译 - Summary Cache: A Scalable Wide-Area Web Cache Sharing Protocol
《Summary Cache: A Scalable Wide-Area Web Cache Sharing Protocol》翻译过来是 《摘要缓存:可扩展的广域 Web 缓存共享协议》,这篇文章中提出了布隆过滤器的设计背景以及实现原理,详细介绍了在误判率以及存储空间之间的权衡,之后很多系统中实现的布隆过滤器基本都是参考了这篇文论的实现。
摘要
Web Proxy之间的共享缓存是减少Web流量并缓解网络瓶颈的一项重要技术。然而,由于现有协议的开销,它并未得到广泛部署。在本文中,我们演示了缓存共享的好处,衡量了现有协议的开销,并提出了一种称为”摘要缓存’’的新协议。在这个新协议中,每个Proxy都保留了一个包含所有Proxy的缓存摘要目录,并在任何查询之前都要检查在这些摘要之中是否存在潜在的匹配项。有两个因素利于我们协议的低开销:摘要的定期更新以及十分简朴的目录信息,每个条目只有8bits。通过使用跟踪驱动的仿真和原型实现,我们证明了与现有的协议(例如 Internet 的缓存协议ICP)相比,”摘要缓存”将缓存间协议消息的数量减少了25到60,带宽消耗减少了超过50%,消除了75%到95%的CPU处理协议开销,同时保持了与ICP几乎相同的缓存命中率。因此”摘要缓存”可以扩展到大量的Proxy。
介绍
随着万维网的巨大增长给互联网带来的持续压力,缓存已经被认为是减少带宽消耗的最重要的技术之一[29]。特别是Web代理中的缓存已经被证明十分有效[14,33]。为了获得缓存的全部好处,常见瓶颈环节后面的代理环境应该相互配合并未彼此的未命中服务,从而进一步减少通过瓶颈的流量。我们称这个过程为 “Web缓存共享”。
Web共享缓存的概念最初是在Harvest项目中被提出的[26,12]。Harvest小组设计了Internet缓存协议(ICP)[18],该协议支持从相邻的缓存中发现和检索文档。如今,很多机构和很多国家都建立了代理缓存的层次结构,这些层次结构通过ICP进行合作已减少Internet流量[25,30,41,5,14]。
然而,ICP协议的开销目前阻碍了Web共享缓存的广泛部署。ICP在代理发生缓存未命中的时候会讲查询消息多播到其他的代理来尝试在其他代理中命中该消息。因此随着代理数量的增加,通信和CPU的处理开销都将成倍的增加。
目前已经提出了很多替代协议来解决该问题,例如,一种在代理之间划分URL空间的缓存陈列路由协议[46]。但是,此类解决方案通常不适用于广域网缓存共享,其特点是代理之间的网络带宽有限以及代理与其用户之间的网络距离不均匀(例如,每个代理可能更靠近一个用户组而不是其他用户组)。
在本文中,我们解决了用于关于Web共享缓存的可伸缩协议的问题。我们首先通过分析Web访问跟踪的采集信息来检查Web共享缓存的好处。我们表明,在代理之间共享缓存的内存会显著减少Web服务器的通信量,并可简单的缓存共享(无需在代理的缓存之间进行协调)就足以获得完全协调的缓存的大部分好处。我们还通过运行一组代理基准来量化ICP协议的开销。结果表明,即使协作代理的数量低至四个,ICP也会讲代理间的流量增加70到90倍,每个代理接收到的网络数据包的数量也增加了13%甚至更多,并且CPU的开销也超过了15%。 在没有代理间缓存命中(也称为远程缓存命中)的情况下,开销可以使平均用户延迟增加多达11%。
然后,我们提出了一种称为摘要缓存的新缓存共享协议。在此协议下,每个代理都保留每个其他代理的缓存目录的简明摘要。当发生高速缓存未命中时,代理首先探测所有的摘要信息,以查看该请求是否可能是其他代理中的高速缓存命中,然后仅将查询消息发送给其摘要显示出有希望的结果的那些代理。摘要信息不一定总是准确的。如果摘要中显示的请求并没有缓存命中(错误命中),则结果就是浪费了查询消息。如果摘要中另有说明(虚假未命中)时请求是缓存命中,则结果就是较高的未命中率。
我们研究了协议设计中的两个关键问题:摘要更新的频率和摘要的表现方式。使用跟踪驱动的模拟,我们显示摘要的更新可以延迟到新的固定百分比(例如1%)的缓存文档,并且命中率将成比例降低(对于1%的选择,降级为介于0.02%至1.7%之间,具体取决于轨迹)。
为了减少内存需求,我们将每个摘要存储为”布隆过滤器”。这是一种计算效率非常高的基于哈希的概率方案,它可以表示一组具有最低内存要求的键(在我们的情况下为高速缓存目录),同时成员查询的假阴性概率为0,误报率很低。跟踪驱动的模拟表明,对于典型的代理配置,对于仅在N个字节内表示的N个缓存文档,误报的百分比为1%至2%。实际上,可以通过增加误报率为代价而进一步减少存储器。(我们稍后将更详细地描述Bloom过滤器。)
基于这些结果,我们设计了摘要缓存增强的ICP协议,并在Squid代理中实现了原型。通过使用跟踪驱动的仿真以及基准测试和跟踪重放的实验,我们证明了新协议将代理间消息的数量减少了25到60倍以上,网络带宽的消耗(以传输的字节数表示) )降低了50%以上,并减少了30%到95%的协议在CPU上开销。与没有缓存共享的情况相比,我们的实验表明,该协议只产生很少的网络流量,并且仅将CPU时间增加5%到12%,具体取决于远程缓存命中率。但是,该协议在大多数情况下都达到了类似于ICP协议的缓存命中率。
结果表明,摘要缓存增强型ICP协议可以扩展到大量代理。因此,它有可能显著增加Web缓存共享的部署并减少Internet上的Web流量。为此,我们正在将我们的实施公开发布[ 15 ],并且正在将其转移到ICP用户社区。
轨迹和模拟
表1:有关跟踪的统计信息。 命中率和字节命中率是在无限缓存下实现的。
| Traces | DEC | UCB | UPisa | Questnet | NLANR |
|---|---|---|---|---|---|
| Time(时间) | 8/29-9/4, 1996 | 9/14-9/19, 1996 | Jan-March, 1997 | 1/15-1/21, 1998 | 12/22, 1997 |
| Requests(请求数) | 3543968 | 1907762 | 2833624 | 2885285 | 1766409 |
| Infinite Cache Size(无限缓存大小) | 2.88e+10 | 1.80e+10 | 2.07e+10 | 2.33e+10 | 1.37e+10 |
| Maximum Hit Ratio(最大命中率) | 0.49 | 0.30 | 0.40 | 0.30 | 0.36 |
| Maximum ByteHit Ratio(最大字节命中率) | 0.36 | 0.14 | 0.27 | 0.15 | 0.27 |
| Client Population(客户人数) | 10089 | 5780 | 2203 | 12 | 4 |
| Client Groups(客户群) | 16 | 8 | 8 | 12 | 4 |
在我们的研究中,我们收集了五组HTTP请求的痕迹。表1中列出了每个跟踪中的请求数,客户端数以及其他统计信息 。特别是,表1列出了每个跟踪的”无限’’缓存大小,即跟踪中唯一文档的总大小(以字节为单位)(即”无限’’缓存的大小,不会导致缓存的替换)。
DEC跟踪[32]:Digital Equipment Corporation Web代理服务器跟踪,为大约
17,000个工作站提供服务。跟踪持续25天(1996年8月29日至9月21日)。我们将跟踪分为三个1周和1个半周的跟踪。由于交换空间的限制,我们的模拟器只能模拟子迹线。在本文中,我们介绍了1996年8月29日至9月4日这一周的迹线结果。其他迹线的结果非常相似。UCB跟踪[24]:从UC Berkeley向其学生,教职员工提供的家庭IP服务收集的HTTP请求的跟踪。从1996年11月1日到11月19日,总迹线为期18天,并分为四个子迹线,每四或五天一次。我们在11月14日至11月19日的跟踪中显示结果。尽管该跟踪最初记录了2,468,890个请求,但其中许多响应数据大小为0或1,因此我们决定忽略这些请求。同样,我们在UCB集合中的其他迹线上进行了仿真,结果与此处介绍的相似。
UPisa跟踪[43]:意大利比萨大学计算机科学系的用户在1997年1月至3月的三个月内对HTTP请求的跟踪。在跟踪中,我们仅模拟GET请求,并且仅网址不包含查询字符串的用户,因为大多数代理不缓存查询请求。
Questnet追踪[47]:1998年1月15日至1月21日,父级代理在Questnet(澳大利亚的区域网络)中看到的HTTP请求日志为7天,这些代理服务于大约12个父级代理区域网络中的子代理。我们提取父代理看到的成功GET请求。因此,跟踪只是进入十个代理的用户请求的子集。不幸的是,用户对代理的完整请求集不可用。
NLANR跟踪 [40]:由NLANR(应用网络研究国家实验室)向国家高速缓存层次结构中的四个主要父代理高速缓存发送HTTP请求的一日日志(1997年12月22日)。国家缓存层次结构中大约有八个代理,但是只有四个代理(“ bo”,“ pb”,“ sd”和“ uc”)处理来自.com,.net,.edu和其他主要领域。因此,我们决定仅模拟对四个代理的请求。
在我们的缓存共享模拟中,我们将DEC,UCB和UPisa中的客户端分为几组,假设每个组都有自己的代理,并模拟代理之间的缓存共享。这大致对应于以下情况:
公司的每个分支机构或大学中的每个部门都有自己的代理缓存,并且这些缓存协作。我们将DEC,UCB和UPisa迹线中的组数分别设置为16、8和8。如果客户端的clientID与组大小相等,则将其放入组中。尽管该模拟并不完全符合实际情况,但我们相信它确实带来了有关缓存共享协议的见识。Questnet跟踪包含从区域网络中的一组子代理到父代理的HTTP请求。我们假设这些是进入子代理的请求(因为子代理将其缓存未命中发送给父代理),并且模拟了子代理之间的缓存共享。最后,NLANR跟踪包含去往四个主要代理的实际HTTP请求,我们模拟了它们之间的缓存共享。
在所有模拟中,我们将LRU用作缓存替换算法,但要注意的是,不能缓存大于250KB的文档。该策略类似于实际代理中使用的策略。我们不会根据年龄或生存时间来模拟到期的文档。而是,我们的大多数跟踪记录都包含每个请求的文档的上次修改时间,如果用户请求命中了上次修改时间已更改的文档,我们会将其视为缓存未命中。换句话说,我们假设缓存一致性机制是完美的。在实践中,有各种协议[12],[34],[28]为Web缓存的一致性。
我们的大多数模拟都假设缓存大小是”无限’’缓存大小的10%。研究表明,该”无限”的缓存大小的10%通常实现关于最大缓存命中率[90% [49],[8],[35] ]。我们还执行了高速缓存大小为无限高速缓存大小5%的仿真,结果非常相似。
缓存共享的好处
最近的研究 [8],[23],[14]表明,在无限的缓存容量下,Web缓存命中率似乎与缓存所服务的用户数量成对数增长。 显然,来自不同用户的请求重叠减少了冷数据的miss,这通常是高速缓存未命中的重要部分,因为首次引用文档和文档修改都会对它们造成影响。
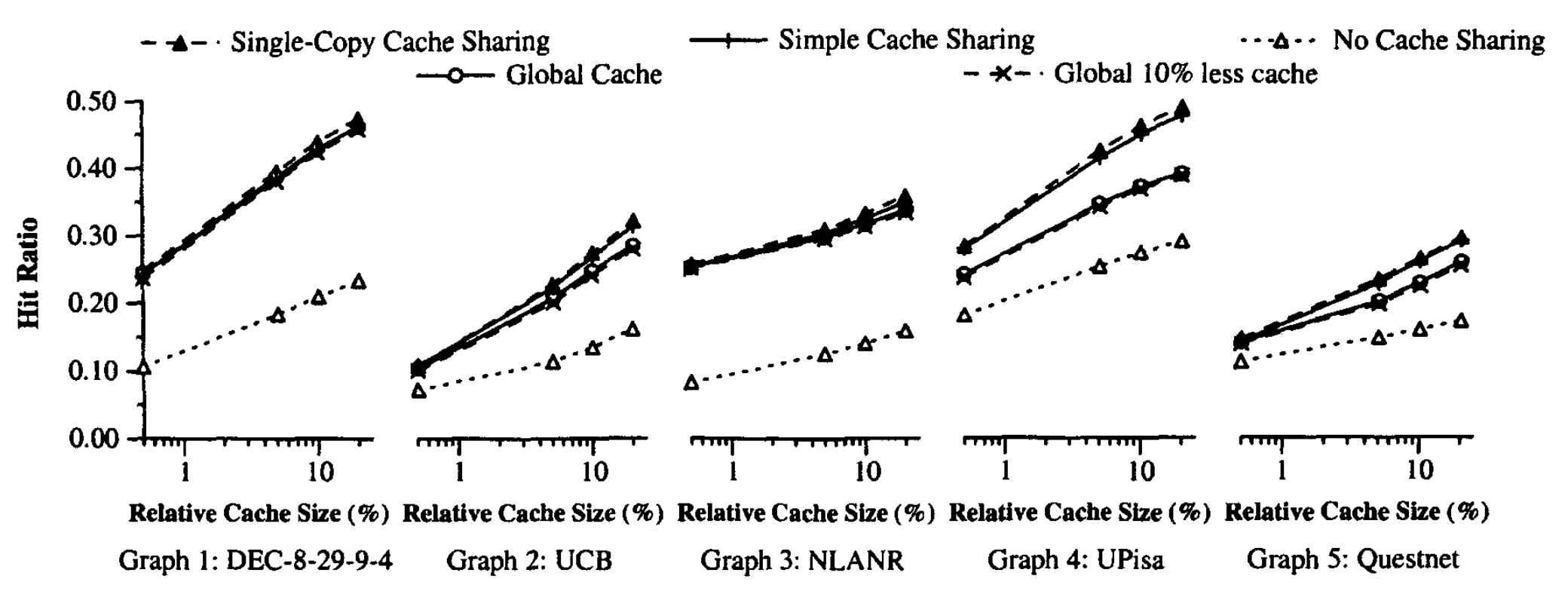
为了检查有限缓存大小下的缓存共享的好处,我们使用上一节中列出的跟踪信息模拟以下方案:
- 无缓存共享:代理通过不协作的方式来服务彼此的缓存未命中;
- 简单的缓存共享:代理服务彼此的缓存未命中。代理从另一个代理中获取文档后,便会在本地缓存该文档。代理通过不协调的方式进行缓存替换。这是由ICP协议实现的共享;
- 单副本缓存共享:代理服务彼此的缓存未命中,但是一个代理不缓存从另一个代理获取的文档。而是,另一个代理将文档标记为最近访问的文档,并增加了其缓存优先级。与简单的缓存共享相比,此方案消除了重复副本的存储并提高了可用缓存空间的利用率;
- 全局缓存:代理共享缓存内容并协调替换,以便它们显示为一个统一的缓存,对用户而言具有全局LRU替换。这是协作缓存的完全协调形式。我们通过假设所有请求都转到一个缓存的大小来模拟该方案,该缓存的大小是所有代理缓存大小的总和;.
