Ceph 集群性能测试工具详解
本文详细介绍了包括 rados bench、rbd bench、dd 、fio 、vdbench 、mdtest 、iozone、cosbench、cbt 等测试工具对于 Ceph 集群的性能压测的使用。对于每个工具都提供了压测命令参数、示例命令等使用说明,实现了对 Ceph 块存储、文件存储、对象存储、rados 对象存储等存储类别的性能压测。文中重点阐述了各命令的使用格式、基本功能和参数选择,为用户在 Ceph 环境中进行性能评估提供了实用指南。
一、rados bench
以下基于 v19.2.1 版本进行测试。
用途:
- 测试 ceph rados 对象存储性能;
1.1、测试配置参数
命令格式:
|
$seconds: 压测运行时间;$type: 压测类型,可选值为 write/seq/rand (分别代表写/连续读/随机读);-p: 指定压测的目标 pool ;-b: 只有当压测类型为 write 时可用,用于设置写入 block 的大小,默认为 4M;-O: 设置写入 object 的大小,默认为 4M(与 -b 参数值相同);-t: 并发数量,默认为 16 ;--no-cleanup: 压测数据后不清理,可用于后续测试读性能;--run-name: 压测任务名(压测任务元信息对象名)。当压测类型为 write 的时,在压测结果后会将压测的配置信息写入该名称的对象中;当压测类型为 seq/rand 时或者启用了 –reuse-bench 参数,则会在压测开始前尝试读取该名称的对象中存储的压测元信息。当执行压测数据清理的时候也会尝试读取其中的压测元信息。其中压测元信息中包括 object_size/finished/prev_pid/op_size。当对一个 pool 执行多个客户端并发压测的时候一定要指定不同的任务名,否则可能无法同时启动多个压测任务,或者会导致压测元信息持久化信息的异常;--no-hints: 默认不指定该参数;--reuse-bench: 默认不指定该参数;--show-time: 默认不指定该参数;--write-object: 只有当压测类型为 write 时可用,用于设置压测写入目标为 object ,默认写入目标为 object;--write-omap: 只有当压测类型为 write 时可用,用于设置压测写入目标为 omap;--write-xattr: 只有当压测类型为 write 时可用,用于设置压测写入目标为 xattr;
1.2、测试命令示例
基础命令:
|
测试命令:
|
二、rbd bench
以下基于 v19.2.1 版本进行测试。
用途:
- 测试块存储性能;
2.1、测试配置参数
命令格式:
|
-p/--pool: 指定压测的 pool ;--namespace: 指定压测的 namespace ;--image: 指定压测的 image ;--io-size: 每次操作 IO 的大小,可选值 < 4G , 默认为 4K ;--io-threads: 默认为 16 ;--io-total: 默认为 1G ;--io-pattern: 执行 IO 的模式,用于设置多线程情况下每个线程操作数据的起始点,可选值为 rand/seq/full-seq (随机的/连续的/完全连续的) ,默认为 seq 。rand 模式下随机设定每个线程的数据起始点。seq 模式下按照线程数量分配 image 总大小,分配给每个线程相互独立的数据范围,设置每个线程的数据起始点,实现每个线程操作自己范围内的数据。full-seq 模式下,每个线程分配的起始点为分别是 0io-size , 1io-size, 2*io-size 等;--rw-mix-read: 设置读写操作的比例,这里的值为读操作的比例,可选值 <= 100 , 默认为 50 。 这里采用的概率范围计算方法,计算规则为每次执行压测的时候获取 0 到 100 以内的数字,如果获取的数字小于该值则执行读操作,如果获取的数字大于等于该值则执行写操作,通常由于 100 以内的每个数字出现的概率相同,所以可以按照数字的多少来划分概率;--io-type: 压测类型,可选值为 read/write/readwrite(rw) (读/写/读写混合);image-spec:
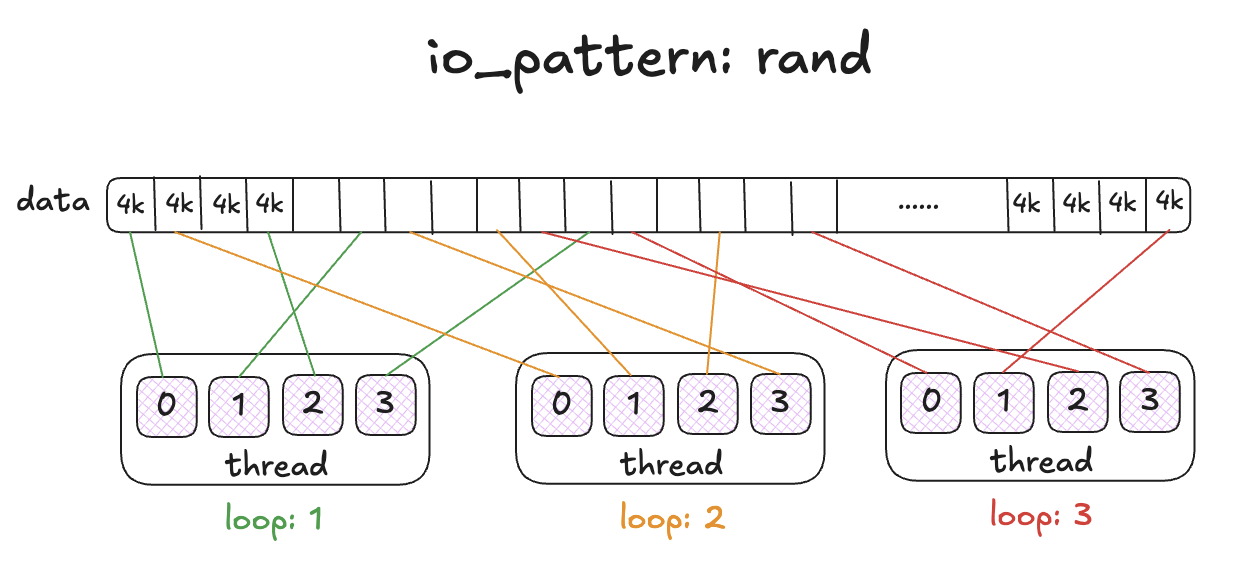
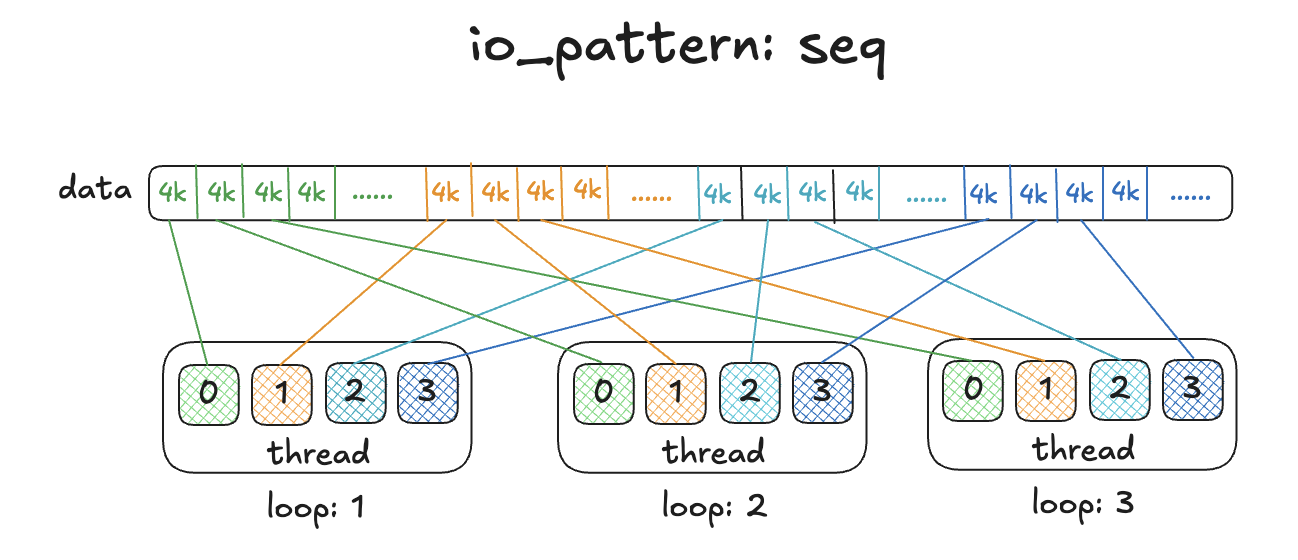
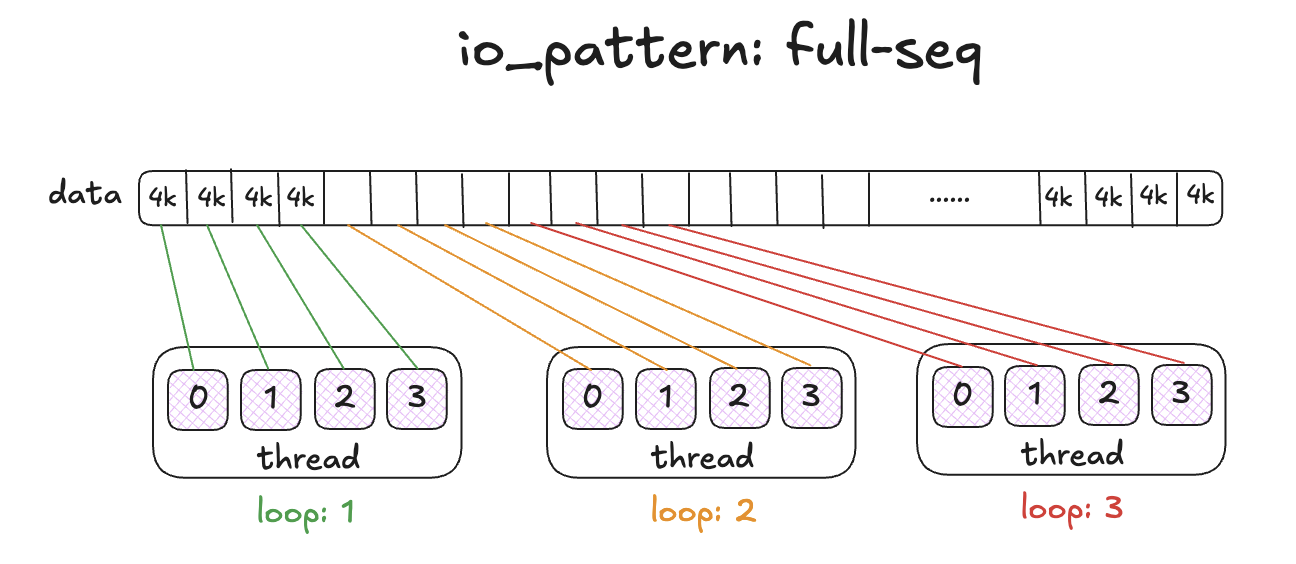
2.2、测试命令示例
基础命令:
|
测试命令:
|
三、dd
用途:
- 测试裸设备存储性能;
- 测试块存储性能;
- 测试文件存储性能;
3.1、测试配置参数
命令格式:
|
bs: 每次操作的字节数,该值会覆盖 ibs 和 obs , 默认为 512 ;cbs: 每次转换的字节数;conv: 根据逗号分隔的符号列表转换文件;count: 操作的块总数量;ibs: 每次读取最多的字节数,默认为 512 ;if: 从文件中读取,而不是从标准输入中读取;iflag: 读操作的 flag 列表,以逗号分隔;obs: 每次写入字节数,默认为 512 ;of: 写入到文件,而不是写入到标准输出;oflag: 写操作的 flag 列表,以逗号分隔 ;seek: 在输出开始时跳过 N 个 obs 大小的块;skip: 在输入开始时跳过 N 个 ibs 大小的块;status: 打印到标准错误的级别信息,none 仅展示错误消息, noxfer 阻止最终传输统计信息, progress 显示周期性传输统计信息;
命令相关的 flag 参数如下:
