BloomFilter 和 CuckooFilter 对比解析
BloomFilter 和 CuckooFilter 都是一种用于数据存在性判断的数据结构。布隆过滤器早在 1970 年就被提出,它由一个二进制向量数组和一系列随机映射函数组成。它可以用于检索一个元素是否一定不在集合中或者可能存在集合中。布谷鸟过滤器的提出相对较晚,它创新性的提出了可以删除的实现方式,解决了布隆过滤器无法删除数据的痛点。这两者各有优劣,需要结合具体的使用姿势来进行选择。
一、BloomFilter
Bloom Filter(布隆过滤器)是1970年由布隆提出的,它由一个二进制向量数组和一系列随机映射函数组成。它可以用于检索一个元素是否一定不在集合中或者可能存在集合中。
1.1、实现原理
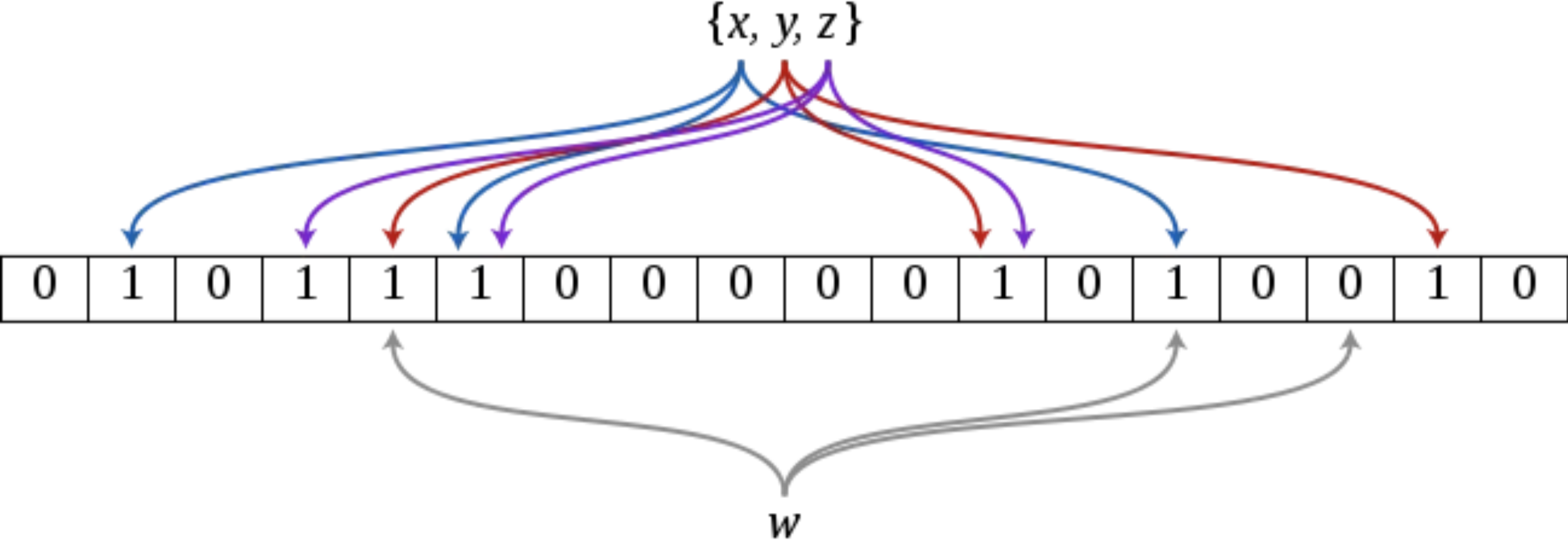
- 初始化内存区域:在内存中开辟一块储存空间,并将里面的比特位全部初始化为
0; - 设置k个hash函数:初始化
k个hash函数,用于元素的数据映射; - 比特位映射:通过
k个hash函数,将元素映射到存储空间对应的比特位,并将对应的比特位设置为1;
1.2、优缺点
- 优点:
- 散列函数相互之间没有关系,方便由硬件并行实现;
- 不需要存储元素本身,在某些对保密要求非常严格的场合有优势;
- 缺点:
- 布隆过滤器存储空间和插入/查询时间都是
O(k),导致查询性能较弱; - 误算率随着存入的元素数量增多而不断增加;
- 由于不能确定某个元素是否一定存在,因此无法删除元素;
- 空间利用效率低;
- 布隆过滤器存储空间和插入/查询时间都是
二、CuckooFilter
Cuckoo Filter(布谷鸟过滤器)使用一维数组存储元素的指纹信息(会存在误判率),同时使用两个 hash 函数获得指纹的位置id,在每个位置可以放置多个座位。这两个 hash 函数选择的比较特殊,因为过滤器中只能存储指纹信息。当这个位置上的指纹被挤兑之后,它需要计算出另一个对偶位置,下面会单独对这两个hash函数进行解析。
2.1、实现原理
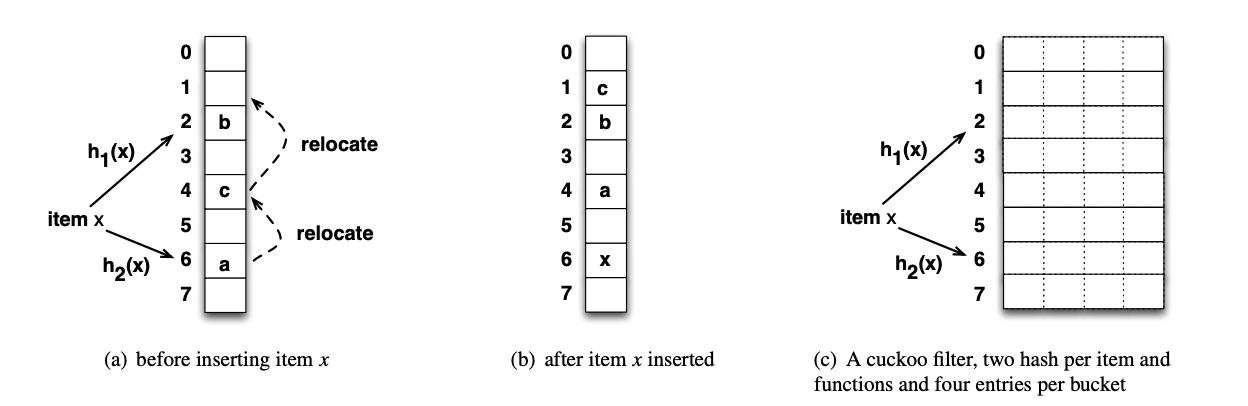
- 初始化内存:初始化一块内存给一维数组