为了回答两个问题,我们研究了这些方案:简单的缓存共享是否会显著减少Web服务器的流量,更紧密的协调方案是否会导致命中率显著提高。
图1 显示了当每个跟踪的缓存大小分别设置为”无限缓存大小’’(完全避免替换所需的最小高速缓存大小)大小的 0.5%,5%,10% 和 20% 时考虑的不同方案下的命中率。字节命中率的结果非常相似,由于空间限制,我们将其省略。
通过查看 图1,我们了解到,首先所有缓存共享方案比没有缓存共享显著提高了命中率。结果充分证实了共享缓存的好处,即使使用了很小的缓存。
其次,单拷贝缓存共享和简单的缓存共享下的命中率通常与全局缓存下的命中率相同甚至更高。我们认为,原因是全局LRU有时表现不如逐组LRU。特别是,在全局缓存设置中,来自一个用户的快速连续请求突发可能会干扰许多用户的工作集。在单副本缓存共享或简单缓存共享中,每个缓存专用于特定的用户组,并且来自每个组的流量争夺单独的缓存空间。因此,缓存穿透只包含在特定组中。
第三,将单副本缓存共享与简单的缓存共享进行比较时,我们发现浪费空间仅会产生很小的影响。原因是有效缓存略小,命中率没有明显差异。为了证明这一点,我们还使用比原始缓存小 10% 的全局缓存运行模拟。从 图1 可以看出,差异很小。
因此,尽管它很简单,但 ICP 类型的简单的缓存共享却获得了更精细的协作缓存的大部分好处。** 简单的缓存共享**不会通过将内容从繁忙的缓存移动到较不繁忙的缓存来执行任何负载平衡,并且无法通过仅保留每个文档的一个副本来节省空间。 但是,如果正确地完成了每个代理的资源规划,则无需执行负载平衡并产生更紧密协调方案的开销。
最后,请注意该结果是根据第2节中所述的LRU替换算法获得的。不同的替换算法[8]可能给出不同的结果。 此外,单独的仿真已确认,在严重的负载不平衡的情况下,全局缓存将具有更好的缓存命中率,因此,重要的是分配每个代理的缓存大小,使其与用户群大小和预期使用成比例。
ICP的开销
表2:在四个代理情况下的ICP开销。 SC-ICP协议在第6节中介绍,稍后将进行说明。 实验进行了3次,每次测量的方差在括号中列出。 开销信息的行列出了每次测量的无ICP百分比增加。 请注意,在合成实验中没有代理间缓存命中。
| Exp 1 | Hit Ratio | Client Latency | User CPU | System CPU | UDP Msgs | TCP Msgs | Total Packets |
|---|---|---|---|---|---|---|---|
| no ICP | 25% | 2.75 (5%) | 94.42 (5%) | 133.65 (6%) | 615 (28%) | 334K (8%) | 355K(7%) |
| ICP | 25% | 3.07 (0.7%) | 116.87 (5%) | 146.50 (5%) | 54774 (0%) | 328K (4%) | 402K (3%) |
| Overhead | 12% | 24% | 10% | 9000% | 2% | 13% | |
| SC-ICP | 25% | 2.85 (1%) | 95.07 (6%) | 134.61 (6%) | 1079 (0%) | 330K (5%) | 351K (5%) |
| Overhead | 4% | 0.7% | 0.7% | 75% | -1% | -1% | |
| Exp 2 | Hit Ratio | Client Latency | User CPU | System CPU | UDP Msgs | TCP Msgs | Total Packets |
| no ICP | 45% | 2.21 (1%) | 80.83 (2%) | 111.10 (2%) | 540 (3%) | 272K (3%) | 290K (3%) |
| ICP | 45% | 2.39 (1%) | 97.36 (1%) | 118.59 (1%) | 39968 (0%) | 257K (2%) | 314K (1%) |
| Overhead | 8% | 20% | 7% | 7300% | -1% | 8% | |
| SC-ICP | 45% | 2.25 (1%) | 82.03 (3%) | 111.87 (3%) | 799 (5%) | 269K (5%) | 287K (5%) |
| Overhead | 2% | 1% | 1% | 48% | -1% | -1% |
Internet缓存协议(ICP)[18]在鼓励世界各地的Web缓存共享实践方面非常成功。 它需要代理之间的松散协调,并且基于UDP构建以提高效率。 它是由Harvest研究小组[26]设计的,并得到了公共领域Squid [19]代理软件和当今一些商业产品的支持。 随着Squid代理在全球的部署,ICP被全球很多国家广泛使用,以减少跨大西洋和跨太平洋链接的流量。
尽管ICP取得了成功,但它并不是一个可扩展的协议。 问题在于ICP依赖查询来查找远程缓存命中。 每当一个代理遇到高速缓存未命中时,其他所有人都会收到查询消息并进行处理。 随着协作代理服务器数量的增加,开销很快就会让人望而却步。
为了衡量ICP的开销及其对代理性能的影响,我们使用了我们设计的代理基准进行了实验[1]。 (该基准已作为行业标准基准的候选者提交给SPEC,目前已在许多代理系统供应商中使用)。该基准测试由一系列客户端进程组成,这些客户端进程按照实际跟踪中观察到的模式(包含请求大小的分布和时间局限性)发出请求, 以及一组服务器的进程,这些服务器进程会延迟答复以模拟Internet中的延迟。
实验是在 10 个与 100Mb/s 以太网连接的 Sun Sparc-20 工作站上进行的。四个工作站充当四个代理系统,运行 Squid 1.1.14 ,每个工作站具有75MB的缓存空间。缓存大小被人为的变小,因此在实验的短时间内就会发生缓存替换。另外四个工作站运行 120 个客户端进程,每个工作站上运行 30 个进程。每个工作站上的客户端进程都连接到代理之一。客户进程发出请求时没有思考时间,请求的文档大小遵循Pareto分布,其中 $ \alpha = 1.1 $ 和 $k = 3.0$ [9]。最后,两个工作站充当服务器,每个工作站监听 15 个不同的端口。Web服务器在处理HTTP请求时复制一个进程,该进程等待 1秒钟,然后发送答复以模拟网络延迟。
我们尝试使用两种不同的缓存命中率,分别为 25% 和 45%,因为ICP的开销随每个代理中的缓存未命中率而变化。在基准测试中,客户端按照[35,8]中观察到的时间局部性模式发出请求,并且可以调整请求流中的固有缓存命中率。在一个实验中,每个客户端进程发出 200 个请求,总共 24000个请求。
通过使用基准测试,我们比较了两种配置:无ICP(代理不协作) 和 ICP(代理通过ICP协作)。由于我们仅对负载开销感兴趣,因此客户端发出的请求不会重叠,并且代理之间没有远程缓存命中。对于ICP,这是最坏的情况,结果可以衡量协议的开销。我们在no-ICP和ICP实验中的随机数生成器中使用相同的种子,以确保可比较的结果,否则的话,繁重文档的大小分布和我们的低请求数会导致高方差。在不同种子环境下,无ICP和ICP之间的相对差异是相同的。 我们在这里提供一组实验的结果。
我们测量缓存中的命中率,客户端看到的平均延迟,Squid代理消耗的CPU时间(根据用户CPU时间和系统CPU时间以及网络流量)。我们使用netstat收集发送和接收的UDP数据报的数量,发送和接收的TCP数据包以及以太网接口处理的IP数据包的总数。第三个采集的信息大约是前两个采集信息的数字之和。 ICP查询和回复消息会产生UDP流量。 TCP通信包括代理与服务器之间以及代理与客户端之间的HTTP通信。 结果示于 表2。
结果表明,即使协作代理的数量低至四个,ICP也会产生可观的开销。UDP消息的数量增加了大概 73 到 90。由于UDP消息的增加,代理看到的总网络流量增加了 8% 至 13%。协议处理将用户CPU时间增加 20% 至 24% ,而UDP消息处理将系统CPU时间增加 7% 至 10% 。反映给客户端,HTTP请求的平均延迟增加了 8% 至 11% 。尽管实验是在高速局域网上进行的,但仍会发生性能下降。
结果凸显了Web缓存管理员面临的困境。 缓存共享有明显的好处,但是ICP的开销很高。此外,大多数时候,由于没有缓存文档,因此浪费了查询消息的处理时间。从本质上讲,在处理ICP上花费的精力与其他代理所经历的缓存未命中总数成正比,而不是与实际的远程缓存命中数成正比。
为了解决该问题,我们提出了一种新的可伸缩缓存共享协议:摘要缓存。
摘要缓存
