C语言中有趣的烫烫烫
在学校使用 Windows 下的 Visual Studio 2017 进行课堂C的学习过程中遇到过很多类似于 烫烫烫烫烫烫 , 锟斤拷,屯屯屯 等比较有意思的乱码,也闹出了一些比较有意思的事情。
一、现象
以下是部分乱码在不同的编码类型下的编码值:
| 字符 | 简体中文(GB2312) | Unicode | Unicode (UTF-8) |
|---|---|---|---|
| 烫 | CCCC | EB70 | E783AB |
| 锟 | EFBF | 1F95 | E9949F |
| 斤 | BDEF | A465 | E696A4 |
| 拷 | BFBD | F762 | E68BB7 |
| 屯 | CDCD | 6F5C | E5B1AF |
| 锘 | EFBB | 1895 | E99498 |
| 傻 | C9B5 | BB50 | E582BB |
二、分析
以上比较有意思的乱码情况仅出现在使用Visual Studio或者VC6.0自带的MSVC编译器进行编译时才会出现,也就是说通常只有在Windows环境下使用Visual Studio或者VC6.0进行代码开发,并且处于Debug的运行模式才会出现。
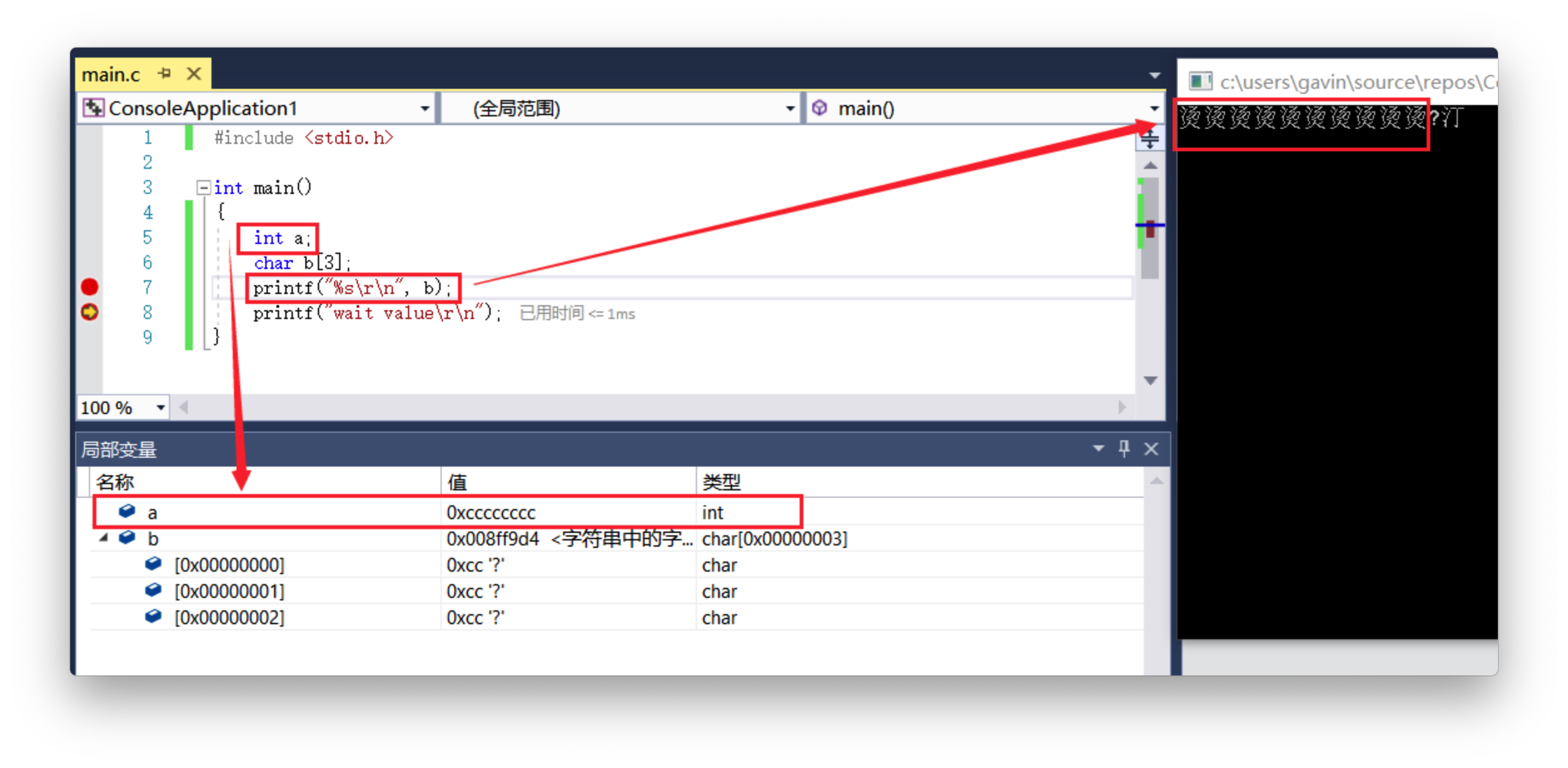
2.1、烫(0xCCCC)
MSVC编译器会将未被初始化的栈内存使用0XCC进行填充,导致我们在使用为初始化的栈内存时便会出现烫烫烫的错误提示;
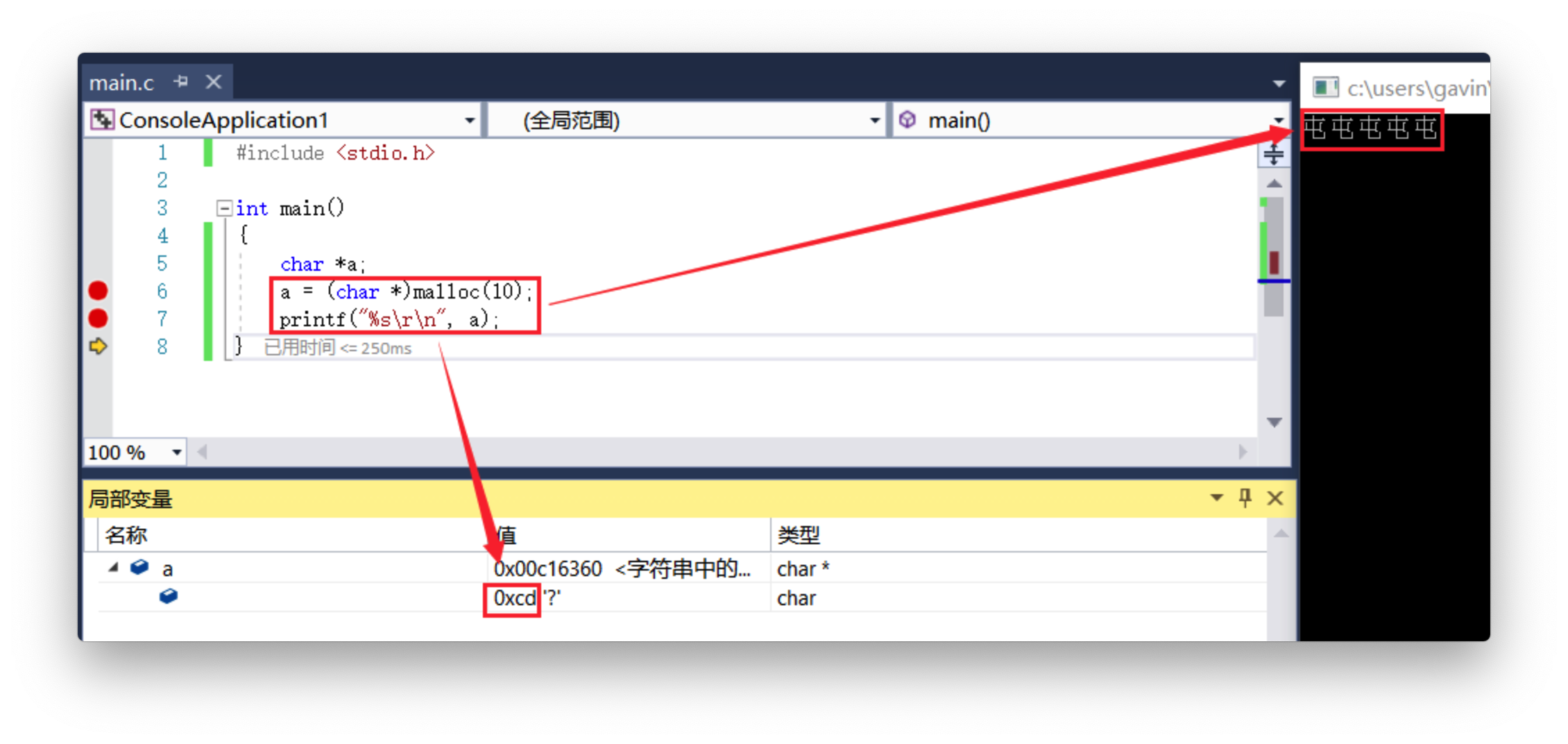
2.2、屯(0xCDCD)
MSVC编译器会将未被初始化的堆内存使用0XCD进行填充,导致我们在使用为初始化的栈内存时便会出现屯屯屯的错误提示;
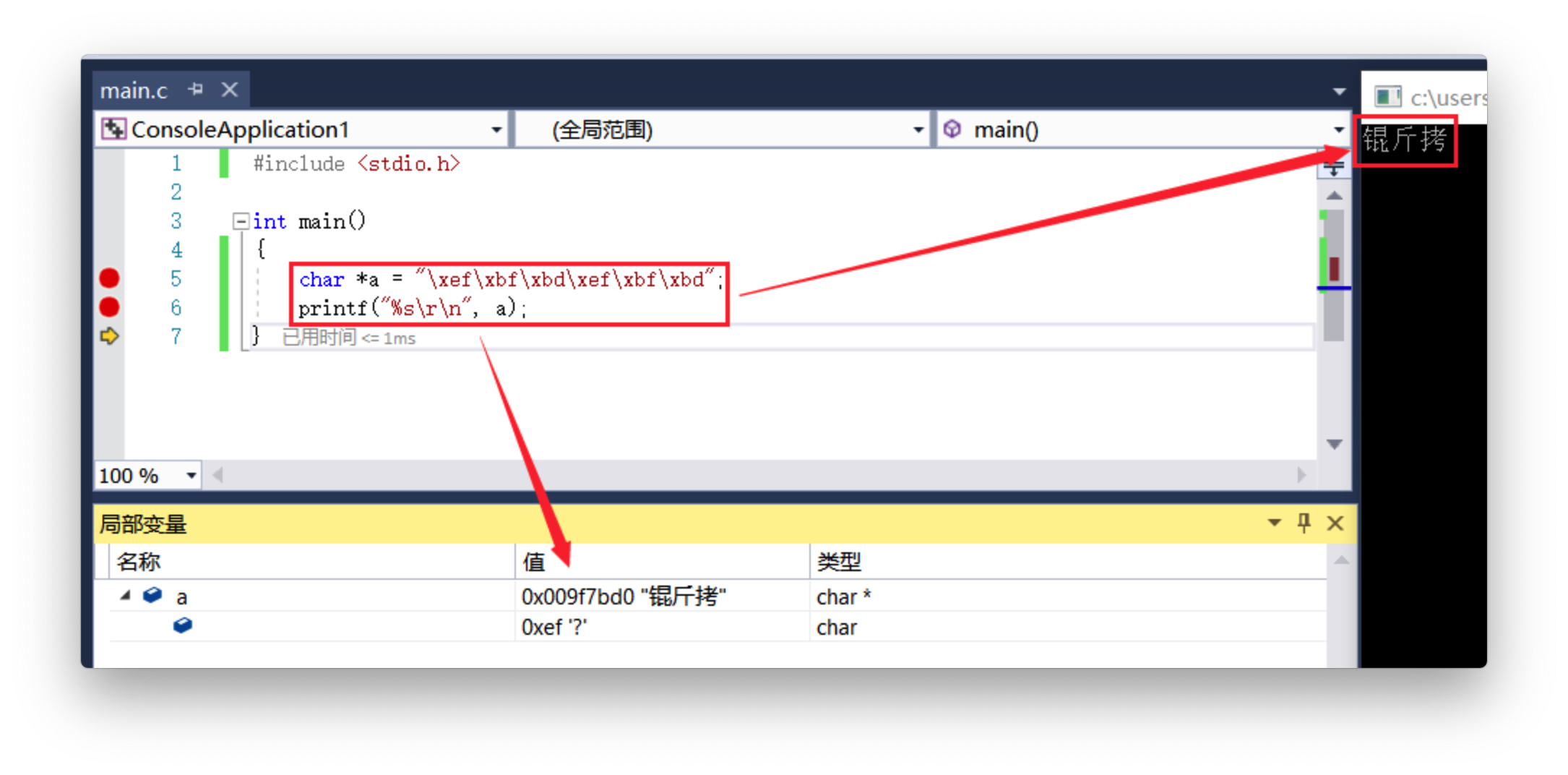
2.3、锟斤拷
锟斤拷涉及Unicode字符集转换问题,在编码转化你的过程中,当Unicode无法表示一个字符的时候,它会用一个占位符(U+FFFD REPLACEMENT CHARACTER)来表示这些文字。U+FFFD的UTF-8编码是0xEFBFBD,如果重复多次形成锟斤拷的盛状。