Buckets,其中每个Bucket有n个位置可供使用,每个位置存储对应元素的指纹信息,即每个Bucket中可供存储n个元素的指纹信息; - Bucket映射:通过
两个Hash函数得到两个对应的位置点(p1和p2)信息,尝试将对应元素的指纹信息存入指定的Bucket中,如果p1对应的Bucket已经填充满了,则尝试填充到p2对应的Bucket中; - 元素指纹挤兑:当两个位置点(
p1和p2)对应的Bucket都已经填充满了就会触发填充挤兑,从p1和p2对应的Bucket中随机选择一个进行挤兑操作,将Bucket中的已经存在的指纹信息踢除(被踢除的指纹信息会存储到它可存储的另一个Bucket中,如果另一个Bucket中也没有了位置,则又会触发挤兑操作,直到达到挤兑操作的上限),然后将该指纹信息存储到当前的Bucket中;
2.1.1、一维数组的特性
布谷鸟过滤器强制一维数组的长度必须是 2 的指数,所以对数组的长度取模等价于取 hash 值的最后 n 位。在进行异或运算时,忽略掉低 n 位 之外的其它位就行。将计算出来的位置 p 保留低 n 位就是最终的对偶位置。
2.1.2、两个hash函数的特性
因为布谷鸟过滤器中只存储指纹信息,当这个位置上的指纹被挤兑之后,它需要计算出另一个对偶位置,而计算这个对偶位置是需要元素本身的,但是布谷鸟过滤器巧妙的设计了一个独特的 hash函数,使得可以根据 p1 和 元素指纹 直接计算出 p2,而不需要完整的 x 元素。
|
2.2、优缺点
- 优点:
- 查询性能较高;
- 空间利用率较高;
- 保证了一个比特只被一个元素映射,所以允许删除操作;
- 缺点:
- 不能完美的支持删除,存在误删的情况;
- 存储空间的大小必须为2的指数的限制让空间效率打了折扣;
2.3、场景分析
2.3.1、相同元素多次连续插入
假设每个Bucket的可供存储的座位为4,那么当相同的元素多次连续插入之后,Cuckoo Filter会对同一个元素进行了挤兑循环操作,导致同一个元素的指纹会占用两个位置上的所有的8个座位,导致空间利用率较低。
2.3.2、误删情况
由于存在不同元素被hash到同一个位置的情况,以及不同元素指纹相同的情况,所以会存在一定的误判率。