在摘要缓存方案中,每个代理在每个其他代理中存储其缓存文档目录的摘要。当用户请求未在本地缓存中丢失时,本地代理会检查存储的摘要,以查看请求的文档是否可能存储在其他代理中。如果出现这种情况,则代理会将请求发送到相关代理以获取文档。 否则,代理将请求直接发送到Web服务器。
该方案可扩展性的关键是摘要不必是最新的或准确的。每次更改缓存目录时都不必更新摘要。 相反,更新可以按固定的时间间隔进行,也可以在摘要中未反映一定百分比的缓存文档时进行。摘要只需要包含在内(即,描述存储在缓存中的文档的超集),以避免影响总缓存命中率。 也就是说,可以容忍两种错误:
假的未命中:所请求的文档被缓存在其他代理服务器上,但是其摘要未反映该事实。 在这种情况下,不利用远程高速缓存命中,并且降低了高速缓存集合中的总命中率。
假的命中:所请求的文档未在其他代理处缓存,但其摘要表明已缓存。 代理将向另一个代理发送查询消息,仅通知该文件未缓存在该代理中。 在这种情况下,浪费了查询消息。
该错误会影响总缓存命中率或代理间流量,但不会影响缓存方案的正确性。例如,错误的命中不会导致送达错误的文档。 通常,我们会努力降低误报率,因为误报会增加Internet的流量,而缓存共享的目标是减少到Internet的流量。
摘要缓存和ICP中都会发生第三种错误,即远程过时命中。远程过时命中是指文档在另一个代理处缓存,但是缓存的副本是过时的。远程过时命中并不一定是浪费精力,因为可以使用增量压缩来传输新文档[39]。 但是,它确实有助于代理间的通信。
有两个因素限制了摘要缓存的可伸缩性:网络开销(代理间通信)和存储摘要所需的内存(出于性能原因,摘要应存储在DRAM中,而不是磁盘上)。网络开销取决于摘要更新的频率以及错误匹配和远程匹配的数量。内存需求取决于各个摘要的大小和协作代理的数量。由于内存随代理的数量线性增长,因此保持单个摘要较小很重要。下面,我们首先介绍更新频率,然后讨论各种摘要表示。
更新延迟的影响
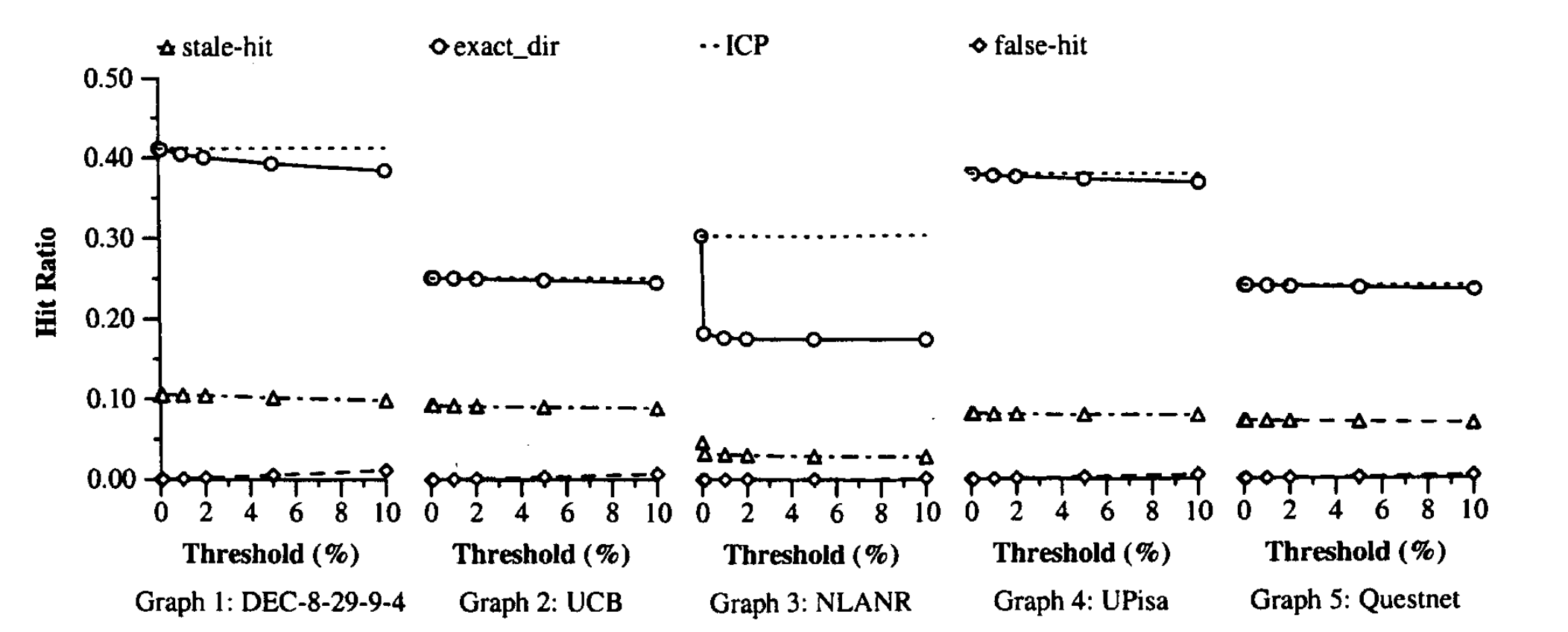
我们调查延迟摘要的更新,直到 “新”(即未反映在摘要中)缓存文档的百分比达到阈值为止。选择阈值标准是因为错误遗漏的数量(以及总命中率的下降)往往与未反映在摘要中的文档数量成正比。另一种方法是按固定的时间间隔更新摘要。可以通过将间隔转换为阈值来得出这种方法下的误漏率。也就是说,根据请求率和典型的高速缓存未命中率,可以计算出每个时间间隔内有多少新文档进入高速缓存及其在高速缓存文档中的百分比。
使用跟踪,我们可以模拟阈值分别为已缓存文档的 0.1%,1%,2%,5% 和 10%时总缓存命中率。目前,我们忽略摘要表示的问题,并假设摘要是缓存目录(即文档URL列表)的副本。结果如 图2 所示。图中第一行是未引入更新延迟时的命中率。第二行显示了命中率随着更新延迟的增加。这两行之间的差异是误漏率。底部的两条曲线显示了远程过时命中的比率和错误命中的比率(延迟的确引入了一些错误命中,因为从缓存中删除的文档可能仍存在于摘要中)。
结果表明,除了NLANR的跟踪数据外,总缓存命中率的下降几乎随更新阈值线性增长。在 1% 的阈值下,命中率相对降低为 0.2%(UCB),0.1%(UPisa),0.3%(Questnet) 和 1.7%(DEC)。 远程陈旧命中率几乎不受更新延迟的影响。虚假命中率非常小,因为摘要是缓存目录的精确副本,尽管它确实随阈值线性增加。
对于 NLANR跟踪,似乎某些客户端正在同时将两个完全相同的文档请求发送到代理”bo”和NLANR集合中的另一个代理。如果仅在NLANR中模拟其他三个代理,则结果与其他跟踪的结果类似。在包含”bo’’的情况下,我们还模拟了 2个用户请求 和 10个用户请求 的延迟,命中率分别从 30.7% 降至 26.1% 和 20.2% 。在 0.1% 的阈值处的命中率大约为 18.4%,大约等于200个用户请求。因此,我们认为命中率的急剧下降是由于NLANR迹线中的异常引起的。不幸的是,我们无法确定有问题的客户端,因为跨NLANR跟踪的客户端ID不一致[40]。
结果表明,实际上,摘要更新延迟阈值为 1% 到 10% 时会导致高速缓存命中率的可容忍度降低。对于这五个跟踪,阈值在两次更新之间转换成大约 300 到 3000 个用户请求,平均而言,大约 每5分钟到一个小时更新一次。因此,这些更新的带宽消耗可能非常低。
摘要表示
影响可伸缩性的第二个问题是摘要的大小。摘要信息需要存储在主内存中,不仅因为内存查找要快得多,而且因为磁盘臂通常是代理缓存中的瓶颈[36]。尽管DRAM价格继续下降,但由于内存需求随代理数量线性增长,因此我们仍需要仔细设计。摘要信息还会使DRAM脱离热文档的内存高速缓存,从而影响代理性能。因此,重要的是要使摘要变小。幸运的是,摘要只需包含所有内容(即,描述存储在缓存中的文档的超集),即可避免影响缓存命中率。
我们首先研究两个简单的摘要表示形式:确切目录和服务器名称。在精确目录方法中,摘要基本上是缓存目录,每个URL均由其16字节MD5签名表示[38,22]。在服务器名称方法中,摘要是缓存中URL的服务器名称部分的列表。平均来看,不同URL与不同服务器名称的比率约为 10:1(从我们的跟踪记录中可以看到),因此服务器名称方法可以将内存减少10倍。
我们使用跟踪来模拟这些方法,发现它们都不令人满意。结果在图7中,以及在另一个摘要表示中的结果(在5.2节中详细讨论了图7)。精确目录方法消耗太多内存。实际上,代理通常具有8GB至20GB的缓存空间。如果我们假设16个代理服务器每个8GB,平均文件大小为8KB,则精确目录摘要将消耗**(16 -1)* 16 (8GB / 8KB)=每个代理240MB主内存*。服务器名称方法虽然消耗较少的内存,但会产生过多的错误命中,从而大大增加了网络消息。
理想的摘要表示形式的要求是小尺寸和低假命中率。 经过几次其他尝试,我们找到了一种称为布隆过滤器的古老技术的解决方案。
布隆过滤器-数学
布隆过滤器是一种可以用来在 $n$ 个元素(也被叫做Keys)的集合 $A = \{{a_1,a_2,...,a_n}\}$ 中查询成员的方法。
它由Burton Bloom在1970年发明,并被Marais和Bharat提出在Web的上下文中使用,作为一种机制用来识别哪些页面已经被存储在 CommonKnowledge 服务器中。

这个想法(如图3所示)就是分配一个拥有 $m$ 个比特位的向量 $v$,最初全部设置为0,然后选择 $k$ 个独立的哈希函数,$h_1,h_2,…,h_k$,每一个的范围都是 ${1,…,m}$,对于每个元素 $a \in A$ ,$v$ 中处于位置 $h_1(a),h_2(a),….,h_k(a)$ 的位置都设置为 $1$ (一个特定的位置可能会被多次设置为 $1$)。当查询 $b$ 的时候,我们会检查 $h_1(b),h_2(b),…,h_k(b)$ 位置上的比特值。如果他们中的任何一个值为 $0$ , $b$ 就肯定不在集合 $A$ 中。
尽管存在一定的可能性我们会判断错误,$b$ 本身不在集合中,但我们推测 $b$ 在集合中,这就被称为误报。 这种情况在历史上也叫做 “假阴性”。我们应该通过参数 $k$ 和 $m$ ,以使误报率(因此导致错误命中的概率)处在可接受的范围之内 。
布隆过滤器的显著特征是:在 $m$ 与误报的概率之间存在明显的折衷。通过观察发现在将 $n$ 个key插入到大小为 $m$ 的表中之后,某一个比特位仍然为 $0$ 的概率正好是:$(1-\displaystyle \frac{1}{m})^{kn}$
因此,在这种情况下误报的概率为:$(1-(1-\displaystyle \frac{1}{m})^{kn})^k \approx (1 - e^{-\frac{kn}{m}})^k$
在右面的值最小的情况下,$k$ 的值为:$k=ln2 * \displaystyle \frac{m}{n}$ ,在这种情况下:$(\displaystyle \frac{1}{2})^k = (0.6185)^\frac{m}{n}$
由于 $k$ 必须是整数,并且实际上我们可以选择一个小于最佳值的值以减少计算开销。 一些示例值是:
表3 到 表5 列出了 $\displaystyle \frac{m}{n}$ 和 $k$ 的常见组合的误报率情况。
表3: 在各种 m/n 和 $k$ 组合下的误判率。
| m/n | k | k=1 | k=2 | k=3 | k=4 | k=5 | k=6 | k=7 | k=8 |
|---|---|---|---|---|---|---|---|---|---|
| 2 | 1.39 | 0.393 | 0.400 | ||||||
| 3 | 2.08 | 0.283 | 0.237 | 0.253 | |||||
| 4 | 2.77 | 0.221 | 0.155 | 0.147 | 0.160 | ||||
| 5 | 3.46 | 0.181 | 0.109 | 0.092 | 0.092 | 0.101 | |||