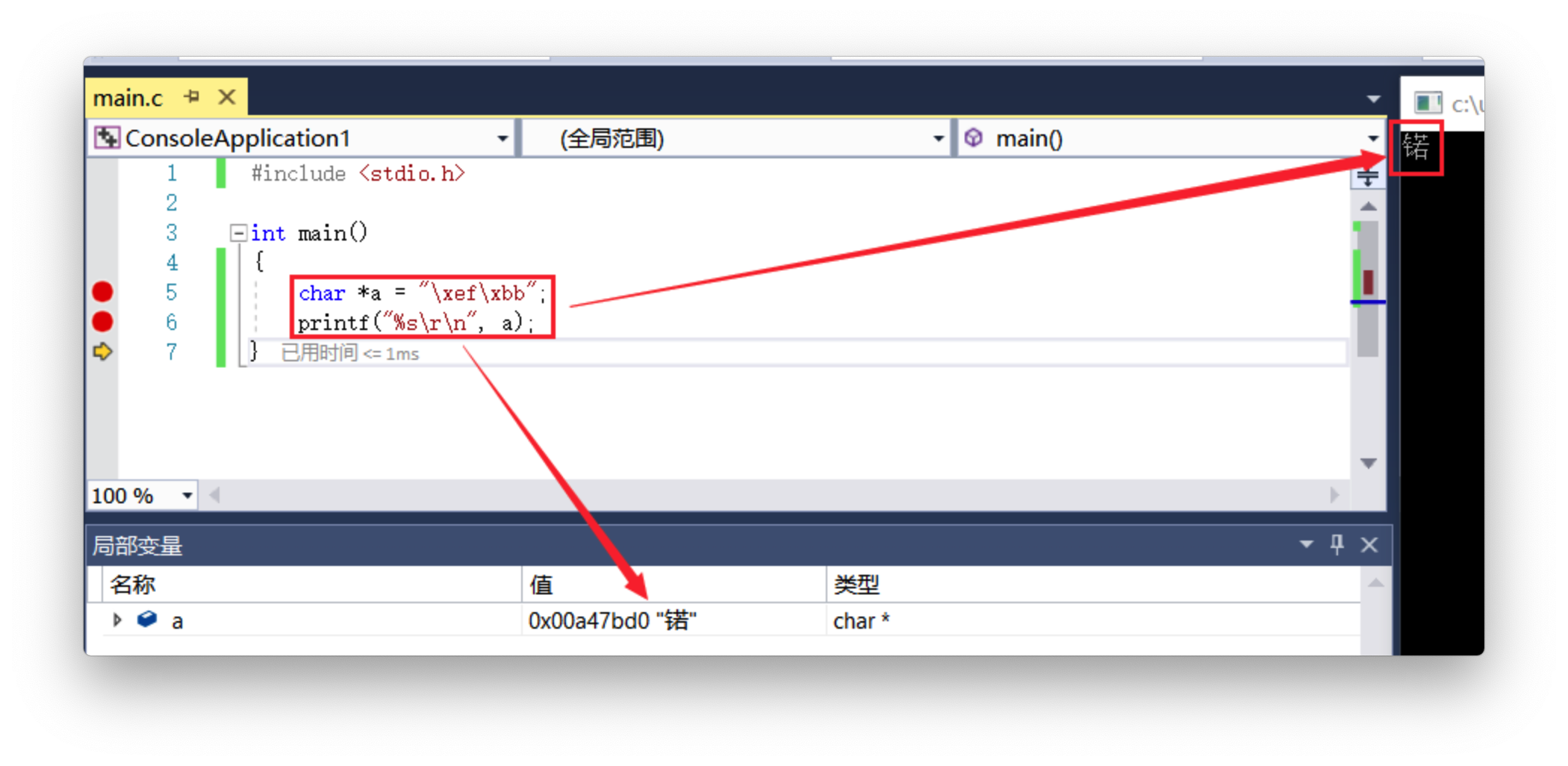
2.4、锘
微软在 UTF-8 文件头部加上了 EF BB BF BOM 标志。在不支持 BOM 的环境下对其停止 UTF-8 解码失掉锘字,
BOM 是 Byte Order Mark 的缩写。是UTF编码方案里用于标识编码的标准标记,在UTF-16里本来是FF FE,变成UTF-8就成了EF BB BF。这个标记是可选的,因为UTF8字节没有顺序,所以它可以被用来检测一个字节流是否是UTF-8编码的。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 咕咕!
相关推荐

2019-01-08
Clang-Format格式化工具
Clang-Format 是基于 clang 的一个命令行工具,这个工具能够自动化格式 C/C++/Obj-C 