock_scheduler/debug_random , 默认值为 mclock_scheduler , 无法动态修改;wpq: 根据操作的优先级出队,以防止任何队列的饥饿,有助于解决一些 OSD 比其他 OSD 更过载的情况;mclock_scheduler: 根据操作所属的类别(恢复、擦洗、快照修剪、客户端操作、osd 子操作)来优先处理操作;debug_random: 随机选择以上的算法;
osd_op_queue_cut_off: 高优先级操作和低优先级操作之间的阈值,可选值为 low/high/debug_random ,默认值为 high, 无法动态修改;low: 将所有复制操作及更高优先级的操作发送到严格队列,对应的具体数值为 CEPH_MSG_PRIO_LOW (64) ;high: 将复制确认操作及更高优先级的操作发送到严格队列,设置为 high 应该有助于当集群中的一些 OSD 非常繁忙时,特别是与 osd_op_queue 设置中的 wpq 结合使用时。非常繁忙的 OSD 处理复制流量可能会在没有这些设置的情况下饿死这些 OSD 上的主要客户端流量,对应的具体数值为 CEPH_MSG_PRIO_HIGH (196) ;debug_random: 随机选择以上的配置;
osd_mclock_profile: mclock 配置文件类型,可选值为 balanced/high_recovery_ops/high_client_ops/custom ,默认值为 balanced, 无法动态修改;balanced: 该模式下,client 请求类别配置为 R:0.5/W:1/L:0 , background_recovery 请求类别配置为 R:0.5/W:1/L:0 , background_best_effort 请求类别配置为 R:0/W:1/L:0.9 ;high_recovery_ops: 该模式下,client 请求类别配置为 R:0.3/W:1/L:0 , background_recovery 请求类别配置为 R:0.7/W:2/L:0 , background_best_effort 请求类别配置为 R:0/W:1/L:0 ;high_client_ops: 该模式下,,client 请求类别配置为 R:0.6/W:2/L:0 , background_recovery 请求类别配置为 R:0.4/W:1/L:0 , background_best_effort 请求类别配置为 R:0/W:1/L:0.7 ;custom: 该模式下,自定义配置对应的配置;
osd_mclock_scheduler_client_res: 每个客户端预留的IO比例(默认),可选值的范围为 [0, 1.0] ,默认值为 0.0 ;osd_mclock_scheduler_client_wgt: 每个客户端的 IO 份额(默认)超过预留,默认值为 1 ;osd_mclock_scheduler_client_lim: 每个客户端的 IO 限制(默认)超过预留,可选值的范围为 [0, 1.0] ,默认值为 0.0 ;osd_mclock_scheduler_background_recovery_res: 为后台恢复保留的 IO 比例(默认),可选值的范围为 [0, 1.0] ,默认值为 0.0 ;osd_mclock_scheduler_background_recovery_wgt: 每次后台恢复的 IO 份额超过预留,默认值为 1 ;osd_mclock_scheduler_background_recovery_lim: 超出预留的后台恢复的 IO 限制,可选值的范围为 [0, 1.0] ,默认值为 0.0 ;osd_mclock_scheduler_background_best_effort_res: 为后台 best_effort 保留的 IO 比例(默认),可选值的范围为 [0, 1.0] ,默认值为 0.0 ;osd_mclock_scheduler_background_best_effort_wgt: 每个后台 best_effort 的 IO 份额超过预留,默认值为 1 ;osd_mclock_scheduler_background_best_effort_lim: 超过预留的后台 best_effort 的 IO 限制,可选值的范围为 [0, 1.0] ,默认值为 0.0 ;osd_mclock_max_capacity_iops_hdd: 每个 OSD 的最大随机写入 IOPS 容量 (在 4KiB 块大小下) (针对旋转介质),默认值为 315 ;osd_mclock_max_capacity_iops_ssd: 每个 OSD 的最大随机写入 IOPS 容量 (在 4 KiB 块大小下) (针对固态介质),默认值为 21500 ;osd_mclock_max_sequential_bandwidth_hdd: OSD 的最大顺序带宽,以字节/秒为单位 (针对旋转介质),默认值为 150M ;osd_mclock_max_sequential_bandwidth_ssd: OSD 的最大顺序带宽,以字节/秒为单位 (针对固态介质),默认值为 1200M ;osd_mclock_iops_capacity_threshold_hdd: 超过此 IOPS 容量阈值 (在 4KiB 块大小下) 时,将忽略 OSD 的基准测试结果 (针对旋转介质)。