| 6 | 4.16 | 0.154 | 0.0804 | 0.0609 | 0.0561 | 0.0578 | 0.0638 | ||
| 7 | 4.85 | 0.133 | 0.0618 | 0.0423 | 0.0359 | 0.0347 | 0.0364 | ||
| 8 | 5.55 | 0.118 | 0.0489 | 0.0306 | 0.024 | 0.0217 | 0.0216 | 0.0229 | |
| 9 | 6.24 | 0.105 | 0.0397 | 0.0228 | 0.0166 | 0.0141 | 0.0133 | 0.0135 | 0.0145 |
| 10 | 6.93 | 0.0952 | 0.0329 | 0.0174 | 0.0118 | 0.00943 | 0.00844 | 0.00819 | 0.00846 |
| 11 | 7.62 | 0.0869 | 0.0276 | 0.0136 | 0.00864 | 0.0065 | 0.00552 | 0.00513 | 0.00509 |
| 12 | 8.32 | 0.08 | 0.0236 | 0.0108 | 0.00646 | 0.00459 | 0.00371 | 0.00329 | 0.00314 |
| 13 | 9.01 | 0.074 | 0.0203 | 0.00875 | 0.00492 | 0.00332 | 0.00255 | 0.00217 | 0.00199 |
| 14 | 9.7 | 0.0689 | 0.0177 | 0.00718 | 0.00381 | 0.00244 | 0.00179 | 0.00146 | 0.00129 |
| 15 | 10.4 | 0.0645 | 0.0156 | 0.00596 | 0.003 | 0.00183 | 0.00128 | 0.001 | 0.000852 |
| 16 | 11.1 | 0.0606 | 0.0138 | 0.005 | 0.00239 | 0.00139 | 0.000935 | 0.000702 | 0.000574 |
| 17 | 11.8 | 0.0571 | 0.0123 | 0.00423 | 0.00193 | 0.00107 | 0.000692 | 0.000499 | 0.000394 |
| 18 | 12.5 | 0.054 | 0.0111 | 0.00362 | 0.00158 | 0.000839 | 0.000519 | 0.00036 | 0.000275 |
| 19 | 13.2 | 0.0513 | 0.00998 | 0.00312 | 0.0013 | 0.000663 | 0.000394 | 0.000264 | 0.000194 |
| 20 | 13.9 | 0.0488 | 0.00906 | 0.0027 | 0.00108 | 0.00053 | 0.000303 | 0.000196 | 0.00014 |
| 21 | 14.6 | 0.0465 | 0.00825 | 0.00236 | 0.000905 | 0.000427 | 0.000236 | 0.000147 | 0.000101 |
| 22 | 15.2 | 0.0444 | 0.00755 | 0.00207 | 0.000764 | 0.000347 | 0.000185 | 0.000112 | 7.46e-05 |
| 23 | 15.9 | 0.0425 | 0.00694 | 0.00183 | 0.000649 | 0.000285 | 0.000147 | 8.56e-05 | 5.55e-05 |
| 24 | 16.6 | 0.0408 | 0.00639 | 0.00162 | 0.000555 | 0.000235 | 0.000117 | 6.63e-05 | 4.17e-05 |
| 25 | 17.3 | 0.0392 | 0.00591 | 0.00145 | 0.000478 | 0.000196 | 9.44e-05 | 5.18e-05 | 3.16e-05 |
| 26 | 18 | 0.0377 | 0.00548 | 0.00129 | 0.000413 | 0.000164 | 7.66e-05 | 4.08e-05 | 2.42e-05 |
| 27 | 18.7 | 0.0364 | 0.0051 | 0.00116 | 0.000359 | 0.000138 | 6.26e-05 | 3.24e-05 | 1.87e-05 |
| 28 | 19.4 | 0.0351 | 0.00475 | 0.00105 | 0.000314 | 0.000117 | 5.15e-05 | 2.59e-05 | 1.46e-05 |
| 29 | 20.1 | 0.0339 | 0.00444 | 0.000949 | 0.000276 | 9.96e-05 | 4.26e-05 | 2.09e-05 | 1.14e-05 |
| 30 | 20.8 | 0.0328 | 0.00416 | 0.000862 | 0.000243 | 8.53e-05 | 3.55e-05 | 1.69e-05 | 9.01e-06 |
| 31 | 21.5 | 0.0317 | 0.0039 | 0.000785 | 0.000215 | 7.33e-05 | 2.97e-05 | 1.38e-05 | 7.16e-06 |
| 32 | 22.2 | 0.0308 | 0.00367 | 0.000717 | 0.000191 | 6.33e-05 | 2.5e-05 | 1.13e-05 | 5.73e-06 |
表4: 在各种 $m/n$ 和 $k$ 组合下的误判率。
| m/n | k | k=9 | k=10 | k=11 | k=12 | k=13 | k=14 | k=15 | k=16 |
|---|---|---|---|---|---|---|---|---|---|
| 11 | 7.62 | 0.00531 | |||||||
| 12 | 8.32 | 0.00317 | 0.00334 | ||||||
| 13 | 9.01 | 0.00194 | 0.00198 | 0.0021 | |||||
| 14 | 9.7 | 0.00121 | 0.0012 | 0.00124 | |||||
| 15 | 10.4 | 0.000775 | 0.000744 | 0.000747 | 0.000778 | ||||
| 16 | 11.1 | 0.000505 | 0.00047 | 0.000459 | 0.000466 | 0.000488 | |||
| 17 | 11.8 | 0.000335 | 0.000302 | 0.000287 | 0.000284 | 0.000291 | |||
| 18 | 12.5 | 0.000226 | 0.000198 | 0.000183 | 0.000176 | 0.000176 | 0.000182 | ||
| 19 | 13.2 | 0.000155 | 0.000132 | 0.000118 | 0.000111 | 0.000109 | 0.00011 | 0.000114 | |
| 20 | 13.9 | 0.000108 | 8.89e-05 | 7.77e-05 | 7.12e-05 | 6.79e-05 | 6.71e-05 | 6.84e-05 | |
| 21 | 14.6 | 7.59e-05 | 6.09e-05 | 5.18e-05 | 4.63e-05 | 4.31e-05 | 4.17e-05 | 4.16e-05 | 4.27e-05 |
| 22 | 15.2 | 5.42e-05 | 4.23e-05 | 3.5e-05 | 3.05e-05 | 2.78e-05 | 2.63e-05 | 2.57e-05 | 2.59e-05 |
| 23 | 15.9 | 3.92e-05 | 2.97e-05 | 2.4e-05 | 2.04e-05 | 1.81e-05 | 1.68e-05 | 1.61e-05 | 1.59e-05 |
| 24 | 16.6 | 2.86e-05 | 2.11e-05 | 1.66e-05 | 1.38e-05 | 1.2e-05 | 1.08e-05 | 1.02e-05 | 9.87e-06 |
| 25 | 17.3 | 2.11e-05 | 1.52e-05 | 1.16e-05 | 9.42e-06 | 8.01e-06 | 7.1e-06 | 6.54e-06 | 6.22e-06 |