代码,支持多种代码风格(Google, Chromium, LLVM, Mozilla, WebKit),同时也支持自定义风格(通过编写.clang-format文件),这里记录了常用的配置 Clang-Format 常用的配置项及其含义。 一、安装方式# macbrew install clang-format 二、参数解析官方文档的参数解析为:http://clang.llvm.org/docs/ClangFormatStyleOptions.html 2.1 参数解析BasedOnStyle样式信息: LLVM:一种遵循LLVM coding standards的样式; Google:一种遵循Google’s C++ style guide的样式; Chromium:一种遵循Chromium’s style guide的样式; Mozilla:一种遵循Mozilla’s style guide的样式; WebKit:一种遵循WebKit’s...

2019-01-24
Redis的Memory命令讲解
一、简述Memory指令是Redis4.0版本更新的特性,可用于详细的分析内存的使用情况,内存使用诊断,内存碎片回收等工作; 可以通过memory help指令打印出memory指令的信息,详细信息如下所示: 1) MEMORY <subcommand> arg arg ... arg. Subcommands are:2) DOCTOR - Return memory problems reports.3) MALLOC-STATS -- Return internal statistics report from the memory allocator.4) PURGE -- Attempt to purge dirty pages for reclamation by the allocator.5) STATS -- Return information about the memory usage of the server.6) USAGE <key> [SAMPLES <count>] -- Return memory in b...