默认值为 500 ;osd_mclock_iops_capacity_low_threshold_hdd: 低于此 IOPS 容量阈值 (在 4KiB 块大小下) 时,将忽略 OSD 的基准测试结果 (针对旋转介质)。默认值为 50 ;osd_mclock_iops_capacity_threshold_ssd: 超过此 IOPS 容量阈值 (在 4KiB 块大小下) 时,将忽略 OSD 的基准测试结果 (针对固态介质)。默认值为 80000 ;osd_mclock_iops_capacity_low_threshold_ssd: 低于此 IOPS 容量阈值 (在 4KiB 块大小下) 时,将忽略 OSD 的基准测试结果 (针对固态介质)。默认值为 1000 ;osd_push_per_object_cost: 提供推送操作的开销,默认值为 1000B ;osd_async_recovery_min_cost: 当前日志条目数差异和历史丢失对象数的混合测量,高于该值时,我们会在适当时切换到使用异步恢复,默认值为 100 ;osd_mclock_scheduler_anticipation_timeout: mclock 预期超时时间(以秒为单位),默认值为 0 ;osd_mclock_force_run_benchmark_on_init: 强制在 OSD 初始化/启动时运行 OSD 基准测试,默认值为 false ;osd_mclock_skip_benchmark: 在 OSD 初始化/启动时跳过 OSD 基准测试,默认值为 false ;osd_mclock_override_recovery_settings: 启用对 mClock 调度器的恢复/回填限制的覆盖,默认值为 false ;
相关命令:
|
五、Pool QoS
以下基于 https://github.com/ceph/ceph/pull/19340 代码进行分析。
相关材料:
实现特点:
- 限制粒度为 OSD Shard ,即每个 OSD Shard 中都会单独限制对应 pool 的 QoS ,因此社区在测试的时候将 osd_op_num_shards 等配置设置为 1 ,在实际生产场景下需要针对 OSD Shard 的数量进行计算;
- 该实现基于 mclock 进行实现,采用的是 PullPriorityQueue 类;
- 新增的 pool 的配置需要持久化存储到 pg_pool 结构体中,因此修改了对应数据结构的编解码逻辑及版本信息;
- 该实现未合并到社区;
相关配置:
osd_op_queue: OSD 中操作队列的类型,之前可选参数为 wpq/prioritized/mclock_opclass/mclock_client/debug_random ,该变动中新增了一个 mclock_pool 。默认值为 wpq ;osd_pool_default_mclock_res: 默认的 mclock 预留值,默认值为 0.0 ;osd_pool_default_mclock_wgt: 默认的 mclock 权重值,默认值为 1.0 ;osd_pool_default_mclock_lim: 默认的 mclock 限制值,默认值为 0.0 ;
相关命令:
|
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 咕咕!
相关推荐

2023-06-10
译 - Replication Under Scalable Hashing: A Family of Algorithms for Scalable Decentralized Data Distribution
译作: 可扩展哈希下的复制: 可扩展分散数据分布的算法家族 , 原文地址 ,该论文发表于 2004 年 4 月在新墨西哥州圣达菲举行的第 18 届国际并行和分布式处理研讨会 (IPDPS 2004) 论文集。这篇论文介绍了一系列名为 RUSH(Replication Under Scalable Hashing) 的算法,用于在去中心化的存储系统中分配和管理数据。每种 RUSH 变体都有其独特的优势和局限性,选择哪一种取决于具体的系统需求和操作环境。 算法特点: 允许在线调整特定对象的复制程度,且不受其他对象复制程度的影响。 保证数据复制的安全性,即确保同一对象的副本不会存储在同一硬盘上。 支持加权,允许将不同年份的磁盘添加到系统中。加权可以让系统充分利用最新的技术,也可以淘汰较旧的技术。 支持最佳或接近最佳的重组,当系统添加/淘汰磁盘时,会最大限度地减少需要移动的对象数量,以使系统恢复平衡。 支持在线重组,无需长时间锁定文件系统。 完全去中心化,无需中央目录,客户端可以并行计算数据位置。 极少的资源需求,算法速度非常快,并且占用的内存极少。 算法类别: R...