| 26 | 18 | 1.57e-05 | 1.1e-05 | 8.23e-06 | 6.52e-06 | 5.42e-06 | 4.7e-06 | 4.24e-06 | 3.96e-06 |
| 27 | 18.7 | 1.18e-05 | 8.07e-06 | 5.89e-06 | 4.56e-06 | 3.7e-06 | 3.15e-06 | 2.79e-06 | 2.55e-06 |
| 28 | 19.4 | 8.96e-06 | 5.97e-06 | 4.25e-06 | 3.22e-06 | 2.56e-06 | 2.13e-06 | 1.85e-06 | 1.66e-06 |
| 29 | 20.1 | 6.85e-06 | 4.45e-06 | 3.1e-06 | 2.29e-06 | 1.79e-06 | 1.46e-06 | 1.24e-06 | 1.09e-06 |
| 30 | 20.8 | 5.28e-06 | 3.35e-06 | 2.28e-06 | 1.65e-06 | 1.26e-06 | 1.01e-06 | 8.39e-06 | 7.26e-06 |
| 31 | 21.5 | 4.1e-06 | 2.54e-06 | 1.69e-06 | 1.2e-06 | 8.93e-07 | 7e-07 | 5.73e-07 | 4.87e-07 |
| 32 | 22.2 | 3.2e-06 | 1.94e-06 | 1.26e-06 | 8.74e-07 | 6.4e-07 | 4.92e-07 | 3.95e-07 | 3.3e-07 |
表5: 在各种 m/n 和 $k$ 组合下的误判率。
| m/n | k | k=17 | k=18 | k=19 | k=20 | k=21 | k=22 | k=23 | k=24 |
|---|---|---|---|---|---|---|---|---|---|
| 22 | 15.2 | 2.67e-05 | |||||||
| 23 | 15.9 | 1.61e-05 | |||||||
| 24 | 16.6 | 9.84e-06 | 1e-05 | ||||||
| 25 | 17.3 | 6.08e-06 | 6.11e-06 | 6.27e-06 | |||||
| 26 | 18 | 3.81e-06 | 3.76e-06 | 3.8e-06 | 3.92e-06 | ||||
| 27 | 18.7 | 2.41e-06 | 2.34e-06 | 2.33e-06 | 2.37e-06 | ||||
| 28 | 19.4 | 1.54e-06 | 1.47e-06 | 1.44e-06 | 1.44e-06 | 1.48e-06 | |||
| 29 | 20.1 | 9.96e-07 | 9.35e-07 | 9.01e-07 | 8.89e-07 | 8.96e-07 | 9.21e-07 | ||
| 30 | 20.8 | 6.5e-07 | 6e-07 | 5.69e-07 | 5.54e-07 | 5.5e-07 | 5.58e-07 | ||
| 31 | 21.5 | 4.29e-07 | 3.89e-07 | 3.63e-07 | 3.48e-07 | 3.41e-07 | 3.41e-07 | 3.48e-07 | |
| 32 | 22.2 | 2.85e-07 | 2.55e-07 | 2.34e-07 | 2.21e-07 | 2.13e-07 | 2.1e-07 | 2.12e-07 | 2.17e-07 |
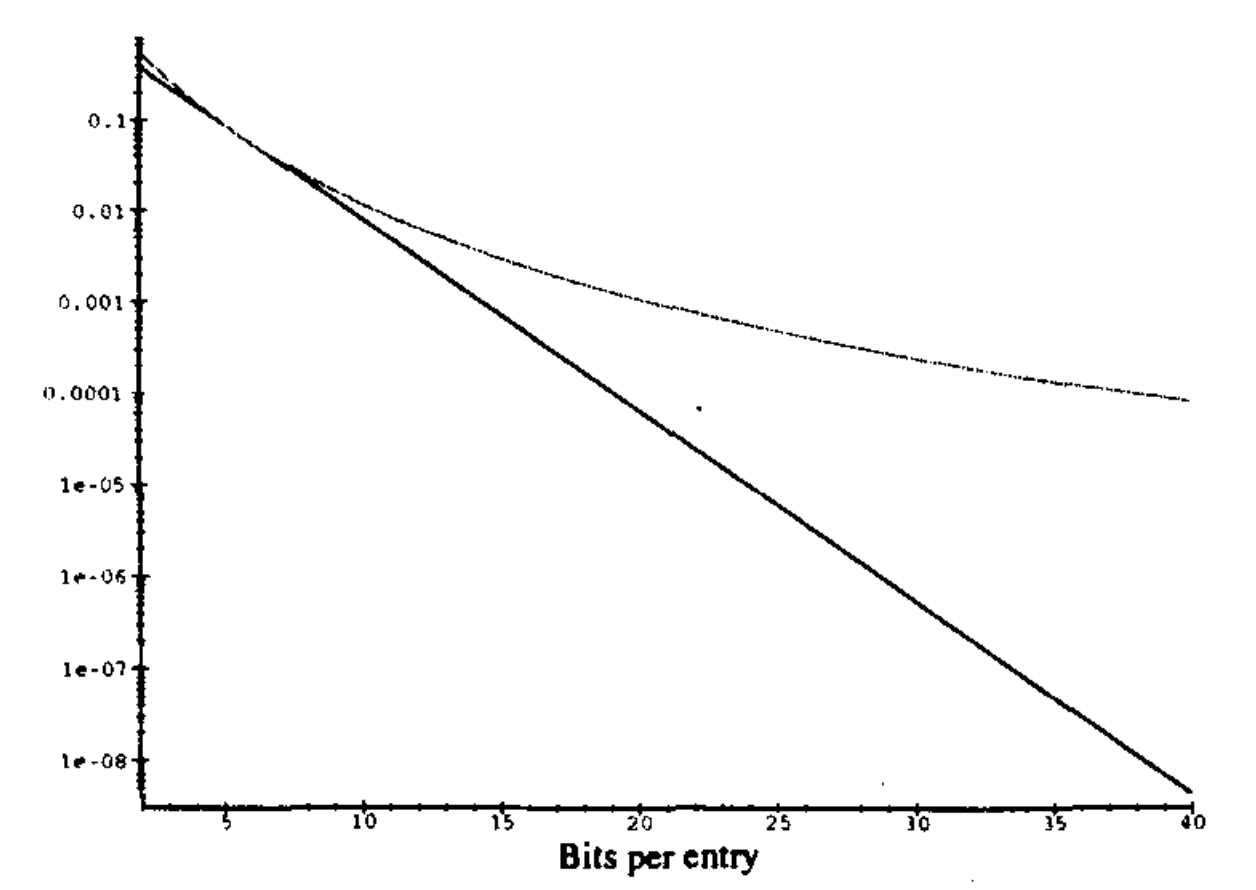
图4 中的曲线图显示了误判率与分配给每个条目的位数的关系,即比率为: $\alpha = n / m $ 。上面的曲线是针对 4个哈希函数的情况。下面的曲线是散列函数的最佳数量。标度是对数的,因此观察到的直线对应于指数下降。显然,由于布隆过滤器中每个Key只有很少的存储空间,因此存在一些误报的轻微风险。例如,对于一个比Key数量大10倍的位数组,在使用4个散列函数的情况下,误报率大概为1.2%,使用5个散列函数的情况下,误报的概率为0.9%。 我们也可以通过分配更多的内存来轻松降低误报率。
由于在我们的上下文中,每个代理都维护一个本地布隆过滤器来存储自己的缓存文档,因此集合 $A$ 必须支持修改。这是通过为位数组中的每个位置 $\tau$ 维持该位被设置为 $1$ 的次数 $c(\tau)$(即散列值为 $\tau$ 的元素的数量)的计数来完成的。所有的计数最初都为0。当我们插入或者删除键 $a$ (在我们示例的文档中为URL)的时候,计数 $c(h_1(a),h_2(a),…h_k(a))$ 相应的增加或者减少。当计数从0变为1的时候,相应的位被打开,当计数从1变为0的时候,相应的位将关闭,因此,本地的布隆过滤器始终正确反应当前目录。
由于我们还需要为计数分配内存,因此重要的是要知道它们可以变为多大。 将具有 $k$ 个散列函数的 $n$ 个密钥插入大小为 $m$ 的位数组后,估计预期最大计数为(参见[22,第72页])
$T^{-1}{(m)}(1 + \displaystyle \frac{ln(kn/m)}{ln T^{-1}(m)} + O(\frac{1}{ln^2 T^{-1}(m)}))$
并且任何计数大于或等于 $i$ 的概率为:
$Pr(max(c) \geq i) \leq m({^{nk}_i}){ \displaystyle \frac{1}{m^i}} \leq m({\displaystyle \frac{enk}{im}})^i$
如前所述,$k$(超过实数)的最优值为 $ln(2m/n)$,因此假设哈希函数的数量小于 $ln(2m/n)$ ,我们可以进一步限制:
$Pr(max(c) \geq i) \leq m({\displaystyle \frac{eln2}{i}})^i$
因此,取 $i = 16$,我们得到:
$Pr(max(c) \geq 16) \leq 1.37 * 10^{-15} * m$
换句话说,如果我们允许使用4个比特位用于计数,则在表的初始插入过程中,实际 $m$ 值的溢出概率很小。
在实践中,我们必须考虑到哈希函数并不是真正随机的,并且我们一直在进行插入和删除操作。 不过,似乎每个计数占用4个比特位就足够了。 此外,如果计数超过 15,我们可以简单地将其保持在15;否则,它将保持不变。 在多次删除之后,这可能会导致布隆过滤器允许出现假负数(当计数不应为0时该计数变为0)的情况,但是发生此类事件的可能性非常低,以至于同时将重新启动代理服务器,并重建整个结构。
布隆过滤器作为摘要
布隆过滤器提供了一种创建摘要信息的简单机制。代理从缓存文档的URL列表构建Bloom过滤器,然后将位数组以及哈希函数的规范发送给其他代理。 更新摘要信息时,代理可以指定翻转位数组中的哪些位,或发送整个数组,以较小者为准。
每个代理都维护着布隆过滤器的本地副本,并在将文档添加到缓存或从缓存中替换文档时对其进行更新。正如以上所说明的,为了更新本地的布隆过滤器,代理服务器需要维护一个计数器数组,每个计数器记住相应位设置为1的次数。并将文档添加到高速缓存中时,增加相应位的计数器; 当从缓存中删除它时,减少相应位的计数器。 当计数器从0增加到1或从1下降到0时,相应的位应该分别被设置为1或0,并在列表中添加一条记录更新的记录。
布隆过滤器的优点是,它们可以在内存需求和误报率(会导致误判命中)之间进行权衡。 因此,代理可以在代理间的通信量略有增加的情况下,为摘要信息分配较少的内存。
我们针对基于布隆过滤器的摘要信息尝试了三种配置:位数组的大小为缓存中平均文档数的8倍,16倍和32倍(该比率也称为 “加载因子”)。 通过将高速缓存大小除以8K(平均文档大小)来计算平均文档数。 所有这三种配置都使用四个哈希函数。 哈希函数的数量并不是每种配置的最佳选择,但足以证明布隆过滤器的性能。 首先通过计算URL的MD5签名[38](产生128位),然后将128位划分为4个32位字,最后将每个32位字的模数与表大小 $m$ 进行比较。MD5是一种加密消息摘要算法,可将任意长度的字符串散列为128位[38]。我们选择它是因为其众所周知的属性和相对较快的实现。
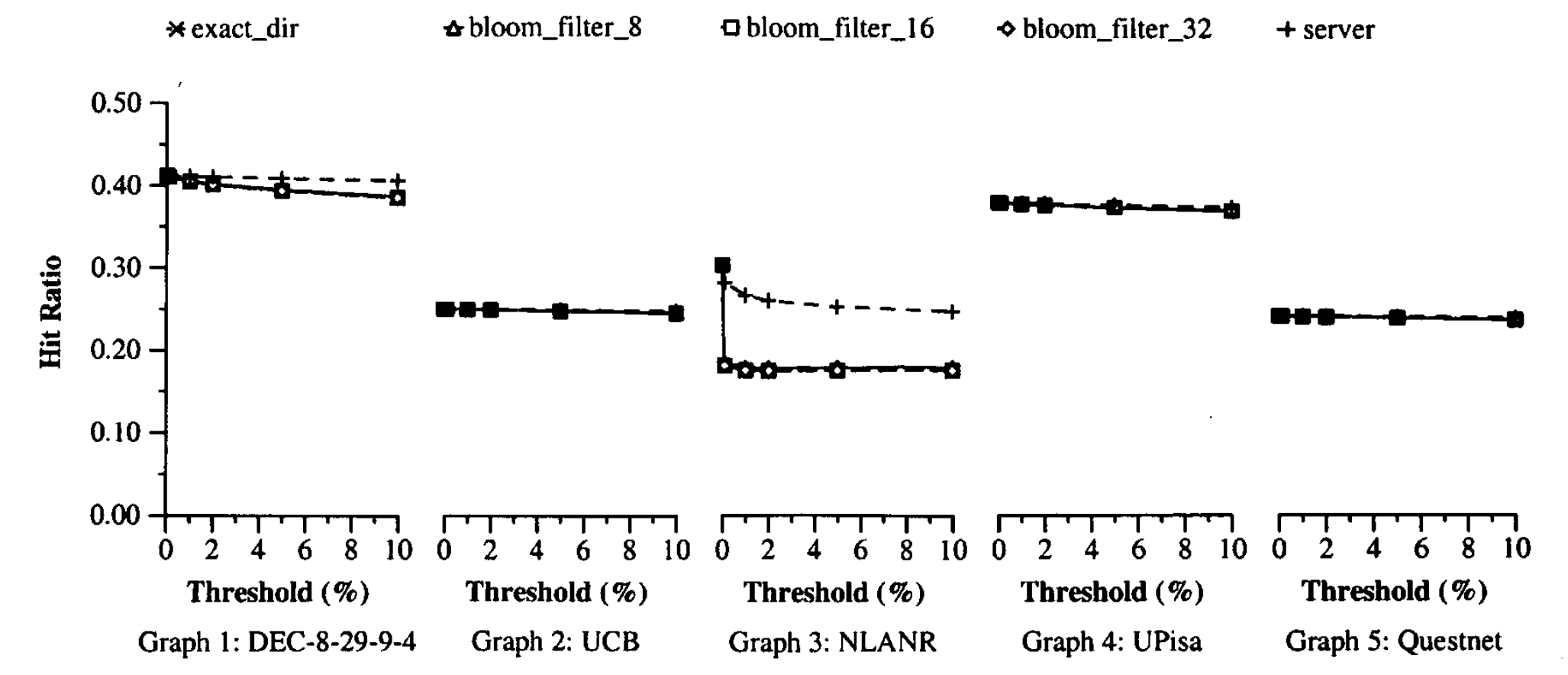
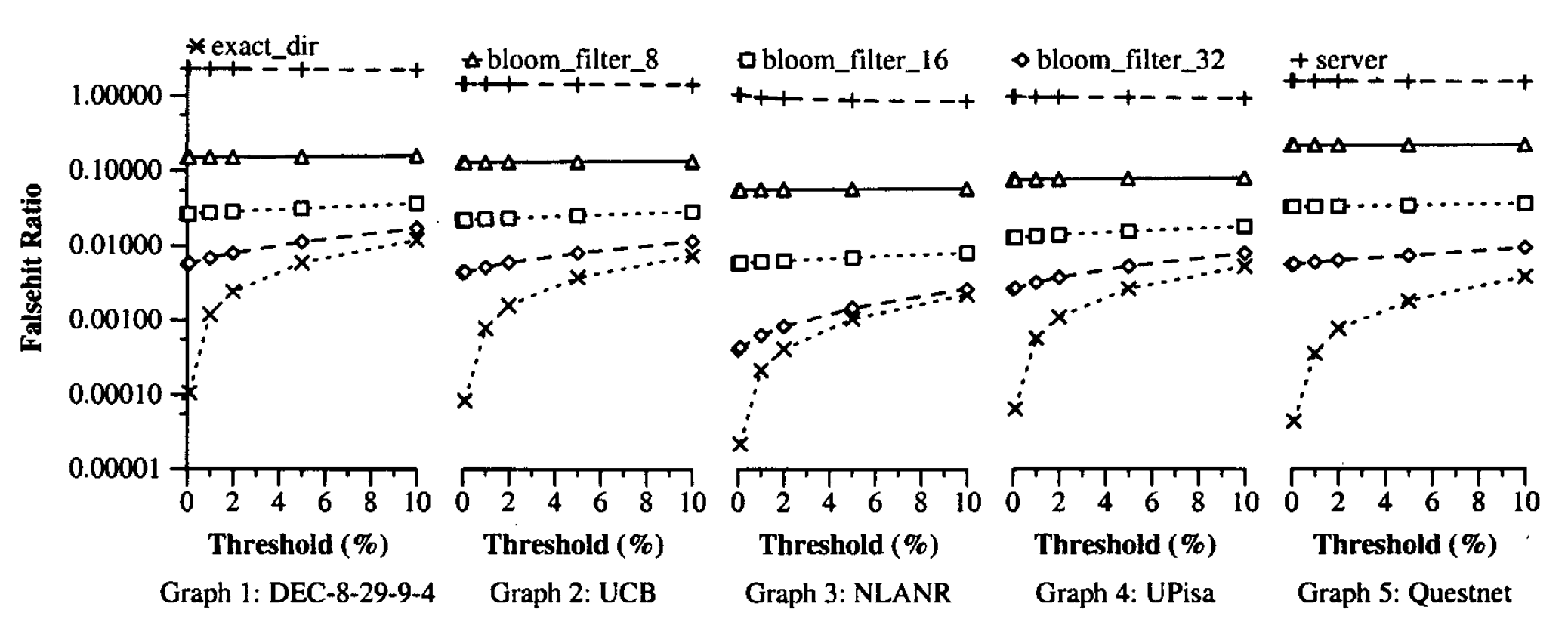
这些摘要信息表示,精确目录方法和服务器名称方法的性能如图5到图9所示。在图5中,我们显示了总的高速缓存命中率,在图6中,我们显示了错误命中率。 请注意,图6中的y轴为对数刻度。 基于布隆过滤器的摘要实际上具有与精确目录方法相同的缓存命中率,并且在位数组较小时具有较高的假命中率。 服务器名称具有较高的错误命中率。 它具有较高的缓存命中率,可能是因为它的许多错误命中有助于避免错误遗漏。