2017-01-05
用C#编写的一个IP地址修改器
一、编写初衷:在学校的时候很多时候需要更改自己电脑的IP地址,比如机房课程设计的时候,拔掉机房的网线插到自己电脑上的时候,每次都得配上机房的IP地址,下午下课回去后还得自己更改为自动获取IP地址,很是烦人。之后我曾经用过BAT的方式去修改电脑的IP地址等信息,之前用起来效果也十分不错,但是毕竟添加IP地址等信息还得去编辑BAT,也不是十分方便,对于一些小白用户来说多少也是个麻烦事,并且之前的那个BAT需要手动以管理员方式运行,也比较麻烦,为此打算用C#写一个小程序,方便的来改变电脑的IP地址等信息。 二、软件详细介绍:该IPAddressModifier软件使用Microsoft Visual Studio 2015这款IDE使用C#进行编写,整体上只设计了两个窗体,一个是当前网络适配器详情以及预览预设置IP地址等信息的窗体,还有一个是针对预选IP地址等信息的操作窗体,整体的耗时大概一周左右,其实时间应该是两周左右,因为中间有一些考试,我还需要好好复习一下,所以一共做的时间应该是一周左右,因为本人C#的技能并不是很好,也想把这次当作C#的一次复习,所以就是边查边做了。开始进入界面...

2019-01-01
共享库LD_PRELOAD环境变量分析
一、简介LD_PRELOAD是Linux/Unix系统的一个环境变量,它影响程序的运行时的链接(Runtime linker),它允许在程序运行前定义优先加载的动态链接库。这个功能主要就是用来有选择性的载入不同动态链接库中的相同函数。通过这个环境变量,我们可以在主程序和其动态链接库的中间加载别的动态链接库,甚至覆盖正常的函数库。一方面,我们可以以此功能来使用自己的或是更好的函数(无需别人的源码),而另一方面,我们也可以以向别人的程序注入程序,从而达到特定的目的。 动态库的搜索路径搜索的先后顺序是: 编译目标代码时指定的动态库搜索路径(可指定多个搜索路径,按照先后顺序依次搜索); 环境变量LD_LIBRARY_PATH指定的动态库搜索路径(可指定多个搜索路径,按照先后顺序依次搜索); 配置文件/etc/ld.so.conf中指定的动态库搜索路径(可指定多个搜索路径,按照先后顺序依次搜索); 默认的动态库搜索路径/lib; 默认的动态库搜索路径/usr/lib; 二、模拟实现这里并不是直接替换系统中的函数调用,而是采用添加hook的方式进行; main.c #include ...

2018-11-26
GDB使用笔记
GDB是一个由GNU开源组织发布的、UNIX/LINUX操作系统下的、基于命令行的、功能强大的程序调试工具。 对于一名Linux下工作的c++程序员,gdb是必不可少的工具; 一、 gdb基本指令介绍1.1 gdb交互命令 start:开始调试; n:一条一条的执行; backtrace/bt:查看函数调用栈帧; info/i locals:查看当前栈帧局部变量; frame/f:选择栈帧,在查看局部变量; print/p:打印变量的值; finish:运行到当前函数返回; set var sum=0:修改变量的值; list/l 行号或函数名:列出源码; display/undisplay sum:每次停下显示变量的值/取消跟踪; x/7b input:打印存储器内容,b–每个字节一组,7–7组; disassemble:反汇编当前函数或指定函数; si:一条指令一条指令调试 而 s 是一行一行代码; info registers:显示所有寄存器的当前值; x/20 $esp:查看内存中开始的20个数; run(简写r):其作用...

2019-12-11
Linux下Makefile的生成之路
编译项目的过程中经常会需要执行 make 命令来操作 Makefile 编译命令,但是在有一些项目中是不存在 Makefile 文件的,这时候就需要手动先生成 Makefile 文件,然后在执行编译指令。 一、流程介绍 autoscan:通过扫描源代码来搜寻普通的可移植性问题,比如检查编译器,库,头文件等,生成文件configure.scan,它是configure.ac的一个雏形; aclocal:根据已经安装的宏,用户定义宏和acinclude.m4文件中的宏将configure.ac文件所需要的宏集中定义到文件 aclocal.m4中,aclocal是一个perl 脚本程序,完整定义为:aclocal - create aclocal.m4 by scanning configure.ac; automake:将Makefile.am中定义的结构建立Makefile.in; autoheader:生成了configure.h.in(如果configure.ac中定义了AC_CONFIG_HEADER,那么此文件则必须存在); autoconf:将configure...
评论