2023-04-12
ceph-ansible 集群部署运维指南
本文详细介绍了使用 ceph-ansible 部署和运维 Ceph 集群的过程,包括各版本及其依赖的 Ansible 版本的对应关系、自定义模块与任务的结构、集群部署、运维操作及相关示例。特别强调了环境配置、节点连通性验证、MDS 和 OSD 组件的管理,以及安全和性能优化注意事项。 一、项目介绍以下分析基于 ceph-ansible stable-6.0 分支代码。 1.1、版本与对应关系目前 ceph-ansible 采用不同的代码分支来支持部署不同版本的 ceph 集群,且每个代码分支需要特定的 ansible 版本支持,具体的对应关系如下(以下对应关系更新于 2025/05/23 ): ceph-ansible 分支 支持的 ceph 版本 依赖的 ansible 核心版本 依赖的 ansible 发布版本包 stable-3.0 Jewel(V10), Luminous(V12) 2.4 - stable-3.1 Luminous(V12), Mimic(V13) 2.4 - stable-3.2 Luminous(V12), M...
2023-05-01
Ceph 常用命令汇总
一、常用命令1.1、Pool# 查看 poolceph osd pool ls detail# 创建 poolceph osd pool create testpool 32 32ceph osd pool set testpool pg_autoscale_mode off# 调整 pool pg/pgp , 并关闭自动调整ceph osd pool set testpool pg_num 32ceph osd pool set testpool pgp_num 32ceph osd pool set testpool pg_autoscale_mode off# 设置 pool 最小副本ceph osd pool set testpool min_size 1ceph osd pool set testpool size 1 --yes-i-really-mean-it# 移除 poolceph tell mon.\* injectargs '--mon-allow-pool-delete=true'ceph osd pool delete testpoo...
2025-11-08
Ceph 和 LinuxKernel 版本时间对照表
本文提供了一份详细的Ceph、Ceph-client与Linux内核版本对应关系表,涵盖了从2015年至今的月度发布记录。内容包含各版本的具体发布时间、GitHub链接以及三个组件的时间轴甘特图,旨在帮助用户快速查询和规划Ceph部署时所需的内核兼容性。 一、版本时间对照1.1、版本时间对照表 Month ceph ceph-client linux 2011-07 v3.0 2011-10 v3.1 2012-01 v3.2 2012-03 v3.3 2012-05 v3.4 2012-07 v3.5 2012-10 v3.6 2012-12 v3.7 2013-02 v3.8 2013-04 v3.9 2013-07 v3.10 2013-09 v3.11 2013-11 v3.12 2014-01 v3.13 2014-03 v3.14 2014-06 v3.15 2014-08 v3.16 2014-10 v3.17 2...
2025-08-09
CephFS Inode 编号的申请与释放
一、Inode 编号介绍1.1、编号规则在 CephFS 中 MDS 负责管理所有的 Inode 信息。CephFS 本身支持 多MDS 策略,为了避免多MDS 分配的 Inode 出现冲突,所以 MDS 在分配 Inode 的时候需要使用 RankID 来区分 Inode 的范围。每个 MDS 中限制 Inode 分配范围的函数为 InoTable::reset_state ,每个 MDS 中负责的 Inode 范围为:[(rank+1) << 40, ((rank+1) << 40)) ,即从 (rank+1) << 40 开始的连续 1 << 40 个 Inode 。 MDSRank 起始Inode编号(十进制) 起始Inode编号(十六进制) 结束Inode编号(十六进制) 管辖的Inode数量 0 1,099,511,627,776 0x10000000000 0x1FFFFFFFFF 1,099,511,627,776 1 2,199,023,255,552 0x20000000000 0x2FFFFFF...
2024-12-01
CephFS 对接 Samba 使用教程
一、Samba 介绍Samba 是一款基于 GNU 通用公共许可证的自由软件,Samba 项目是软件自由保护协会 (Software Freedom Conservancy) 的成员。自 1992 年以来,Samba 一直为所有使用 SMB/CIFS 协议的客户端(例如所有版本的 DOS 和 Windows、OS/2、Linux 以及许多其他系统)提供安全、稳定且快速的文件和打印服务。 Samba 项目源码位于 https://git.samba.org/samba.git , 镜像代码仓库地址为 https://github.com/samba-team/samba 。 1.1、二进制包安装部署我们的机器环境为 CentOS 8.5.2111 , 受限于系统版本较老,导致最终安装版本为 Samba 4.19.4 。以下操作基于这些环境进行。 由于安装的 Samba 软件默认缺少 vfs_ceph 的相关库,所以在测试的时候无法测试一些使用场景,因此在实际部署测试的时候并不会使用该版本进行测试,而是会采用编译安装的版本进行测试。 1.1.1、环境初始化相关命令...
评论