append: 追加模式,仅对输出有意义,建议使用 conv=notrunc ;direct: 使用直接 I/O 操作数据;directory: 仅支持操作目录;dsync: 使用同步 I/O 操作数据;sync: 使用同步 I/O 操作数据,也适用于元数据;fullblock: 累积完整的输入块,仅限 iflag ;nonblock: 使用非阻塞 I/O ;noatime: 不更新访问时间 ;nocache: 请求丢弃缓存。另见 oflag=sync ;noctty: 不从文件分配控制终端 ;nofollow: 不跟随符号链接;count_bytes: 将 ‘count=N’ 视为字节计数,仅限 iflag ;skip_bytes: 将 ‘skip=N’ 视为字节计数,仅限 iflag ;seek_bytes: 将 ‘seek=N’ 视为字节计数,仅限 oflag ;
命令相关的 conv 参数如下:
ascii: 从 EBCDIC 到 ASCII ;ebcdic: 从 ASCII 到 EBCDIC ;ibm: 从 ASCII 到替代 EBCDIC ;block: 用空格填充以换行符结尾的记录到 cbs 大小;unblock: 用换行符替换 cbs 大小记录中的尾随空格;lcase: 将大写字母转换为小写字母;ucase: 将小写字母转换为大写字母;sparse: 尝试在输出中为 NUL 输入块进行跳过而不是写入;swab: 交换每对输入字节;sync: 用 NUL 填充每个输入块到 ibs 大小;与 block 或 unblock 一起使用时,用空格而不是 NUL 填充;excl: 如果输出文件已存在则失败;nocreat: 不创建输出文件;notrunc: 不截断输出文件;noerror: 读取错误后继续;fdatasync: 在完成前物理写入输出文件数据;fsync: 在完成前物理写入输出文件数据,也写入元数据;
3.2、测试命令示例
通常 dd 命令可以与 time 命令结合使用,以便于获取 dd 执行的耗时信息。
基础命令:
|
3.2.1、裸设备性能测试
测试命令:
|
3.2.2、块存储性能测试
基础命令:
|
测试命令:
|
3.2.3、文件存储性能测试
基础命令:
|
测试命令:
|
四、fio
用途:
- 测试裸设备存储性能;
- 测试块存储性能;
- 测试文件存储性能;
- 测试对象存储性能;
- 测试 ceph rados 对象存储性能;
以下介绍基于 fio 3.40 版本。
软件环境及安装:
|
4.1、测试配置参数
命令格式:
|
--debug: 启用调试日志。可选参数为一个或多个。process,file,io,mem,blktrace,verify,random,parse,diskutil,job,mutex,profile,time,net,rate,compress,steadystate,helperthread,zbd ;--parse-only: 仅解析选项,不启动任何 IO ;--merge-blktrace-only: 仅合并 blktrace,不启动任何 IO ;--output: 将输出写入文件;--bandwidth-log: 生成聚合带宽日志;--minimal: 最小化(简洁)输出;--output-format=type: 输出格式,可选值为 terse/json/json+/normal ;--terse-version=type: 设置简洁版本输出格式,可选值为 2/3/4 ,默认为 3 ;--cpuclock-test: 执行 CPU 时钟的测试/验证;--crctest=[type]: 测试校验和函数的速度;--cmdhelp=cmd: 打印命令帮助,all 表示所有命令;--enghelp=engine: 打印 ioengine 帮助,或列出可用的 ioengine ;--enghelp=engine,cmd: 打印 ioengine 命令的帮助;--showcmd: 将作业文件转换为命令行选项;--eta=when: 何时打印 ETA 估计,可选值为 always/never/auto ;--eta-newline=t: 每经过 t 时间强制换行;--status-interval=t: 每经过 t 时间强制完整状态转储;--readonly: 开启安全只读检查,防止写入;--section=name: 仅运行作业文件中指定的部分,可以指定多个部分;--alloc-size=kb: 将 smalloc 池设置为此大小,单位为 kb , 默认为 16384 ;--warnings-fatal: fio 解析器警告为致命错误;--max-jobs=nr: 支持的最大线程/进程数;--server=args: 启动后端 fio 服务器;--daemonize=pidfile: 后台运行 fio 服务器,将 pid 写入文件;--client=hostname: 与远程后端 fio 服务器在主机名通信;--remote-config=file: 告诉 fio 服务器加载此本地作业文件;--idle-prof=option: 报告系统或每个 CPU 的空闲情况(option=system,percpu),或仅运行单位工作校准(option=calibrate);--inflate-log=log: 解压并输出压缩日志;--trigger-file=file: 当文件存在时执行触发命令;--trigger-timeout=t: 在此时间执行触发;--trigger=cmd: 将此命令设置为本地触发器;--trigger-remote=cmd: 将此命令设置为远程触发器;--aux-path=path: 使用此路径存储 fio 状态生成的文件;
支持的 io engines 列表: (使用 fio --enghelp 命令列出, 可使用 fio --enghelp=$name 命令列出对应 io engine 的参数,部分参数解释通过 AI 分析,请谨慎参考)