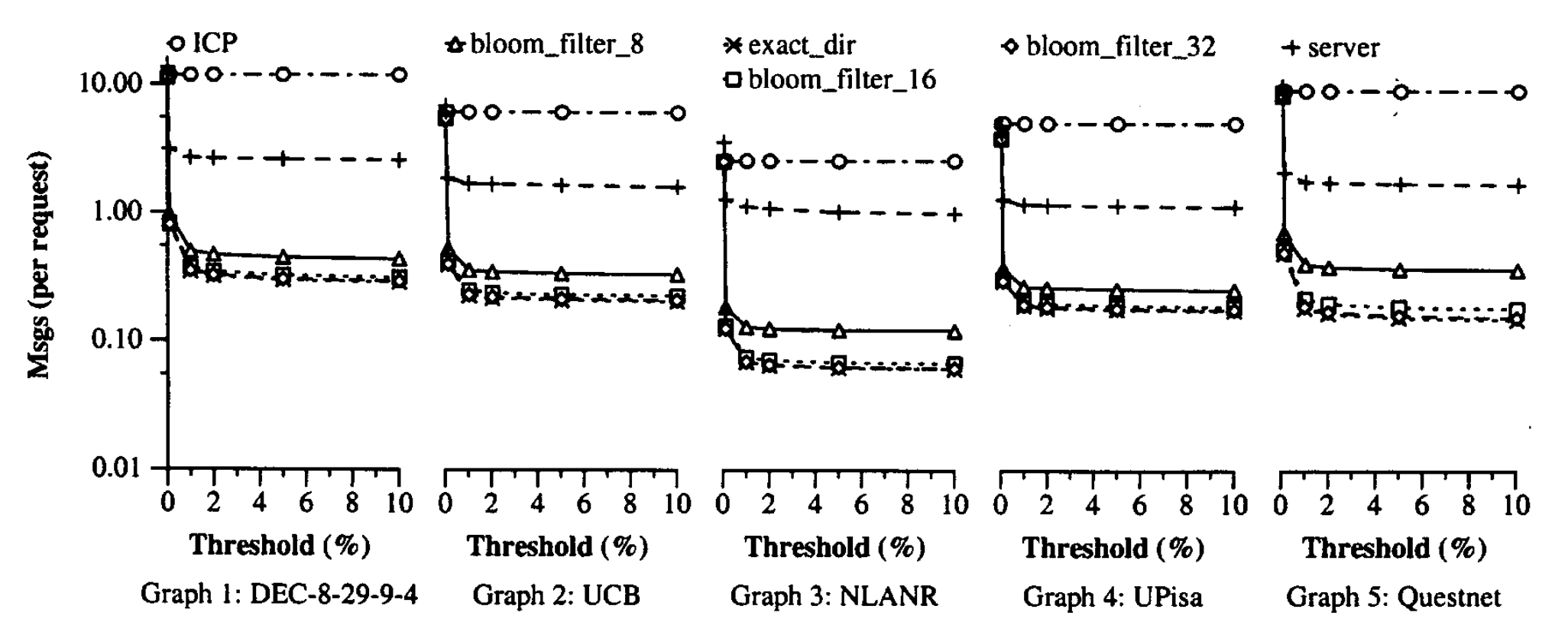
图7显示了代理间网络消息的总数,包括摘要更新的数量和查询消息的数量(包括远程高速缓存命中,错误命中和远程陈旧命中)。注意,图7中的y轴为对数刻度。为了进行比较,我们还列出了每个跟踪中ICP引起的消息数。假定所有消息都是单播消息。该图通过每个跟踪中的HTTP请求数将消息数标准化。基于精确目录和布隆过滤器的摘要都可以很好地执行,并且服务器名和ICP会生成更多消息。对于布隆过滤器,如预期的那样,需要在位阵列大小和消息数之间进行权衡。但是,一旦错误命中率足够小,错误命中就不再是代理间消息的主要来源。而是,远程缓存命中和远程陈旧命中成为主导。因此,在负载因数16和负载因数32之间在网络消息方面的差异很小。与ICP相比,基于布隆过滤器的摘要将消息数量减少了25到60。
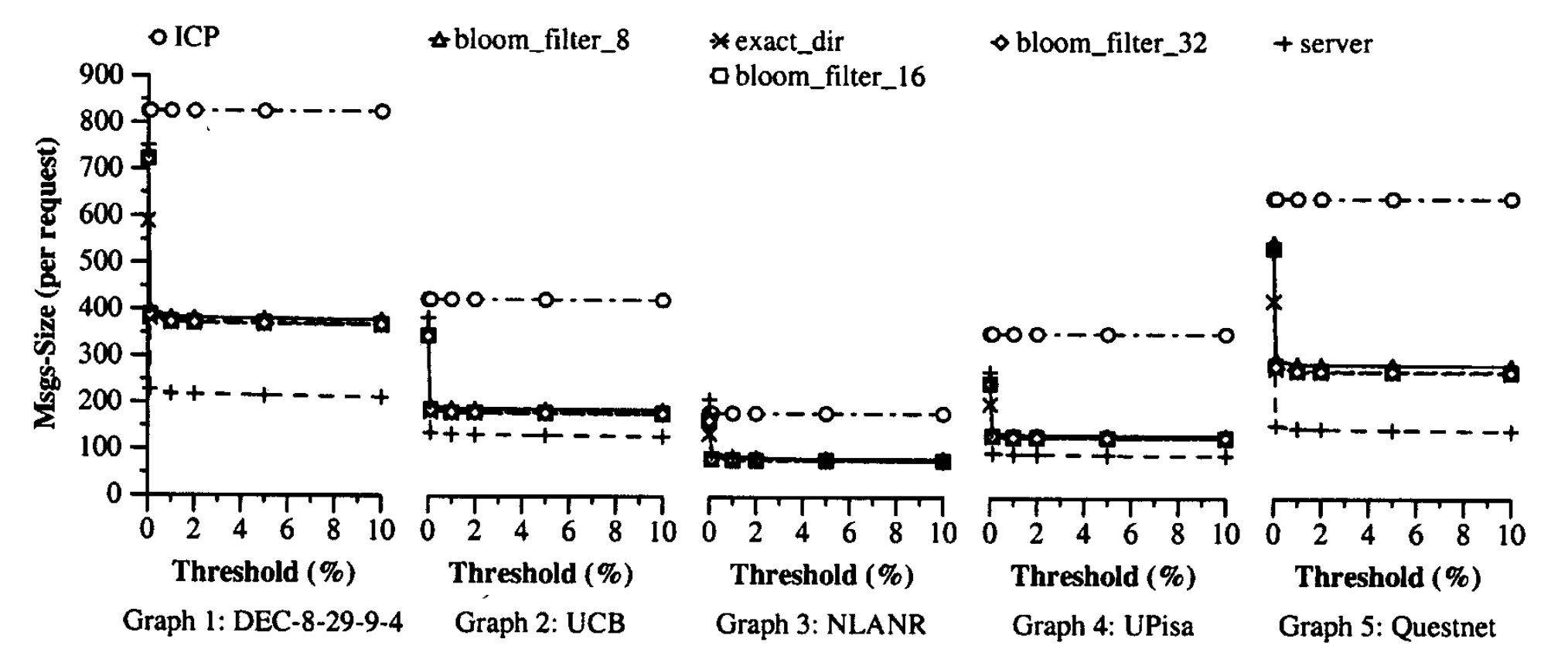
图8显示了代理间网络消息的估计总大小(以字节为单位)。我们估计大小是因为更新消息往往大于查询消息。ICP和其他方法中查询消息的平均大小均假定为标头20字节和平均URL为50字节。 精确目录和服务器名称中摘要更新的大小假定为标头20字节,每次更改16字节。 在基于布隆过滤器的摘要中,摘要更新的大小估计为32字节的标头(请参见第6节)加上每个位翻转4字节。 结果表明,就消息字节而言,基于布隆过滤器的摘要比ICP改善了55%至64%。 换句话说,摘要缓存偶尔使用大消息突发,以避免连续发送小消息。 查看表2、6和7中的CPU开销和网络接口数据包(其中SC-ICP代表摘要缓存方法),我们可以看到这是一个很好的权衡。
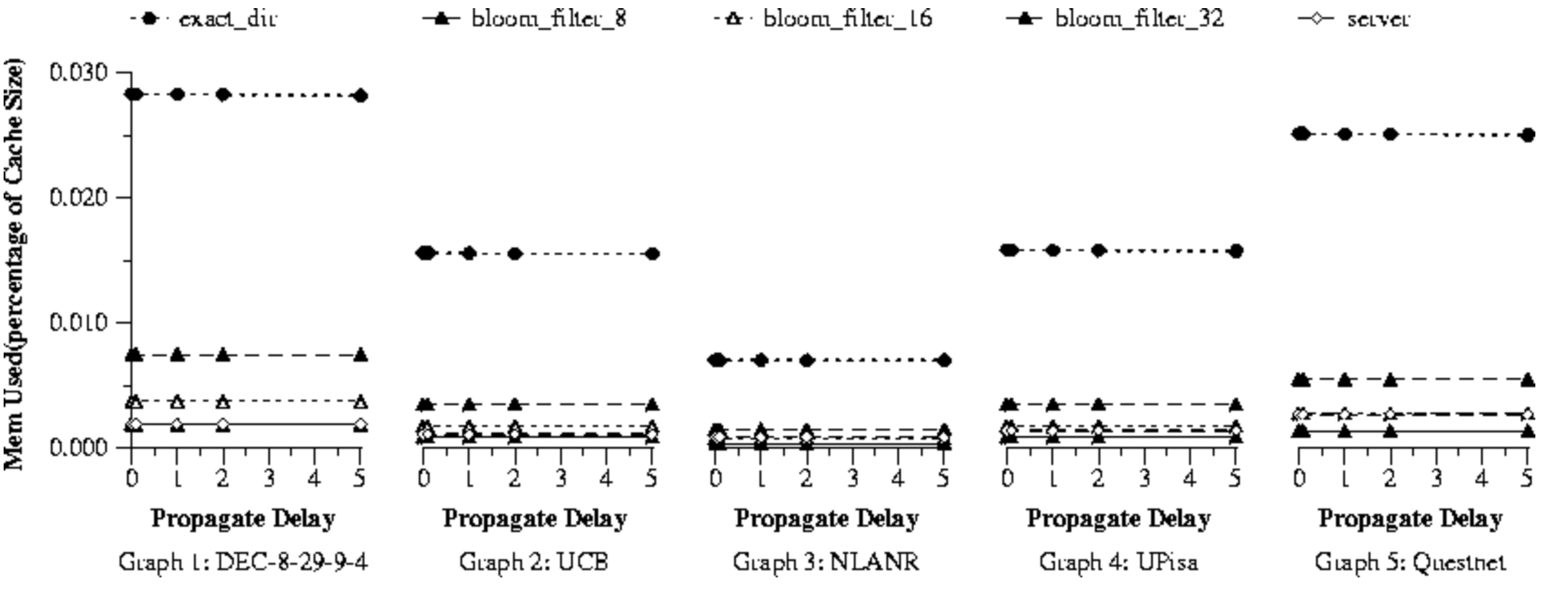
最后,图9显示了摘要缓存方法的每个代理的内存,以缓存大小的百分比表示。 三种布隆过滤器配置所消耗的内存比精确目录少得多,但在所有其他方面的性能却与精确目录类似。 负载因数为8时,布隆过滤器摘要与服务器名称方法具有相似或更少的内存要求,并且错误命中率和网络消息更少。 由于DEC,UCB,UPisa,NLANR和Questnet迹线分别具有16、8、8、4和12个代理,因此该图表明内存需求随代理的数量线性增长。
考虑所有结果,我们看到布隆过滤器的摘要在低网络开销和低内存需求方面提供了最佳性能。 这种方法简单易行。 除MD5之外,其他更快的哈希方法也可用,例如哈希函数可以基于Rabin指纹方法(参见[42],[7])中的多项式算法或简单的哈希函数(例如[22],p. [48])可用于生成例如32位,并且可以通过对这32位(视为整数)进行随机线性变换来获得其他位。 缺点是这些较快的功能是有效可逆的(也就是说,可以轻松地构建散列到特定位置的URL),这一事实可能被恶意用户用于邪恶目的。
推荐配置
结合以上结果,我们建议对摘要缓存方法进行以下配置。更新阈值应在1%到10%之间,以避免显着降低总缓存命中率。如果选择了基于时间的更新方法,则应选择时间间隔,以使新文档的百分比在1%到10%之间。代理可以广播更改(如果较小,则广播整个位数组),或者让其他代理从中获取更新。摘要应采用布隆过滤器的形式。8到16之间的负载系数可以很好地工作,但是代理可以根据其内存和网络流量问题降低或提高它。基于负载因子,应使用四个或更多哈希函数。此处和[16]中提供的数据可以用作决策参考。对于散列函数,我们建议从URL的128位MD5签名中获取不相交的位组。如果需要更多位,则可以计算与其自身连接的URL的MD5签名。实际上,与缓存文档所引起的用户和系统CPU开销相比,MD5的计算开销可以忽略不计(请参阅第[7]节)。
可扩展性
尽管我们的模拟是针对4到16个代理完成的,但是我们可以轻松地推断出结果。例如,假设每个代理有8GB的缓存要合作。每个代理平均存储约100万个网页。表示1M页面所需的布隆过滤器内存在负载因子16时为2MB。每个代理大约需要200MB来表示所有摘要,另外需要1MB来表示自己的计数器。代理间消息包括更新消息,错误命中,远程缓存命中和远程陈旧命中。 1%的阈值对应于更新之间的10K请求,每个更新包含99条消息,每个请求的更新消息数小于0.01。带有10个哈希函数的16的负载因子的假命中率约为4.7%(每个摘要的误报率小于0.00047,但其中有100个摘要)。因此,不计算远程缓存命中和远程陈旧命中(在代理数量上相对稳定)引入的消息,协议引入的开销是每个请求100个代理的0.06条消息以下。在这些消息中,只有更新消息很大,大约数百KB。幸运的是,更新消息可以通过不可靠的多播方案进行传输。我们的仿真预测,在保持较低开销的同时,与ICP的理论命中率相比,该方案将总命中率降低了不到2%。
尽管没有迹线足够大以至于无法对100个代理进行有意义的仿真,但我们已经使用大量代理进行了仿真,结果验证了这些``封底’’的计算结果。 因此,我们相信摘要缓存可以很好地扩展。
摘要缓存增强型ICP的实现
基于仿真结果,我们提出以下摘要缓存增强的Internet缓存协议作为ICP的优化。 该协议已在Squid 1.1.14之上的原型中实现,并且该原型可公开获得[15]。 在Squid 1.2b20中也实现了我们的方法的一种称为Cache Digest的变体[44]。
协议书
我们协议的设计面向较小的延迟阈值。 因此,它假定摘要是通过发送差异来更新的。 如果延迟阈值很大,则发送整个位阵列会更经济; Squid 1.2b20 [44]中的Cache Digest原型采用了这种方法。
我们在ICP版本2[48]中添加了新的操作码,ICP_OP_DIRUPDATE(= 20),代表目录更新消息。 在更新消息中,常规ICP头后面有一个附加头,该头包括:16位的Function_Num,16位的Function_Bits,32位的BitArray_Size_InBits和32位的Number_of_Updates。 标头完全指定用于探测过滤器的哈希函数。 有散列函数的Function_Num。 通过首先从URL的MD5签名[38,22]中取出位0到M-1,M到2M-1、2M到3M-1等来计算函数,其中M是Function_Bits,然后进行模块化 位由BitArray_Size_InBits决定。 如果128位不够用,则通过计算与其自身连接的URL的MD5签名来生成更多位。
标头后跟一个32位整数列表。 整数中的最高有效位指定该位应设置为0还是1,其余位指定需要更改的位的索引。 该设计是出于以下考虑:如果消息仅指定应翻转的位,则丢失先前的更新消息将具有级联效应。 该设计使消息可以通过不可靠的多播协议发送。 此外,每个更新消息都带有标头,该标头指定哈希函数,以便接收者可以验证信息。 该设计将哈希表的大小限制为小于20亿,这暂时足够大。
原型实现
我们修改了Squid 1.1.4软件以实现上述协议。 一个额外的位数组被添加到每个邻居的数据结构中。 当从邻居接收到第一摘要更新消息时,初始化该结构。 代理还分配了一个字节计数器数组来维护Bloom过滤器的本地副本,并分配一个整数数组来记住过滤器的更改。
由于ICP是基于UDP构建的,因此当前的原型通过UDP发送更新消息。 该设计的一种变体是通过TCP或多播发送消息。 由于这些消息的大小,最好通过TCP或多播发送它们。 此外,由于协作代理的收集是相对静态的,因此代理可以仅保持彼此之间的永久TCP连接以交换更新消息。 不幸的是,在Squid中实现ICP仅在UDP之上。 因此,原型有悖于5.5节中的建议,并且只要有足够的更改来填充IP数据包,就发送更新。 该实现还利用Squid的内置支持来检测邻居代理的故障和恢复,并在故障邻居恢复时重新初始化它。
实验
表6:实验2中UPisa迹线的ICP和摘要缓存的性能。括号中的数字表示三个实验之间测量值的差异。
| Exp | Hit Ratio | Client Latency | User CPU | System CPU | UDP Traffic | TCP Traffic | Total Packets |
|---|---|---|---|---|---|---|---|
| no ICP | 16.94 | 6.22(0.4%) | 81.72(0.1%) | 115.63(0.1%) | 4718(1%) | 242K(0.1%) | 259K(0.1%) |
| ICP | 19.3 | 6.31(0.5%) | 116.81(0.1%) | 137.12(0.1%) | 72761(0%) | 245K(0.1%) | 325K(0.2%) |
| Overhead | 1.42% | 43% | 19% | 1400% | 1% | 25% | |