cpuio: 专门用于测试 CPU 性能的 I/O 引擎。它不涉及任何实际的磁盘或网络 I/O 操作,而是通过执行计算密集型任务来模拟 I/O 负载。这种引擎通常用于评估 CPU 的处理能力和多线程性能;mmap: 通过内存映射文件进行 I/O 操作。这种方法可以直接通过内存访问文件数据,适用于需要高速缓存和内存操作的测试;sync: 使用标准的同步 I/O 系统调用(如 read() 和 write())。这是最基本的 I/O 引擎,适用于普通的磁盘 I/O 性能测试;psync: 使用 POSIX 同步 I/O 系统调用。这种引擎使用 pread() 和 pwrite(),允许进行位置指定的同步 I/O 操作;vsync: 类似于 psync,但使用 vmsplice() 来进行数据传输,适用于需要高效数据移动的场景;pvsync: 类似于 psync,但使用 preadv() 和 pwritev() 系统调用,这些调用允许进行向量化的读写操作,即一次操作可以处理多个非连续的内存块;pvsync2: 这是 pvsync 的改进版本,使用更现代的 preadv2() 和 pwritev2() 系统调用,支持额外的标志和功能,如 RWF_NOWAIT,可以提高异步处理能力;null: 一个特殊的 I/O 引擎,它实际上不执行任何 I/O 操作。这可以用来测试 fio 本身的开销或用作控制组;net: 用于网络 I/O 性能测试。这种引擎可以模拟网络数据发送和接收,用于评估网络设备和协议的性能;netsplice: 使用 splice() 和网络套接字结合的方式进行数据传输。这种方法可以直接在内核中转移数据到网络套接字,减少用户空间和内核空间之间的数据复制;ftruncate: 使用 ftruncate() 系统调用来改变文件的大小。这种引擎主要用于测试文件系统如何处理文件大小的变化,特别是在文件系统扩展和收缩时的性能;filecreate: 专注于文件创建操作。使用这个引擎可以测试文件系统创建新文件的性能,这对于评估文件系统的元数据操作性能非常重要;filestat: 用于测试文件状态操作,如使用 stat() 系统调用。这可以帮助评估文件系统在处理文件元数据查询时的效率;filedelete: 用于测试文件删除操作的性能。它可以帮助用户了解在特定存储系统上删除文件所需的时间和资源消耗;dircreate: 用于测试目录创建操作的性能。使用这个引擎可以测量创建新目录所需的时间;dirstat: 用于测试获取目录状态的操作性能,比如读取目录中的文件列表;dirdelete: 用于测试删除目录的性能;exec: 允许fio执行外部命令或脚本,这可以用来测试系统在执行特定命令或脚本时的I/O性能;posixaio: 使用 POSIX 异步 I/O 接口。这种引擎在多平台上提供异步 I/O 功能,但在 Linux 上通常不如 libaio 高效;falloc: 使用 fallocate() 系统调用来预分配文件空间。这种方法可以在文件实际写入之前确保空间被分配,用于测试文件系统如何处理空间分配请求;e4defrag: 专门用于测试 ext4 文件系统的碎片整理操作。这可以帮助评估 ext4 文件系统在长时间运行后,文件碎片整理对性能的影响;splice: 使用 Linux 的 splice() 系统调用来移动数据。这种方法可以在两个文件描述符之间直接传输数据,减少数据复制操作的开销;mtd: 针对内存技术设备(Memory Technology Device)的 I/O 引擎。MTD 设备通常是嵌入式存储设备,如闪存,不具备常见的块设备接口。这个引擎允许 fio 直接与这类设备进行交互,测试其性能,特别是在嵌入式系统或 IoT 设备中非常有用;sg: 使用 SCSI generic (sg) 接口进行 I/O 操作的引擎。这个引擎允许 fio 直接与 SCSI 设备进行交互,绕过传统的块设备层。这对于需要直接评估 SCSI 命令性能或进行低级别 SCSI 测试的场景非常有用;io_uring: 利用 Linux 的 io_uring 接口进行 I/O 操作。这是一种现代的异步 I/O 接口,提供了比传统 AIO 更高的性能和更低的 CPU 使用率;io_uring_cmd: 擎利用了Linux的io_uring接口,这是一种高效的异步I/O执行方式。io_uring_cmd引擎可以帮助开发者测试和优化使用io_uring接口的应用程序的性能;libaio: 利用 Linux 的异步 I/O 子系统(AIO)。这种引擎可以在不阻塞应用程序的情况下提交和完成 I/O,适用于高性能和高并发的 I/O 测试;rdma: 使用远程直接内存访问(RDMA)技术进行数据传输。这种引擎适用于需要高性能网络通信的场景,如数据中心内部或高性能计算环境;rados: 专为测试 Ceph RADOS 存储集群设计的引擎。它直接与 Ceph 的 RADOS 层交互,用于评估 Ceph 集群的性能;rbd: 针对 Ceph 块设备(RBD)的 I/O 引擎。它允许直接对 Ceph 块存储进行性能测试,适用于评估虚拟化环境中的存储性能;http: 使fio能够执行HTTP请求,从而测试HTTP服务器的性能。这包括了解服务器处理请求的能力,以及在高负载下的稳定性和响应时间;
相关参数: (使用 fio --cmdhelp=all 命令列出)
|
4.2、测试命令示例
4.2.1、裸设备/块存储性能测试
测试命令(使用 libaio 引擎):
官方示例的 fio 文件: https://github.com/axboe/fio/blob/fio-3.40/examples/aio-read.fio
|
ceph 块存储测试命令(使用 rbd 引擎):
官方示例的 fio 文件: https://github.com/axboe/fio/blob/fio-3.40/examples/rbd.fio
相关参数( rbd 引擎):
clustername: Ceph 的集群名称;pool: 托管 RBD 引擎的 RBD 的池名称;rbdname: RBD 引擎的 RBD 名称,对应镜像名称;clientname: 访问 RBD 引擎的 RBD 的 Ceph 客户端名称;busy_poll: 完成任务后使用 busy pool ,而不是使用 sleeping ;
|
4.2.2、文件存储性能测试
基础命令:
|
测试命令(使用 libaio 引擎):
|
4.2.3、对象存储性能测试
Ceph 相关命令:
|
官方示例的 fio 文件: https://github.com/axboe/fio/blob/fio-3.40/examples/http-s3.fio
相关参数( http 引擎):
https: 启用 https ;http_host: 主机名 (S3 存储桶);http_user: HTTP 用户名;http_pass: HTTP 密码;http_s3_key: S3 密钥;http_s3_keyid: S3 密钥 ID ;http_swift_auth_token: OpenStack Swift 认证令牌;http_s3_region: S3 区域;http_s3_sse_customer_key: S3 SSE 客户密钥;http_s3_sse_customer_algorithm: S3 SSE 客户算法;http_s3_storage_class: S3 存储类;http_mode: 是否使用 WebDAV、Swift 或 S3 ;http_verbose: 增加 http 引擎的详细程度;
测试命令(使用 http 引擎):
|
4.2.4、ceph rados 对象存储性能测试
官方示例的 fio 文件: https://github.com/axboe/fio/blob/fio-3.40/examples/rados.fio
相关参数( rados 引擎):
clustername: Ceph 集群名称;pool: 要进行基准测试的 Ceph 池名称;clientname: 访问 RADOS 引擎的 Ceph 客户端名称;conf: Ceph 配置文件的路径;busy_poll: 完成后 busy pool ,而不是使用 sleeping ;touch_objects: 在启动时触碰(创建)对象;
测试命令(使用 rados 引擎): 无论是顺序/随机读,还是顺序/随机写,fio 内部实现的 rados 的操作都只对应同一个读写操作,分别是:rados_aio_write 和 rados_aio_read 。
|
五、vdbench
用途:
- 测试块存储性能;
- 测试文件存储性能;
5.1、测试配置参数
5.1.1、块存储测试配置参数
块存储测试配置参数的定义顺序: HD, SD, WD, RD
HD: ( Host Define 主机定义),非必选项,单机运行时不需要配置 HD 参数,一般只有在多主机联机(给多个主机命名,以便在结果中区分)测试时才需要配置;hd: 标识主机定义的名称,多主机运行时,可以使用 hd1、hd2、hd3…区分;system: 主机 IP 地址或主机名;vdbench: vdbench 执行文件存放路径,当多主机存放路径不同时,可在 hd 定义时单独指定;user: master/slave 通信使用的用户名;shell: 在多主机联机测试时, mater/slave 主机间通信方式,可选值为 rsh/ssh/vdbench ,默认值为 rsh 。当参数值为 rsh 时,需要配置 master/slave 主机 rsh 互信,考虑到 rsh 使用明文传输,安全级别不够,通常情况下不建议使用这种通信方式;当参数值为 ssh 时,需要配置 master/slave 主机 ssh 互信,通常 Linux 主机联机时使用此通信方式;当参数值为 vdbench ,需要在所有 slave 主机运行 vdbench rsh 启用 vdbench 本身的 rsh 守护进程,通常 Window 主机联机时使用此通信方式;
SD: ( Storage Define 存储定义);sd: 标识存储定义的名称;hd: 标识主机定义的名称;lun: 写入块设备,如 /dev/sdb, /dev/sdc…;openflags: 通过设置为 o_direct ,以无缓冲缓存的方式进行读写操作;threads: 对 SD 的最大并发 I/O 请求数量;
WD: ( Workload Define 工作负载定义);wd: 标识工作负载定义的名称;sd: 标识存储定义的名称;seekpct: 随机寻道的百分比,可选值为 0 或 100 (也可使用 sequential 或 random 表示),默认值为 100 。设置为 0 时表示顺序,设置为 100 时表示随机;rdpct: 读取请求占请求总数的百分比,设置为 0 时表示写,设置为 100 时表示读;xfersize: 要传输的数据大小。默认设置为 4k ;skew: 非必选项,一般在多个工作负载时需要指定,表示该工作负载占总工作量百分比( skew 总和为 100 );
RD: ( Run Define 运行定义);rd: 标识运行定义的名称;wd: 标识工作负载定义的名称;iorate: 此工作负载的固定 I/O 速率,常用可选值为 100、max 。当参数值为 100 时,以每秒 100 个 I/Os 的速度运行工作负载,当参数值设置为一个低于最大速率的值时,可以达到限制读写速度的效果。当参数值为 max 时,以最大的 I/O 速率运行工作负载,一般测试读写最大性能时,该参数值均 max ;warmup: 预热时间(单位为秒),默认情况下 vdbench 会将第一个时间间隔输出数据排除在外,程序在预热时间内的测试不纳入最终测试结果中(即预热结束后,才开始正式测试)。当 interval = 5 、 elapsed = 600 时,测试性能为 2 到 elapsed / interval ,即 (avg_2 - 120) 时间间隔内的平均性能。当 interval = 5 、warmup = 60 、elapsed = 600 时,测试性能为 1 + (warmup / interval) 到 (warmup + elapsed) / interval,即 (avg_13 - 132) 时间间隔内的平均性能;maxdata: 读写数据大小,通常情况下,当运行 elapsed 时间后测试结束;当同时指定 elapsed 和 maxdata 参数值时,以最快运行完的参数为准(即 maxdata 测试时间小于 elapsed 时,程序写完 elapsed 数据量后结束)。当参数值为 100 以下时,表示读写数据量为总存储定义大小的倍数(如 maxdata = 2 ,2 个存储定义(每个存储定义数据量为 100G ),则实际读写数据大小为 400G )。当参数值为 100 以上时,表示数据量为实际读写数据量(可以使用单位 M、G、T 等);elapsed: 测试运行持续时间(单位为秒),默认值为 30 ;interval: 报告时间间隔(单位为秒);