| SC-ICP | 19.0 | 6.07 (0.1%) | 91.53(0.4%) | 121.75(0.5%) | 5765(2%) | 244K(0.1%) | 262K(0.1%) |
| Overhead | -2.4% | 12% | 5% | 22% | 1% | 1% |
表7:实验3中UPisa跟踪的ICP和摘要缓存的性能
| Exp | Hit Ratio | Client Latency | User CPU | System CPU | UDP Traffic | TCP Traffic | Total Packets |
|---|---|---|---|---|---|---|---|
| no ICP | 9.94 | 7.11 | 81.75 | 119.7 | 1608 | 248K | 265K |
| ICP | 17.9 | 7.22 | 121.5 | 146.4 | 75226 | 257K | 343K |
| Overhead | 1.6% | 49% | 22% | 4577% | 3.7% | 29% | |
| SC-ICP | 16.2 | 6.80 | 90.4 | 126.5 | 4144 | 254K | 274K |
| Overhead | -4.3% | 11% | 5.7% | 1.6 | 2.4% | 3.2% |
我们对该原型进行了三个实验。 第一个实验重复第4节中的测试,结果包含在第4节表2中,标题为SC-ICP。改进的协议将UDP流量减少了50倍,并且具有网络流量, CPU时间和客户端等待时间与No-ICP相似。
我们的第二个实验和第三个实验重播了UPisa跟踪中的前24,000个请求。我们使用在4个工作站上运行的80个客户端进程的集合,并将同一工作站上的客户端进程连接到同一代理服务器。在第二个实验中,我们通过让每个客户端进程通过发出它们的Web请求来模拟一组真实的客户端来重播跟踪。在第三个实验中,我们通过让客户端进程从跟踪文件循环发出请求来重播跟踪,而不管每个请求来自哪个实际客户端。第二个实验保留了客户端及其请求之间的边界,并且客户端的请求都转到同一个代理。但是,它不会保留来自不同客户端的请求之间的顺序。第三个实验不保留请求和客户端之间的边界,但是保留请求之间的时序顺序。与第二个实验相比,第三个实验中的代理负载均衡性更高。
在这两个实验中,每个请求的URL都在跟踪文件中包含请求的大小,并且服务器以指定的字节数进行答复。 其余配置与第4节中的实验相似。与综合基准不同,该跟踪包含大量的远程命中。 实验2的结果列在表6中,实验3的结果列在表7中。
结果表明,增强的ICP协议可显着减少网络流量和CPU开销,而仅略微降低总命中率。 与No-ICP相比,增强的ICP协议可以稍微降低客户端等待时间,即使它将CPU时间增加了大约12%。 客户端延迟的减少归因于远程缓存命中。 单独的实验表明,大多数CPU时间增加是由于服务于远程命中,而MD5计算导致的CPU时间增加不到5%。 尽管实验没有如实地重播跟踪,但它们确实说明了摘要缓存在实践中的性能。
我们的结果表明,摘要缓存增强的ICP解决了ICP的开销问题,需要最小的更改,并且可以在广域网上共享可伸缩的Web缓存。
相关工作
Web缓存是一个活跃的研究领域。 关于Web客户端访问特性[10,3,14,33,23],Web缓存算法[49,35,8]以及Web缓存一致性[28,31,34,13]已有许多研究。 我们的研究不涉及缓存算法或缓存一致性维护,但是在我们对Web缓存共享的好处进行调查的过程中,与某些客户端流量研究重叠。
最近,文献中提出了许多新的缓存共享方法。缓存阵列路由协议[46]在一组松散耦合的代理服务器之间划分URL空间,并让每个代理仅缓存URL哈希到其上的文档。该方法的优点在于,它消除了文档的重复副本。但是,尚不清楚该方法在代理分布在区域网络中的广域缓存共享方面的性能如何。 Relais项目[27]还建议使用本地目录在其他缓存中查找文档,并异步更新目录。这个想法类似于摘要缓存。但是,该项目似乎并未解决内存需求问题。从Relais的出版物中我们可以找到并阅读[4],我们也不清楚该项目是否解决了目录更新频率的问题。由紧密耦合的群集工作站构建的代理也使用各种哈希和分区方法来利用群集中的内存和磁盘[20],但是这些方法不适用于广域网。
我们的研究部分受到名为目录服务器[21]的现有提议的推动。 该方法使用中央服务器来跟踪所有代理的缓存目录,并且所有代理向服务器查询其他代理中的缓存命中。 该方法的缺点是中央服务器很容易成为瓶颈。 优点是,除了远程命中之外,同级代理之间几乎不需要通信。
关于Web缓存层次结构和缓存共享的研究也很多。 分层Web缓存最早是在Harvest项目[26,12]中提出的,该项目还引入了ICP协议。 当前,Squid代理服务器实现了ICP协议的第2版[48],我们的摘要缓存增强型ICP以此版本为基础。 自适应Web缓存[50]提出了一种基于多播的自适应缓存基础结构,用于在Web中分发文档。 特别地,该方案试图沿着到服务器的路线将文档放置在正确的缓存中。 我们的研究未解决定位问题。 相反,我们注意到我们的研究是互补的,因为摘要缓存方法可以用作传达缓存内容的机制。
尽管我们没有模拟这种情况,但是可以在父代理和子代理之间使用摘要缓存增强的ICP。 分层Web缓存不仅包括相邻(同级)代理之间的协作,还包括父代和子代代理之间的协作。 同级代理与父级代理之间的区别在于,代理不能要求同级代理从服务器获取文档,而可以要求父级代理这样做。 尽管我们的模拟仅涉及同级代理之间的协作,但是摘要缓存方法可用于将有关父缓存内容的信息传播到子代理,并消除子代理对父代的ICP查询。 我们对Questnet跟踪的检查表明,子级到父级ICP查询可能是父级必须处理的消息的很大一部分(超过2/3)。
在操作系统的上下文中,已经有很多关于协作文件缓存[11,2]和全局存储系统(GMS)[17]的研究。这些系统中的基本假设是高速局域网比磁盘快,并且工作站应使用彼此的空闲内存来缓存文件页面或虚拟内存页面,以避免流向磁盘。在这方面,问题与Web缓存共享完全不同。另一方面,在这两种情况下,都存在缓存应紧密协作的问题。大多数协作文件缓存和GMS系统都试图模拟全局LRU替换算法,有时还会使用提示[45]。有趣的是,对于是否需要全局替换算法,我们得出了截然不同的结论[17]。原因是在OS上下文中,全局替换算法用于从空闲工作站窃取内存(即负载均衡缓存),而在Web缓存共享中,每个代理一直都在忙。因此,尽管简单的缓存共享在OS上下文中的性能较差,但只要每个代理的资源配置都适合其负载,就足以满足Web代理缓存共享的需要。最后,请注意,基于Bloom筛选器的摘要缓存技术不限于Web代理缓存上下文,而是可以在其他缓存内容的知识有帮助的情况下使用,例如,在集群中的缓存和负载平衡方面。服务器。
结论与未来工作
我们提出了摘要缓存增强的ICP,这是一种可扩展的广域Web缓存共享协议。 使用跟踪驱动的模拟和测量,我们演示了Web代理缓存共享的好处,说明了当前缓存共享协议的开销,并表明摘要缓存方法大大降低了开销。 我们研究了这种方法的两个关键方面:延迟更新的影响以及摘要的简洁表示。 我们的解决方案是基于具有更新延迟阈值的Bloom过滤器的摘要,对内存和带宽的需求较低,但实现了与原始ICP协议相似的命中率。 尤其是,跟踪驱动的仿真表明,与ICP相比,新协议将代理间协议消息的数量减少了25到60,将带宽消耗减少了50%以上,同时几乎不降低代理质量。 缓存命中率。 仿真和分析进一步证明了该协议的可扩展性。
我们已经在Squid 1.1.14中构建了一个原型实现。 合成和跟踪重播实验表明,除了减少网络流量外,新协议还将CPU开销减少了75%至95%之间,并改善了客户端延迟。 原型实现是公开可用的[15]。
未来的工作还有很多。 我们计划调查该协议对父子代理合作以及给定工作负载的最佳层次结构配置的影响。 我们还计划研究摘要缓存在各种Web缓存一致性协议中的应用。 最后,摘要缓存可用于单个代理实现中以加快缓存查找的速度,我们将通过修改代理实现来量化效果。
参考文献
[1] J. Almeida and P. Cao. (1997) Wisconsin proxy benchmark 1.0. [Online]. Available: http://www.cs.wisc.edu/~cao/wpbl.0.html
[2] T.E. Anderson, M. D. Dahlin, J. M. Neefe, D. A. Patterson, D. S. Roselli,and R. Y. Wang,”Serverless network file systems,” in Proc. 15th ACM Syrup. Operating Syst. Principles,Dec. 1995.
[3] M. Arlitt, R. Friedrich, and T. Jin, “Performance evaluation of Web proxy cache replacement policies,” in Proc. Performance Tools’98, Lecture Notes in Computer Science, 1998, vol. 1469, pp. 193-206.
[4] M. Arlitt and C. Williamson, “Web server workload characterization,” in Proc. 1996 ACM SIGMETRICS Int. Conf. Measurement and Modeling of Computer Systems, May 1996.
[5] A. Baggio and G. Pierre. Oleron: Supporting information sharing in large-scale mobile environments, presented at ERSADS Workshop, Mar.[Online]. Available: http://www-sor.inria.fr/projects/relais/
[6] K. Beck. Tennessee cache box project, presented at 2nd Web Caching Workshop, Boulder, CO, June 1997. [Online]. Available: http://ircache.nlanr.net/Cache/Workshop97/
[7] B. Bloom, “Space/time trade-offs in hash coding with allowable errors,” Commun. ACM, vol. 13, no. 7, pp. 422-426, July 1970.
[8] L. Breslau, P. Cao, L. Fan, G. Phillips, and S. Shenker, “Web caching and zipf-like distributions: Evidence and implications,” in Proc. IEEE INFOCOM, 1999.
[9] A. Z. Broder, “Some applications of Rabin’s fingerprinting method,” in Sequences 11: Methods in Communications, Security, and Computer Science, R. Capocelli, A. De Santis, and U. Vaccaro, Eds. New York, NY: Springer-Verlag, 1993, pp. 143-152.
[10] P. Can and S. Irani, “Cost-aware WWW proxy caching algorithms,” in Proc. 1997 USEN1X Symp. lnternet Technology and Systems, Dec. 1997, http://www.cs.wisc.edu/~cao/papers/gd-size.html, pp. 193-206.
[11] M. Crovella and A. Bestavros, “Self-similiarity in world wide web traffic: Evidence and possible causes,” in Proc. 1996 Sigmetrics Conf. Measurement and Modeling of Computer Systems, Philadelphia, PA, May 1996.
[12] C. R. Cunha, A. Bestavros, and M. E. Crovella, “Characteristics of WWW client-based traces,” Boston University, Boston, MA, Tech. Rep. BU-CS-96-010, Oct. 1995.
[13] M. D. Dahlin, R. Y. Wang, T. E. Anderson, and D. A. Patterson, “Cooperative caching: Using remote client memory to improve file system performance,” in Proc. 1st USENIX Symp. Operating Systems Design and Implementation, Nov. 1994, pp. 267-280.
[14] P. B. Danzig, R. S. Hall, and M. E Schwartz, “A case for caching file objects inside internetworks,” in Proc. S1GCOMM, 1993, pp. 239-248.
[15] E Douglis, A. Feldmann, B. Krishnamurthy, and J. Mogul, “Rate of change and other metrics: A live study of the world wide web,” in Proc. USENIX Symp. lnternet Technology and Systems, Dec. 1997.
[16] B.M. Duska, D. Marwood, and M. J. Feeley, “The measured access characteristics of world-wide-web client proxy caches,” in Proc. USENIX Symp. lnternet Technology and Systems, Dec. 1997.
[17] L. Fan, P. Cao, and J. Almeida. (1998, Feb.) A prototype implementation of summary-cache enhanced icp in Squid 1.1.14. [Online]. Available: http://www.cs.wisc.edu/~cao/sc-icp.html
[18] L. Fan, P. Cao, J. Almeida, and A. Z. Broder, “Summary cache: A scalable wide-area web cache sharing protocol,” in Proc. ACM SIGCOMM,
[19] –, (1998, Feb.) Summary cache: A scalable wide-area web cache sharing protocol. Tech. Rep. 1361, Computer Science Department, University of Wisconsin-Madison. [Online]. Available: http://www.cs.wisc.edu/-cao/papers/summarycache.html
[20] M.J. Feeley, W. E. Morgan, E H. Pighin, A. R. Karlin, H. M. Levy, and C. A. Thekkath, “Implementing global memory management in a workstation cluster,” in Proc. 15th ACM Symp. Operating Systems Principles, Dec. 1995.
[21] ICP working group. (1998). National Lab for Applied Network Research. [Online]. Available: http://ircache.nlanr.netICache/ICP/
[22] A. Fox, S. D. Gribhle, Y. Chawathe, E. A. Brewer, and P. Gauthier
[23] S. Gadde, M. Rabinovich, and J. Chase. Reduce, reuse, recycle: An approach to building large internet caches, presented at 6th Workshop Hot Topics in Operating Systems (HotOS VI), May 1997. [Online]. Available: http://www.research.att.com/-misha/
[24] G. Gonnet and R. Baeza-Yates, Handbook of Algorithms and Data Structures. Reading, MA: Addison-Wesley, 1991.
[25] S. Gribble and E. Brewer, “System design issues for intemet middleware service: Deduction from a large client trace,” in Proc. USENIX Symp.Internet Technology and Systems, Dec. 1997.
[26] –, (1997, June) UCB home IP HTTP traces. [Online]. Available:http://www.cs.berkeley.edu/~gribble/traces/index.html
[27] C. Grimm. The dfn cache service in B-WiN. presented at 2nd Web Caching Workshop, Boulder, CO, June 1997. [Online]. Available: http://www-cache.dfn.de/CacheEN/
[28] The Harvest Group. (1994) Harvest Information Discovery and Access System. [Online]. Available: http://excalibur.usc.edu/
[29] The Relais Group. (1998) Relais: Cooperative caches for the world-wide web. [Online]. Available: http://www-sor.inria.fr/projects/relais/
[30] J. Gwertzman and M. Seltzer, “World-wide web cache consistency,” in Proc. 1996 USENIX Tech. Conf., San Diego, CA, Jan. 1996.
[31] IRCACHE. (1999, Mar.) Benchmarking Proxy Caches with Web Polygraph. [Online].Available: http://www.polygraph.ircache.net/slides/
[32] V. Jacobson. How to kill the internet, presented at SIGCOMM’95 Middleware Workshop, Aug. 1995. [Online]. Available: ftp://ftp.ee.lhl .gov/talks/vj -webflame.ps.Z
[33] J. Jung. Nation-wide caching project in korea, presented at 2nd Web Caching Workshop, Boulder, CO, June 1997. [Online]. Available: http://ircache.nlanr.net/Cache/Workshop97/
[34] B. Krishnamurthy and C. E. Ellis, “Study of piggyback cache validation for proxy caches in the world wide web,” in Proc. USENIX Symp. lnternet Technology and Systems, Dec. 1997.
[35] T. M. Kroeger, J. Mogul, and C. Maltzahn. (1996, Aug.) Digital’s web proxy traces. [Online]. Available: ftp://ftp.digital.com/pub/DEC/traces/proxy/webtraces.html
[36] T.M. Kroeger, D. D. E. Long, and J. C. Mogul, “Exploring the bounds of web latency reduction from caching and prefetching,” in Proc. USEN1X Syrup. lnternet Technology and Systems, Dec. 1997.
[37] C. Liu and P. Cao, “Maintaining strong cache consistency for the world-wide web,” presented at the 17th Int. Conf. Distributed Computing Systems, May 1997.
[38] P. Lorenzetti, L. Rizzo, and L. Vicisano. (1996, Oct.) Replacement policies for a proxy cache. Universita di Pisa, Italy. [Online]. Available: http://www.iet.unipi.it/~luigi/caching.ps.gz
[39] C. Maltzahn, K. Richardson, and D. Grunwald, “Performance issues of enterprise level web proxies,” in Proc. 1997 ACM SIGMETRICS Int. Conf. Measurement and MOdeling of Computer Systems, June 1997, pp. 13-23.
[40] J. Marais and K. Bharat. Supporting cooperative and personal surfing with a desktop assistant, presented at ACM UIST’97. [Online]. Available: ftp://ftp.digital.com/pub/DEC/SRC/publications/marais/uist97paper.pdf.
[41] A. J. Menezes, P. C. van Oorschot, and S. A. Vanstone, Handbook of Applied Cryptography: CRC Press, 1997.
[42] J. C. Mogul, E Douglis, A. Feldmann, and B. Krishnamurthy. Potential benefits of delta encoding and data compression for http.presented at ACM SIGCOMM’97. [Online]. Available: http://www.research.att.com/~douglis/
[43] National Lab of Applied Network Research. (1997, July) Sanitized Access Log.[Online].Available: ftp://ircache.nlanr.netlTraces/
[44] J. Pietsch. Caching in the Washington State k-20 network, presented at2nd Web Caching Workshop, Boulder, CO, June 1997. [Online]. Available: http:/lircache.nlanr.net/CachelWorkshop97/
[45] M. O. Rabin, “Fingerprinting by random polynomials,” Center for Research in Computing Technology, Harvard Univ., Tech. Rep. TR-15-81,1981.
[46] A. Rousskov. (1998, Apr.) Cache digest. [Online]. Available: http://squid.nlanr.net/Squid/CacheDigest/
[47] P. Sarkar and J. Hartman, “Efficient cooperative caching using hints,”in Proc. USENIX Conf. Operating System Design and Implementations,Oct. 1996.
[48] V. Valloppillil and K. W. Ross. (1997) Cache array routing protocol vl.0. [Online]. Available: http:l/ircache.nlanr.net/CachelICP/draftvinod-carp-v 1-02.tx
[49] D. Wessels and K. Claffy. (1998) Internet cache protocol (ICP) v.2. [Online]. Available: http://ds.internic.net/rfc/rfc2186.txt
[50] S. Williams, M. Abrams, C. R. Stanbridge, G. Abdulla, and E. A. Fox. Removal policies in network caches for world-wide web documents, presented at ACM SIGCOMM’96. [Online]. Available: http://ei.cs.vt.edu/~succeed/96sigcomm/
[51] L. Zhang, S. Floyd, and V. Jacobson. Adaptive web caching, presented at
2nd Web Caching Workshop, Boulder, CO, June 1997. [Online]. Available: http://ircache.nlanr.net/Cache/Workshop97/Papers/Floyd/floyd