5.1.2、文件存储测试配置参数
文件存储测试配置参数的定义顺序: HD, FSD, FWD, RD
HD: ( Host Define 主机定义),非必选项,单机运行时不需要配置 HD 参数,一般只有在多主机联机(给多个主机命名,以便在结果中区分)测试时才需要配置;hd: 标识主机定义的名称,多主机运行时,可以使用 hd1、hd2、hd3… 区分;system: 主机 IP 地址或主机名;vdbench: vdbench 执行文件存放路径,当多主机存放路径不同时,可在hd定义时单独指定;user: master/slave 通信使用用户;shell: 多主机联机测试时, mater/slave 主机间通信方式。可选值为 rsh/ssh/vdbench,默认值为 rsh 。当参数值为 rsh 时,需要配置 master/slave 主机 rsh 互信,考虑到 rsh 使用明文传输,安全级别不够,通常情况下不建议使用这种通信方式。当参数值为 ssh 时,需要配置 master/slave 主机 ssh 互信,通常 Linux 主机联机时使用此通信方式。当参数值为 vdbench ,需要在所有 slave 主机运行 vdbench rsh 启用 vdbench 本身的 rsh 守护进程,通常 Window 主机联机时使用此通信方式;
FSD: ( File System Define 文件系统定义);fsd: 标识文件系统定义的名称,多文件系统时(fsd1、fsd2、fsd3…),可以指定 default (将相同的参数作为所有fsd的默认值);anchor: 文件写入根目录;depth: 创建目录层级数(即目录深度);width: 每层文件夹的子文件夹数;files: 测试文件个数( vdbench 测试过程中会生成多层级目录结构,实际只有最后一层目录会生成测试文件);size: 每个测试文件大小;distribution: 可选值为 bottom/all ,默认为 bottom 。当参数值为 bottom 时,程序只在最后一层目录写入测试文件。当参数值为 all 时,程序在每一层目录都写入测试文件;shared: 可选值为 yes/no ,默认值为 no 。一般只有在多主机联机测试时指定。vdbench 不允许不同的 slave 之间共享同一个目录结构下的所有文件,因为这样会带来很大的开销,但是它们允许共享同一个目录结构。加入设置了shared=yes ,那么不同的 slave 可以平分一个目录下所有的文件来进行访问,相当于每个 slave 有各自等分的访问区域,因此不能测试多个客户的对同一个文件的读写。当多主机联机测试时,写入的根目录 anchor 为同一个路径时,需要指定参数值为 yes ;
FWD: ( FileSystem Workload Defile 文件系统工作负载定义);fwd: 标识文件系统工作负载定义的名称,多文件系统工作负载定义时,可以使用 fwd1、fwd2、fwd3… 区分;fsd: 标识此工作负载使用文件存储定义的名称;host: 标识此工作负载使用主机;operation: 文件操作方式,可选值为 read/write ;rdpct: 读操作占比百分比,一般混合读写时需要指定。可选值为 0~100 ,当值为 60 时,则混合读写比为 6:4 ;fileio: 标识文件 I/O 将执行的方式,可选值为 random/sequential ;fileselect: 标识选择文件或目录的方式,可选值为 random/sequential ;xfersize: 数据传输(读取和写入操作)处理的数据大小(即单次 IO 大小);threads: 此工作负载的并发线程数量;
RD: ( Run Define 运行定义);rd: 标识文件系统运行定义的名称;fwd: 标识文件系统工作负载定义的名称;fwdrate: 每秒执行的文件系统操作数量。设置为 max,表示不做任何限制,按照最大强度自适应;format: 标识预处理目录和文件结构的方式,可选值为 yes/no/restart 。 yes 表示删除目录和文件结构再重新创建。 no 表示不删除目录和文件结构。 restart 表示只创建未生成的目录或文件,并且增大未达到实际大小的文件;elapsed: 测试运行持续时间(单位为秒),默认值为 30 ;interval: 结果输出打印时间间隔(单位为秒);
5.2、测试命令示例
5.2.1、块存储测试命令示例
读写测试配置文件:( 该文件完整路径为 /root/vdbench/conf/block.conf )
|
测试命令:
|
5.2.2、文件存储测试命令示例
测试配置文件:( 该文件完整路径为 /root/vdbench/conf/fs.conf )
|
测试命令:
|
5.3、测试结果解析
测试完成后,vdbench 会将输出结果输出到当前目录的 output 目录中,其中 output 中存在如下文件:
anchors.html: 目录状态报告;config.html: 脚本 ./linux/config.sh 的输出信息;errorlog.html: 运行时的错误日志。当运行测试启用数据校验时,它可能会包含一些错误信息,比如无效的密钥读取,无效的 lba 读取(一个扇区的逻辑字节地址),无效的 SD/FSD 名称读取,数据损坏,坏扇区等;flatfile.html: vdbench 生成的一种逐列的 ASCII 格式的信息,可以使用 parseflat 参数解析结果,可用于生成图表信息;format.histogram.html:format.html: fwd 的 format 报告;fsd1.histogram.html:fsd1.html: fsd 为 fsd1 的报告;fwd1.histogram.html:fwd1.html: fwd 为 fwd1 的报告;hd1-0.html: Slave=hd1-0 的 slave 摘要报告;hd1-0.stdout.html: slave 的标准输出/标准错误=hd1-0 ;hd1.html: hd1 的主机摘要报告;hd1.var_adm_msgs.html:histogram.html: 一种包含报告柱状图的响应时间、文本格式的文件,总响应时间直方图;logfile.html: 包含 Java 代码写入控制台窗口的每行信息的副本,就是终端上运行 vdbench 输出信息的副本,logfile.html 主要用于调试用途;parmfile.html: 包含测试运行配置参数信息,就是运行时指定的配置文件的副本;parmscan.html: 解析传入的配置参数文件内容的记录日志;skew.html: 工作负载偏差报告,仅在以下情况下才会生成偏差信息:有多个工作负载定义 (WD/FWD)、存在多个存储定义(SD/FSD)、有多个主机、有不止一个奴隶(尽管这些规则有时可能会被忽略);status.html: vdbench 运行的状态信息,主要是展示了不同时刻 vdbench 的状态信息;summary.html: 记录全部数据信息,显示每个报告间隔内总体性能情况及工作负载情况,以及除第一个间隔外的所有间隔的加权平均值,可以查看该文件,然后可以跳转到其他的各文件;swat_mon.bin:swat_mon_total.txt:totals.html: 记录全部数据计算之后的平均值,一般测试结果从该文件取值,除第一个间隔外所有间隔的加权平均值。文件内部一般包含两个部分:第一部分会展示文件存储目录结构及数据填充的平均性能值,其中的 “starting RD=format_for_*” 的条目数据是为了初始化测试环境(创建文件夹,空文件等);第二部分会展示执行测试过程中除第一个时间间隔外所有时间间隔平均性能值(主要看这部分的内容);
六、mdtest
用途:
- 测试文件存储元数据性能;
环境初始化与安装:
|
6.1、测试配置参数
flag 类参数:
-C: 仅创建文件/目录。即无此 Flag 时,mdtest 会将测试时创建的文件/目录删除,有此 Flag 则会保留这些文件/目录;-T: 仅获取文件/目录的状态;-E: 仅读取文件/目录;-r: 仅删除由之前的测试留下的文件或目录。注意使用时要保留之前测试的参数,才能准确删除期望的内容;-D: 对目录进行性能测试(不涉及文件),否则每个目录内会一半是文件一半是目录;-F: 对文件进行性能测试(不涉及目录),否则每个目录内会一半是文件一半是目录;-k: 使用 mknod 创建文件;-L: 文件仅在目录树的叶子层,否则每层目录下都会有文件;-P: 打印速率和时间,默认情况下只打印开始结束时间,以及汇总的速率信息;--print-all-procs: 所有进程都打印其结果的摘要;-R: 随机访问文件(仅用于统计);-S: 共享文件访问(只有文件,没有目录);-c: 集体创建:任务 0 执行所有创建操作;-t: 计时唯一工作目录的开销;-u: 每个任务一个工作目录;-v: 冗长模式(每次使用该选项时增加一级);-X: 验证读取的数据--verify-write: 写入后立即读回数据来验证数据-y: 写入完成后 sync 文件-Y: 在每个阶段后调用 sync 命令(包含在计时中;注意这会导致从你的结点 flush 所有 IO)-Z: 打印时间,而不是速率--allocateBufferOnGPU: 在 GPU 上分配缓冲区--warningAsErrors: 任何警告都会导致错误(即将所有警告都视为错误)--showRankStatistics: 包括每个排名的统计信息
带参数值类参数:
-a: I/O 的 API,取值 POSIX 或 DUMMY。-b: 层次目录结构的分支因子,其实就是每个目录中含有子目录或者子文件的目录的数量;默认值为 1 ;-d: 运行测试的目录,可以有多个,用@ 隔开,如 -d=./out1@test/out2@~/out3。默认值为 ./out ;-B: 默认值为 0 ;-e: 从每个文件读取的字节数。默认值为 0 ;-f: 测试将运行的任务的起始编号。默认值为 1 ;-G: 读/写缓冲区中数据的偏移量,如果未设置,则使用随机值。默认值为 -1 ;-i: 测试将运行的迭代次数。默认值为 1 ;-I: 每个目录中的项目数,默认情况下该值控制每个非空目录中的子文件和子目录的数量。默认值为 0 ;-l: 测试将运行的任务的最后编号。默认值为 0 ;-n: 每个进程都会创建/统计/读取/删除 目录和文件。默认值为 0 ;-N: 每个文件/目录操作之间的任务步长(local=0;设置为 1 以避免客户端缓存)。默认值为 0 ;-p: 迭代前延迟(以秒为单位)。默认值为 0 ;--random-seed: -R 的随机数种子。默认值为 0 ;-s: 默认值为 1 ;-V: 详细程度值。与上面 Flag 中的 -v 一样,只是直接设定数字。默认值为 0 ;-w: 创建每个文件后写入每个文件的字节数。默认值为 0 ;-W: 以秒为单位的数字;stonewall 计时器,写入尽可能多的秒数并确保所有进程执行相同数量的操作(目前仅在创建阶段和文件期间停止)。默认值为 0 ;-x: StoneWallingStatusFile,这是一个包含创建阶段迭代次数的文件,可用于在多次运行中拆分阶段。-z: 层次目录结构的深度,即目录的深度,默认值为 0 ;--dataPacketType: 可选值 offset/incompressible/timestamp/random/o/i/t/r ,默认值为 t ;--run-cmd-before-phase:--run-cmd-after-phase:--saveRankPerformanceDetails:
6.2、测试命令示例
|
七、iozone
用途:
- 测试文件存储性能;
环境初始化与安装:
|
7.1、测试配置参数
|
7.2、测试命令示例
7.2.1、单节点测试命令
测试命令:
|
7.2.2、多节点测试命令
测试配置文件: (文件路径为 /etc/iozone/test.conf)
|
测试命令:
|
八、cosbench
用途:
- 测试对象存储性能;
目前社区已经很长时间没有跟进了。
环境初始化与安装:
|
8.1、测试配置参数
测试任务的配置文件位于 conf 目录中,这里解释 s3-config-sample.xml 文件。
配置详情:
|
字段解释:
workload: 测试任务详情。 name 为任务名称。description 为任务描述信息。storage: 存储详情。 type 为存储类型,这里为 s3 。 config 为存储类型对应的配置(endpoint 格式为 host:port)。 默认的 config 配置模板中并没有给出 path_style_access 参数,在使用 ceph rgw 的时候需要将该值设置为 true ,否则会出现 auth 错误。workflow: 工作流详情。workstage: 工作流阶段。 name 为工作流阶段名称。work: 具体工作详情, type 对应 workstage name 。 workers 表示执行该阶段的时候开启多少个工作线程。 runtime 表示运行的时间,时间默认为秒。init: 初始化阶段,主要是进行 bucket 的创建。 cprefix 为 bucket 的名称前缀, containers 表示 bucket 的拼接的后缀。prepare: 配置为 bucket 写入的数据, workers 和 部分 config 含义与 init 阶段相同,除此之外还需要配置 objects ,表示一轮写入多少个对象,以及 object 的大小。main: 进行测试的阶段。cleanup: 进行环境的清理,主要是删除 bucket 中的数据,保证测试后的数据不会保留在集群中。dispose: 删除 bucket 。
operation: 操作详情。 type 为操作类型,可选值为 read/write/delete 等。 ratio 表示该操作所占有操作的比例。 config 配置 bucket 的前缀后缀等信息。
8.2、测试命令示例
示例配置:
|
相关命令:
|
九、cbt
用途:
- 测试块存储性能;
- 测试文件存储性能(借助于 fio 等);
- 测试对象存储性能(借助于 cosbench 和 hsbench );
- 测试 ceph rados 对象存储性能(借助于 rados bench);
CBT 全称为 Ceph Benchmarking Tool ,是官方推出的一个用 Python 编写的测试工具,可以自动执行与 Ceph 集群性能测试相关的各种任务。
环境初始化与安装:
- 测试节点间配置 SSH 免密访问,且用户启用无密码 sudo 访问权限;
- 每台机器节点都需要安装所需要的 Ceph 及其他测试软件;
|
9.1、测试配置参数
配置文件参数: (测试文件官方文档: https://github.com/ceph/cbt/blob/v0.3/docs/TestPlanSchema.md)
common:cluster: 必需配置。Ceph 集群的详细配置,以下仅列出部分配置,详细配置: https://github.com/ceph/cbt/blob/v0.3/cluster/ceph.py#L93user:head: 表示启动集群的节点;clients: 每个客户端都是一个字符串,表示安装了基准可执行文件的可通过 ssh 访问的主机;osds: 每个节点至少有一个正在运行的 OSD 进程;mons: mon 节点列表;rgws: rgw 节点列表;mdss: mds 节点列表;mgrs: mgr 节点列表;conf_file: 如果 cbt.py 启动命令参数中指定了-c/--conf, 则会覆盖该值。如果这两处都没有指定该值,则使用默认值 /etc/ceph/ceph.conf 。use_existing: 使用现有的集群,默认为 True ;tmp_dir: 每个节点机器上的集群目录,默认为 /tmp/cbt.$PID ;rebuild_every_test: 是否每次测试前重建集群。可选配置。默认为 False 。health_wait: 默认为 5fs: 指定 osd 运行的文件系统,可选值为 tmpfs/zfs 等,无默认值;
benchmarks: 必需配置。基准部分由一个非空集合列表组成,每个集合描述一个基准测试实体。基类详细配置: https://github.com/ceph/cbt/blob/v0.3/benchmark/benchmark.py#L15nullbench: 详细配置: https://github.com/ceph/cbt/blob/v0.3/benchmark/nullbench.py#L6radosbench: 详细配置: https://github.com/ceph/cbt/blob/v0.3/benchmark/radosbench.py#L18fio: 详细配置: https://github.com/ceph/cbt/blob/v0.3/benchmark/fio.py#L16hsbench: 详细配置: https://github.com/ceph/cbt/blob/v0.3/benchmark/hsbench.py#L16rbdfio: 详细配置: https://github.com/ceph/cbt/blob/v0.3/benchmark/rbdfio.py#L15kvmrbdfio: 详细配置: https://github.com/ceph/cbt/blob/v0.3/benchmark/kvmrbdfio.py#L15rawfio: 详细配置: https://github.com/ceph/cbt/blob/v0.3/benchmark/rawfio.py#L14librbdfio: 详细配置: https://github.com/ceph/cbt/blob/v0.3/benchmark/librbdfio.py#L21cosbench: 详细配置: https://github.com/ceph/cbt/blob/v0.3/benchmark/cosbench.py#L18cephtestrados: 详细配置: https://github.com/ceph/cbt/blob/v0.3/benchmark/cephtestrados.py#L14getput: 详细配置: https://github.com/ceph/cbt/blob/v0.3/benchmark/getput.py#L16
monitoring_profiles:client_endpoints: 包含一个非空的集合列表,每个集合都与一个基准测试实体关联,通常指示基准测试的驱动程序。如果在测试计划中指定了 client_endpoints ,则基准测试部分必须对其进行交叉引用,因此,在测试计划中, client_endpoints 部分通常位于基准测试部分之前。
启动命令参数:
-a/--archive: 必需参数,用于指定结果应该存档的目录;-c/--conf: 可选参数,用于指定要使用的 ceph.conf 文件;config_file: 指定 YAML 配置文件;
9.2、测试命令示例
9.2.1、测试块存储示例
配置文件:
|
测试命令:
|
9.2.2、测试文件存储示例
配置文件:
|
测试命令:
|
9.2.3、测试对象存储示例
配置文件:
|
测试命令:
|
9.2.4、测试 ceph rados 对象存储示例
配置文件:
|
测试命令:
|
十、相关资料
- ceph 性能测试: https://ivanzz1001.github.io/records/post/ceph/2017/07/28/ceph-benchmark
- Benchmark Ceph Cluster Performance: https://tracker.ceph.com/projects/ceph/wiki/Benchmark_Ceph_Cluster_Performance
- fio github repo: https://github.com/axboe/fio
- ceph 一般基准性能测试准则: https://yourcmc.ru/wiki/Ceph_performance#General_benchmarking_principles
- Curve 块存储与 Ceph 在 nvme 场景下的性能对比: https://zhuanlan.zhihu.com/p/579733885
- SmartX 分布式块存储与商用 Ceph 存储产品性能对比: https://www.smartx.com/blog/2021/01/zbs-vs-ceph
- 提升200倍!ScaleFlash极客天成NVMatrix全闪存与Ceph全闪存性能对比: https://www.scaleflash.com/?p=32196
- vdbench存储性能测试工具: https://www.cnblogs.com/luxf0/p/13321077.html
- vdbench source code: https://www.oracle.com/downloads/server-storage/vdbench-source-downloads.html
- vdbench doc: https://goodcommand.readthedocs.io/zh_CN/v1.0.0/io_benchmark
- vdbench 的使用教程——裸盘测试和文件系统测试vdbanch: https://blog.csdn.net/bandaoyu/article/details/121568182
- Vdbench Users Guide: https://www.oracle.com/technetwork/server-storage/vdbench-1901683.pdf
- vdbench常见测试模型: https://www.cnblogs.com/xzy186/p/15944228.html
- mdtest github repo: https://github.com/hpc/ior
- mdtest wiki: https://wiki.lustre.org/MDTest
- https://ior.readthedocs.io/en/latest
- mdtest 基准测试: https://juicefs.com/docs/zh/community/mdtest
- 使用 mdtest 测试文件系统元数据性能: https://gukaifeng.cn/posts/shi-yong-mdtest-ce-shi-wen-jian-xi-tong-yuan-shu-ju-xing-neng/index.html
- iozone home: https://www.iozone.org/
- iozone 的安装及使用教程: https://blog.qiql.net/archives/iozone
- Ceph 对象存储使用: https://www.51cto.com/article/684376.html
- Ceph Object Gateway: https://docs.ceph.com/en/latest/radosgw
- Pool Placement and Storage Classes: https://docs.ceph.com/en/latest/radosgw/placement


